 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNot How Many, But Which: Parameter Placement in Low-Rank Adaptation
May 12, 2026We study the \textit{parameter placement problem}: given a fixed budget of $k$ trainable entries within the B matrix of a LoRA adapter (A frozen), does the choice of which $k$ matter? Under supervised fine-tuning, random and informed subsets achieve comparable performance. Under GRPO on base models, random placement fails to improve over the base model, while gradient-informed placement recovers standard LoRA accuracy. This regime dependence traces to gradient structure: SFT gradients are low-rank and directionally stable, so any subset accumulates coherent updates; GRPO gradients are high-rank and near-orthogonal across steps, so only elements with consistently signed gradients retain the learning signal. Our scoring procedure identifies these critical parameters in under 10 seconds at less than 0.5% of training cost. Selected parameters concentrate on residual-stream-writing projections (V, O, Down), stable across model families and scales (1.5B - 8B).
Cost-Efficient Estimation of General Abilities Across Benchmarks
Apr 01, 2026Thousands of diverse benchmarks have been developed to measure the quality of large language models (LLMs). Yet prior work has demonstrated that LLM performance is often sufficiently explained by a small set of latent factors, or abilities. This suggests the potential for more efficient and principled benchmarking, but it remains difficult to compare the quality of different methods. Motivated by predictive validity, we argue that the quality of a benchmarking framework should be grounded in how efficiently it enables the prediction of model performance on unseen tasks. To analyze this objective, we collect the "Wide-scale Item Level Dataset" (WILD), a dataset of item-model response pairs, comprising evaluations of 65 models on 109,564 unique items spanning 163 tasks drawn from 27 datasets. This dataset enables the first analysis of how different techniques can predict a model's performance on a large, diverse collection of unseen tasks under different budget constraints. We demonstrate that combining a modified multidimensional item response theory (IRT) model with adaptive item selection driven by optimal experimental design can predict performance on 112 held-out benchmark tasks with a mean absolute error (MAE) of less than 7%, and can do so after observing only 16 items. We further demonstrate that incorporating cost-aware discount factors into our selection criteria can reduce the total tokens needed to reach 7% MAE from 141,000 tokens to only 22,000, an 85% reduction in evaluation cost.
No Free Labels: Limitations of LLM-as-a-Judge Without Human Grounding
Mar 07, 2025LLM-as-a-Judge is a framework that uses an LLM (large language model) to evaluate the quality of natural language text - typically text that is also generated by an LLM. This framework holds great promise due to its relative low-cost, ease of use, and strong correlations with human stylistic preferences. However, LLM Judges have been shown to exhibit biases that can distort their judgments. We evaluate how well LLM Judges can grade whether a given response to a conversational question is correct, an ability crucial to soundly estimating the overall response quality. To do so, we create and publicly release a human-annotated dataset with labels of correctness for 1,200 LLM responses. We source questions from a combination of existing datasets and a novel, challenging benchmark (BFF-Bench) created for this analysis. We demonstrate a strong connection between an LLM's ability to correctly answer a question and grade responses to that question. Although aggregate level statistics might imply a judge has high agreement with human annotators, it will struggle on the subset of questions it could not answer. To address this issue, we recommend a simple solution: provide the judge with a correct, human-written reference answer. We perform an in-depth analysis on how reference quality can affect the performance of an LLM Judge. We show that providing a weaker judge (e.g. Qwen 2.5 7B) with higher quality references reaches better agreement with human annotators than a stronger judge (e.g. GPT-4o) with synthetic references.
Are Language Model Logits Calibrated?
Oct 21, 2024Some information is factual (e.g., "Paris is in France"), whereas other information is probabilistic (e.g., "the coin flip will be a [Heads/Tails]."). We believe that good Language Models (LMs) should understand and reflect this nuance. Our work investigates this by testing if LMs' output probabilities are calibrated to their textual contexts. We define model "calibration" as the degree to which the output probabilities of candidate tokens are aligned with the relative likelihood that should be inferred from the given context. For example, if the context concerns two equally likely options (e.g., heads or tails for a fair coin), the output probabilities should reflect this. Likewise, context that concerns non-uniformly likely events (e.g., rolling a six with a die) should also be appropriately captured with proportionate output probabilities. We find that even in simple settings the best LMs (1) are poorly calibrated, and (2) have systematic biases (e.g., preferred colors and sensitivities to word orderings). For example, gpt-4o-mini often picks the first of two options presented in the prompt regardless of the options' implied likelihood, whereas Llama-3.1-8B picks the second. Our other consistent finding is mode-collapse: Instruction-tuned models often over-allocate probability mass on a single option. These systematic biases introduce non-intuitive model behavior, making models harder for users to understand.
SEC-QA: A Systematic Evaluation Corpus for Financial QA
Jun 20, 2024The financial domain frequently deals with large numbers of long documents that are essential for daily operations. Significant effort is put towards automating financial data analysis. However, a persistent challenge, not limited to the finance domain, is the scarcity of datasets that accurately reflect real-world tasks for model evaluation. Existing datasets are often constrained by size, context, or relevance to practical applications. Moreover, LLMs are currently trained on trillions of tokens of text, limiting access to novel data or documents that models have not encountered during training for unbiased evaluation. We propose SEC-QA, a continuous dataset generation framework with two key features: 1) the semi-automatic generation of Question-Answer (QA) pairs spanning multiple long context financial documents, which better represent real-world financial scenarios; 2) the ability to continually refresh the dataset using the most recent public document collections, not yet ingested by LLMs. Our experiments show that current retrieval augmented generation methods systematically fail to answer these challenging multi-document questions. In response, we introduce a QA system based on program-of-thought that improves the ability to perform complex information retrieval and quantitative reasoning pipelines, thereby increasing QA accuracy.
