 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Document Retrieval Coherence for Semantically Equivalent Queries
Aug 11, 2025Dense Retrieval (DR) models have proven to be effective for Document Retrieval and Information Grounding tasks. Usually, these models are trained and optimized for improving the relevance of top-ranked documents for a given query. Previous work has shown that popular DR models are sensitive to the query and document lexicon: small variations of it may lead to a significant difference in the set of retrieved documents. In this paper, we propose a variation of the Multi-Negative Ranking loss for training DR that improves the coherence of models in retrieving the same documents with respect to semantically similar queries. The loss penalizes discrepancies between the top-k ranked documents retrieved for diverse but semantic equivalent queries. We conducted extensive experiments on various datasets, MS-MARCO, Natural Questions, BEIR, and TREC DL 19/20. The results show that (i) models optimizes by our loss are subject to lower sensitivity, and, (ii) interestingly, higher accuracy.
Datasets for Multilingual Answer Sentence Selection
Jun 14, 2024



Answer Sentence Selection (AS2) is a critical task for designing effective retrieval-based Question Answering (QA) systems. Most advancements in AS2 focus on English due to the scarcity of annotated datasets for other languages. This lack of resources prevents the training of effective AS2 models in different languages, creating a performance gap between QA systems in English and other locales. In this paper, we introduce new high-quality datasets for AS2 in five European languages (French, German, Italian, Portuguese, and Spanish), obtained through supervised Automatic Machine Translation (AMT) of existing English AS2 datasets such as ASNQ, WikiQA, and TREC-QA using a Large Language Model (LLM). We evaluated our approach and the quality of the translated datasets through multiple experiments with different Transformer architectures. The results indicate that our datasets are pivotal in producing robust and powerful multilingual AS2 models, significantly contributing to closing the performance gap between English and other languages.
QUADRo: Dataset and Models for QUestion-Answer Database Retrieval
Mar 30, 2023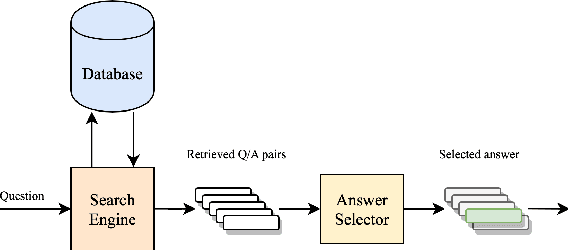
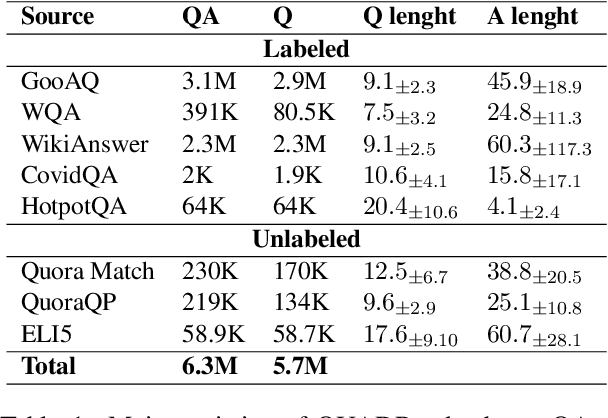
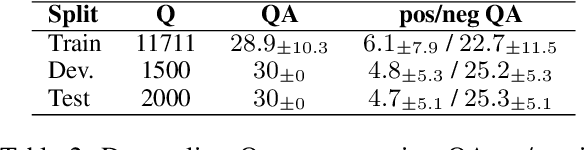
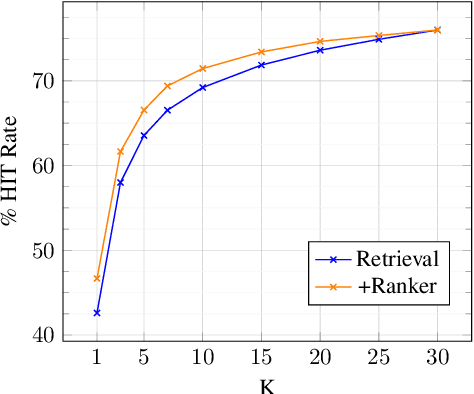
An effective paradigm for building Automated Question Answering systems is the re-use of previously answered questions, e.g., for FAQs or forum applications. Given a database (DB) of question/answer (q/a) pairs, it is possible to answer a target question by scanning the DB for similar questions. In this paper, we scale this approach to open domain, making it competitive with other standard methods, e.g., unstructured document or graph based. For this purpose, we (i) build a large scale DB of 6.3M q/a pairs, using public questions, (ii) design a new system based on neural IR and a q/a pair reranker, and (iii) construct training and test data to perform comparative experiments with our models. We demonstrate that Transformer-based models using (q,a) pairs outperform models only based on question representation, for both neural search and reranking. Additionally, we show that our DB-based approach is competitive with Web-based methods, i.e., a QA system built on top the BING search engine, demonstrating the challenge of finding relevant information. Finally, we make our data and models available for future research.