 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGo Forth and Prosper: Language Modeling with Ancient Textual History
Paper and Code
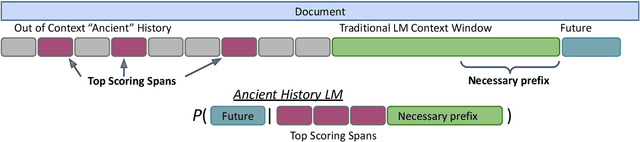

We introduce a technique for improving document-level language models (LM) by leveraging "ancient history": text that is outside the LM's current context window. We learn an auxiliary function to select spans from the ancient history which can help the LM to predict future text. The selected text spans are then copied directly into the LM's context window, replacing less predictive spans. This method can improve perplexity of pretrained LMs with no updates to the LM's own parameters. We further observe that an auxiliary function trained in a specific textual domain like Wikipedia will also work in a substantially different domain such as scientific publications. With this technique we see a 7 percent perplexity reduction on Wikipedia articles, and a 12 percent perplexity reduction on scientific texts.