Lessons from the Trenches on Reproducible Evaluation of Language Models
May 23, 2024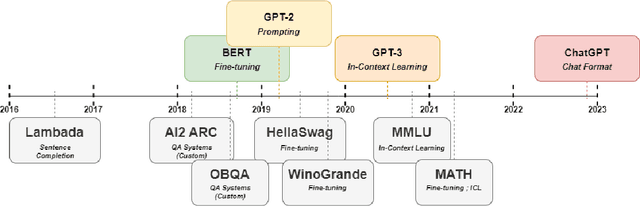
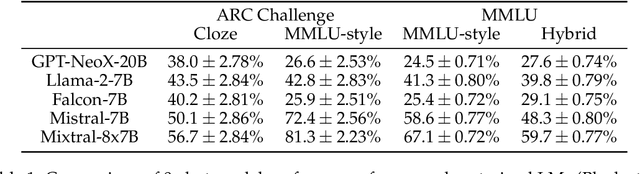
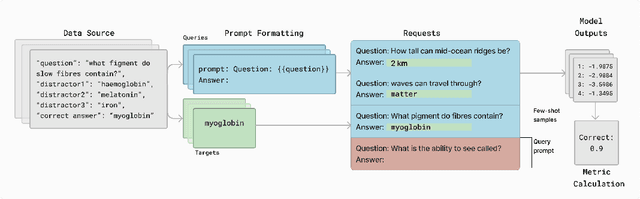

Effective evaluation of language models remains an open challenge in NLP. Researchers and engineers face methodological issues such as the sensitivity of models to evaluation setup, difficulty of proper comparisons across methods, and the lack of reproducibility and transparency. In this paper we draw on three years of experience in evaluating large language models to provide guidance and lessons for researchers. First, we provide an overview of common challenges faced in language model evaluation. Second, we delineate best practices for addressing or lessening the impact of these challenges on research. Third, we present the Language Model Evaluation Harness (lm-eval): an open source library for independent, reproducible, and extensible evaluation of language models that seeks to address these issues. We describe the features of the library as well as case studies in which the library has been used to alleviate these methodological concerns.
BizBench: A Quantitative Reasoning Benchmark for Business and Finance
Nov 11, 2023As large language models (LLMs) impact a growing number of complex domains, it is becoming increasingly important to have fair, accurate, and rigorous evaluation benchmarks. Evaluating the reasoning skills required for business and financial NLP stands out as a particularly difficult challenge. We introduce BizBench, a new benchmark for evaluating models' ability to reason about realistic financial problems. BizBench comprises 8 quantitative reasoning tasks. Notably, BizBench targets the complex task of question-answering (QA) for structured and unstructured financial data via program synthesis (i.e., code generation). We introduce three diverse financially-themed code-generation tasks from newly collected and augmented QA data. Additionally, we isolate distinct financial reasoning capabilities required to solve these QA tasks: reading comprehension of financial text and tables, which is required to extract correct intermediate values; and understanding domain knowledge (e.g., financial formulas) needed to calculate complex solutions. Collectively, these tasks evaluate a model's financial background knowledge, ability to extract numeric entities from financial documents, and capacity to solve problems with code. We conduct an in-depth evaluation of open-source and commercial LLMs, illustrating that BizBench is a challenging benchmark for quantitative reasoning in the finance and business domain.
Deep Neural Networks Can Learn Generalizable Same-Different Visual Relations
Oct 14, 2023



Although deep neural networks can achieve human-level performance on many object recognition benchmarks, prior work suggests that these same models fail to learn simple abstract relations, such as determining whether two objects are the same or different. Much of this prior work focuses on training convolutional neural networks to classify images of two same or two different abstract shapes, testing generalization on within-distribution stimuli. In this article, we comprehensively study whether deep neural networks can acquire and generalize same-different relations both within and out-of-distribution using a variety of architectures, forms of pretraining, and fine-tuning datasets. We find that certain pretrained transformers can learn a same-different relation that generalizes with near perfect accuracy to out-of-distribution stimuli. Furthermore, we find that fine-tuning on abstract shapes that lack texture or color provides the strongest out-of-distribution generalization. Our results suggest that, with the right approach, deep neural networks can learn generalizable same-different visual relations.
Evaluation Beyond Task Performance: Analyzing Concepts in AlphaZero in Hex
Nov 26, 2022AlphaZero, an approach to reinforcement learning that couples neural networks and Monte Carlo tree search (MCTS), has produced state-of-the-art strategies for traditional board games like chess, Go, shogi, and Hex. While researchers and game commentators have suggested that AlphaZero uses concepts that humans consider important, it is unclear how these concepts are captured in the network. We investigate AlphaZero's internal representations in the game of Hex using two evaluation techniques from natural language processing (NLP): model probing and behavioral tests. In doing so, we introduce new evaluation tools to the RL community and illustrate how evaluations other than task performance can be used to provide a more complete picture of a model's strengths and weaknesses. Our analyses in the game of Hex reveal interesting patterns and generate some testable hypotheses about how such models learn in general. For example, we find that MCTS discovers concepts before the neural network learns to encode them. We also find that concepts related to short-term end-game planning are best encoded in the final layers of the model, whereas concepts related to long-term planning are encoded in the middle layers of the model.
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.