 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving LLM Personas via Rationalization with Psychological Scaffolds
Apr 25, 2025Language models prompted with a user description or persona can predict a user's preferences and opinions, but existing approaches to building personas -- based solely on a user's demographic attributes and/or prior judgments -- fail to capture the underlying reasoning behind said user judgments. We introduce PB&J (Psychology of Behavior and Judgments), a framework that improves LLM personas by incorporating rationales of why a user might make specific judgments. These rationales are LLM-generated, and aim to reason about a user's behavior on the basis of their experiences, personality traits or beliefs. This is done using psychological scaffolds -- structured frameworks grounded in theories such as the Big 5 Personality Traits and Primal World Beliefs -- that help provide structure to the generated rationales. Experiments on public opinion and movie preference prediction tasks demonstrate that LLM personas augmented with PB&J rationales consistently outperform methods using only a user's demographics and/or judgments. Additionally, LLM personas constructed using scaffolds describing user beliefs perform competitively with those using human-written rationales.
Are Language Model Logits Calibrated?
Oct 21, 2024Some information is factual (e.g., "Paris is in France"), whereas other information is probabilistic (e.g., "the coin flip will be a [Heads/Tails]."). We believe that good Language Models (LMs) should understand and reflect this nuance. Our work investigates this by testing if LMs' output probabilities are calibrated to their textual contexts. We define model "calibration" as the degree to which the output probabilities of candidate tokens are aligned with the relative likelihood that should be inferred from the given context. For example, if the context concerns two equally likely options (e.g., heads or tails for a fair coin), the output probabilities should reflect this. Likewise, context that concerns non-uniformly likely events (e.g., rolling a six with a die) should also be appropriately captured with proportionate output probabilities. We find that even in simple settings the best LMs (1) are poorly calibrated, and (2) have systematic biases (e.g., preferred colors and sensitivities to word orderings). For example, gpt-4o-mini often picks the first of two options presented in the prompt regardless of the options' implied likelihood, whereas Llama-3.1-8B picks the second. Our other consistent finding is mode-collapse: Instruction-tuned models often over-allocate probability mass on a single option. These systematic biases introduce non-intuitive model behavior, making models harder for users to understand.
DocFinQA: A Long-Context Financial Reasoning Dataset
Jan 12, 2024
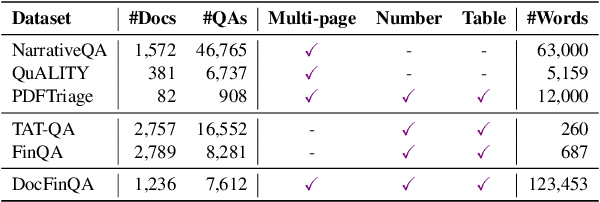


Research in quantitative reasoning within the financial domain indeed necessitates the use of realistic tasks and data, primarily because of the significant impact of decisions made in business and finance. Financial professionals often interact with documents hundreds of pages long, but most research datasets drastically reduce this context length. To address this, we introduce a long-document financial QA task. We augment 7,621 questions from the existing FinQA dataset with full-document context, extending the average context length for each question from under 700 words in FinQA to 123k words in DocFinQA. We conduct extensive experiments of retrieval-based QA pipelines and long-context language models on the augmented data. Our results show that DocFinQA provides challenges for even the strongest, state-of-the-art systems.
BizBench: A Quantitative Reasoning Benchmark for Business and Finance
Nov 11, 2023As large language models (LLMs) impact a growing number of complex domains, it is becoming increasingly important to have fair, accurate, and rigorous evaluation benchmarks. Evaluating the reasoning skills required for business and financial NLP stands out as a particularly difficult challenge. We introduce BizBench, a new benchmark for evaluating models' ability to reason about realistic financial problems. BizBench comprises 8 quantitative reasoning tasks. Notably, BizBench targets the complex task of question-answering (QA) for structured and unstructured financial data via program synthesis (i.e., code generation). We introduce three diverse financially-themed code-generation tasks from newly collected and augmented QA data. Additionally, we isolate distinct financial reasoning capabilities required to solve these QA tasks: reading comprehension of financial text and tables, which is required to extract correct intermediate values; and understanding domain knowledge (e.g., financial formulas) needed to calculate complex solutions. Collectively, these tasks evaluate a model's financial background knowledge, ability to extract numeric entities from financial documents, and capacity to solve problems with code. We conduct an in-depth evaluation of open-source and commercial LLMs, illustrating that BizBench is a challenging benchmark for quantitative reasoning in the finance and business domain.
Learning Answer Generation using Supervision from Automatic Question Answering Evaluators
May 24, 2023



