 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDatasets for Multilingual Answer Sentence Selection
Jun 14, 2024



Answer Sentence Selection (AS2) is a critical task for designing effective retrieval-based Question Answering (QA) systems. Most advancements in AS2 focus on English due to the scarcity of annotated datasets for other languages. This lack of resources prevents the training of effective AS2 models in different languages, creating a performance gap between QA systems in English and other locales. In this paper, we introduce new high-quality datasets for AS2 in five European languages (French, German, Italian, Portuguese, and Spanish), obtained through supervised Automatic Machine Translation (AMT) of existing English AS2 datasets such as ASNQ, WikiQA, and TREC-QA using a Large Language Model (LLM). We evaluated our approach and the quality of the translated datasets through multiple experiments with different Transformer architectures. The results indicate that our datasets are pivotal in producing robust and powerful multilingual AS2 models, significantly contributing to closing the performance gap between English and other languages.
Measuring Retrieval Complexity in Question Answering Systems
Jun 05, 2024In this paper, we investigate which questions are challenging for retrieval-based Question Answering (QA). We (i) propose retrieval complexity (RC), a novel metric conditioned on the completeness of retrieved documents, which measures the difficulty of answering questions, and (ii) propose an unsupervised pipeline to measure RC given an arbitrary retrieval system. Our proposed pipeline measures RC more accurately than alternative estimators, including LLMs, on six challenging QA benchmarks. Further investigation reveals that RC scores strongly correlate with both QA performance and expert judgment across five of the six studied benchmarks, indicating that RC is an effective measure of question difficulty. Subsequent categorization of high-RC questions shows that they span a broad set of question shapes, including multi-hop, compositional, and temporal QA, indicating that RC scores can categorize a new subset of complex questions. Our system can also have a major impact on retrieval-based systems by helping to identify more challenging questions on existing datasets.
SQUARE: Automatic Question Answering Evaluation using Multiple Positive and Negative References
Sep 21, 2023



Evaluation of QA systems is very challenging and expensive, with the most reliable approach being human annotations of correctness of answers for questions. Recent works (AVA, BEM) have shown that transformer LM encoder based similarity metrics transfer well for QA evaluation, but they are limited by the usage of a single correct reference answer. We propose a new evaluation metric: SQuArE (Sentence-level QUestion AnsweRing Evaluation), using multiple reference answers (combining multiple correct and incorrect references) for sentence-form QA. We evaluate SQuArE on both sentence-level extractive (Answer Selection) and generative (GenQA) QA systems, across multiple academic and industrial datasets, and show that it outperforms previous baselines and obtains the highest correlation with human annotations.
Learning Answer Generation using Supervision from Automatic Question Answering Evaluators
May 24, 2023



Recent studies show that sentence-level extractive QA, i.e., based on Answer Sentence Selection (AS2), is outperformed by Generation-based QA (GenQA) models, which generate answers using the top-k answer sentences ranked by AS2 models (a la retrieval-augmented generation style). In this paper, we propose a novel training paradigm for GenQA using supervision from automatic QA evaluation models (GAVA). Specifically, we propose three strategies to transfer knowledge from these QA evaluation models to a GenQA model: (i) augmenting training data with answers generated by the GenQA model and labelled by GAVA (either statically, before training, or (ii) dynamically, at every training epoch); and (iii) using the GAVA score for weighting the generator loss during the learning of the GenQA model. We evaluate our proposed methods on two academic and one industrial dataset, obtaining a significant improvement in answering accuracy over the previous state of the art.
Effective Pre-Training Objectives for Transformer-based Autoencoders
Oct 24, 2022In this paper, we study trade-offs between efficiency, cost and accuracy when pre-training Transformer encoders with different pre-training objectives. For this purpose, we analyze features of common objectives and combine them to create new effective pre-training approaches. Specifically, we designed light token generators based on a straightforward statistical approach, which can replace ELECTRA computationally heavy generators, thus highly reducing cost. Our experiments also show that (i) there are more efficient alternatives to BERT's MLM, and (ii) it is possible to efficiently pre-train Transformer-based models using lighter generators without a significant drop in performance.
Knowledge Transfer from Answer Ranking to Answer Generation
Oct 23, 2022Recent studies show that Question Answering (QA) based on Answer Sentence Selection (AS2) can be improved by generating an improved answer from the top-k ranked answer sentences (termed GenQA). This allows for synthesizing the information from multiple candidates into a concise, natural-sounding answer. However, creating large-scale supervised training data for GenQA models is very challenging. In this paper, we propose to train a GenQA model by transferring knowledge from a trained AS2 model, to overcome the aforementioned issue. First, we use an AS2 model to produce a ranking over answer candidates for a set of questions. Then, we use the top ranked candidate as the generation target, and the next k top ranked candidates as context for training a GenQA model. We also propose to use the AS2 model prediction scores for loss weighting and score-conditioned input/output shaping, to aid the knowledge transfer. Our evaluation on three public and one large industrial datasets demonstrates the superiority of our approach over the AS2 baseline, and GenQA trained using supervised data.
Efficient pre-training objectives for Transformers
Apr 20, 2021


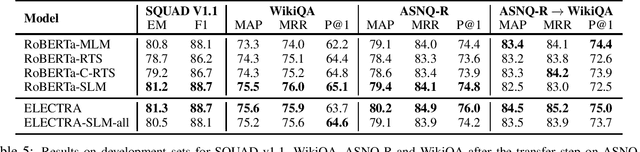
The Transformer architecture deeply changed the natural language processing, outperforming all previous state-of-the-art models. However, well-known Transformer models like BERT, RoBERTa, and GPT-2 require a huge compute budget to create a high quality contextualised representation. In this paper, we study several efficient pre-training objectives for Transformers-based models. By testing these objectives on different tasks, we determine which of the ELECTRA model's new features is the most relevant. We confirm that Transformers pre-training is improved when the input does not contain masked tokens and that the usage of the whole output to compute the loss reduces training time. Moreover, inspired by ELECTRA, we study a model composed of two blocks; a discriminator and a simple generator based on a statistical model with no impact on the computational performances. Besides, we prove that eliminating the MASK token and considering the whole output during the loss computation are essential choices to improve performance. Furthermore, we show that it is possible to efficiently train BERT-like models using a discriminative approach as in ELECTRA but without a complex generator, which is expensive. Finally, we show that ELECTRA benefits heavily from a state-of-the-art hyper-parameters search.