Recent studies show that sentence-level extractive QA, i.e., based on Answer Sentence Selection (AS2), is outperformed by Generation-based QA (GenQA) models, which generate answers using the top-k answer sentences ranked by AS2 models (a la retrieval-augmented generation style). In this paper, we propose a novel training paradigm for GenQA using supervision from automatic QA evaluation models (GAVA). Specifically, we propose three strategies to transfer knowledge from these QA evaluation models to a GenQA model: (i) augmenting training data with answers generated by the GenQA model and labelled by GAVA (either statically, before training, or (ii) dynamically, at every training epoch); and (iii) using the GAVA score for weighting the generator loss during the learning of the GenQA model. We evaluate our proposed methods on two academic and one industrial dataset, obtaining a significant improvement in answering accuracy over the previous state of the art.
Knowledge Transfer from Answer Ranking to Answer Generation
Oct 23, 2022Recent studies show that Question Answering (QA) based on Answer Sentence Selection (AS2) can be improved by generating an improved answer from the top-k ranked answer sentences (termed GenQA). This allows for synthesizing the information from multiple candidates into a concise, natural-sounding answer. However, creating large-scale supervised training data for GenQA models is very challenging. In this paper, we propose to train a GenQA model by transferring knowledge from a trained AS2 model, to overcome the aforementioned issue. First, we use an AS2 model to produce a ranking over answer candidates for a set of questions. Then, we use the top ranked candidate as the generation target, and the next k top ranked candidates as context for training a GenQA model. We also propose to use the AS2 model prediction scores for loss weighting and score-conditioned input/output shaping, to aid the knowledge transfer. Our evaluation on three public and one large industrial datasets demonstrates the superiority of our approach over the AS2 baseline, and GenQA trained using supervised data.
Cross-Lingual GenQA: A Language-Agnostic Generative Question Answering Approach for Open-Domain Question Answering
Oct 14, 2021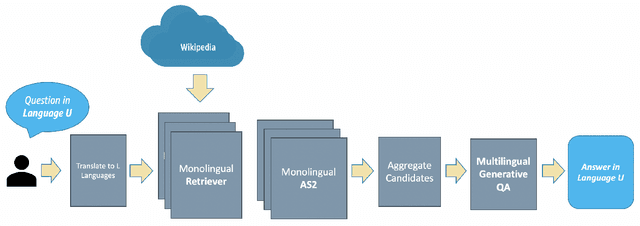



Open-Retrieval Generative Question Answering (GenQA) is proven to deliver high-quality, natural-sounding answers in English. In this paper, we present the first generalization of the GenQA approach for the multilingual environment. To this end, we present the GenTyDiQA dataset, which extends the TyDiQA evaluation data (Clark et al., 2020) with natural-sounding, well-formed answers in Arabic, Bengali, English, Japanese, and Russian. For all these languages, we show that a GenQA sequence-to-sequence-based model outperforms a state-of-the-art Answer Sentence Selection model. We also show that a multilingually-trained model competes with, and in some cases outperforms, its monolingual counterparts. Finally, we show that our system can even compete with strong baselines, even when fed with information from a variety of languages. Essentially, our system is able to answer a question in any language of our language set using information from many languages, making it the first Language-Agnostic GenQA system.
Extracting and Inferring Personal Attributes from Dialogue
Sep 26, 2021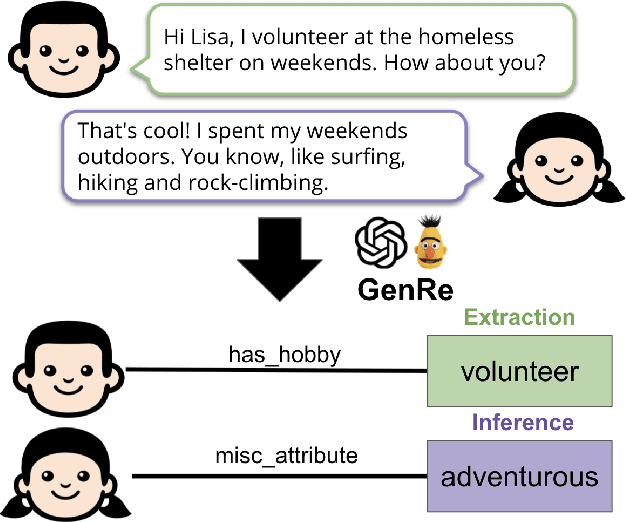


Personal attributes represent structured information about a person, such as their hobbies, pets, family, likes and dislikes. In this work, we introduce the tasks of extracting and inferring personal attributes from human-human dialogue. We first demonstrate the benefit of incorporating personal attributes in a social chit-chat dialogue model and task-oriented dialogue setting. Thus motivated, we propose the tasks of personal attribute extraction and inference, and then analyze the linguistic demands of these tasks. To meet these challenges, we introduce a simple and extensible model that combines an autoregressive language model utilizing constrained attribute generation with a discriminative reranker. Our model outperforms strong baselines on extracting personal attributes as well as inferring personal attributes that are not contained verbatim in utterances and instead requires commonsense reasoning and lexical inferences, which occur frequently in everyday conversation.
Scarecrow: A Framework for Scrutinizing Machine Text
Jul 06, 2021
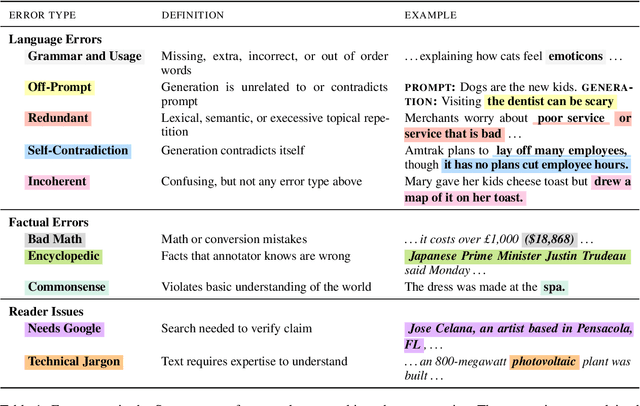
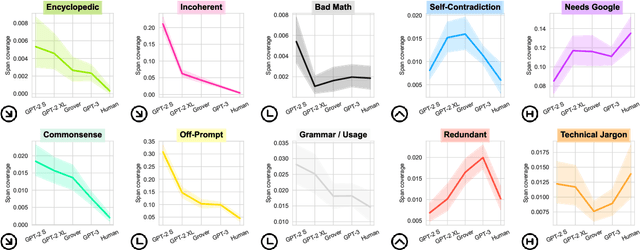
Modern neural text generation systems can produce remarkably fluent and grammatical texts. While earlier language models suffered from repetition and syntactic errors, the errors made by contemporary models are often semantic, narrative, or discourse failures. To facilitate research of these complex error types, we introduce a new structured, crowdsourced error annotation schema called Scarecrow. The error categories used in Scarecrow -- such as redundancy, commonsense errors, and incoherence -- were identified by combining expert analysis with several pilot rounds of ontology-free crowd annotation to arrive at a schema which covers the error phenomena found in real machine generated text. We use Scarecrow to collect 13k annotations of 1.3k human and machine generate paragraphs of English language news text, amounting to over 41k spans each labeled with its error category, severity, a natural language explanation, and antecedent span (where relevant). We collect annotations for text generated by state-of-the-art systems with varying known performance levels, from GPT-2 Small through the largest GPT-3. We isolate several factors for detailed analysis, including parameter count, training data, and decoding technique. Our results show both expected and surprising differences across these settings. These findings demonstrate the value of Scarecrow annotations in the assessment of current and future text generation systems. We release our complete annotation toolkit and dataset at https://yao-dou.github.io/scarecrow/.
Go Forth and Prosper: Language Modeling with Ancient Textual History
Apr 18, 2021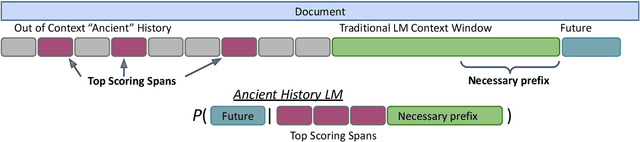

We introduce a technique for improving document-level language models (LM) by leveraging "ancient history": text that is outside the LM's current context window. We learn an auxiliary function to select spans from the ancient history which can help the LM to predict future text. The selected text spans are then copied directly into the LM's context window, replacing less predictive spans. This method can improve perplexity of pretrained LMs with no updates to the LM's own parameters. We further observe that an auxiliary function trained in a specific textual domain like Wikipedia will also work in a substantially different domain such as scientific publications. With this technique we see a 7 percent perplexity reduction on Wikipedia articles, and a 12 percent perplexity reduction on scientific texts.