 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeH-ARC: A Robust Estimate of Human Performance on the Abstraction and Reasoning Corpus Benchmark
Sep 02, 2024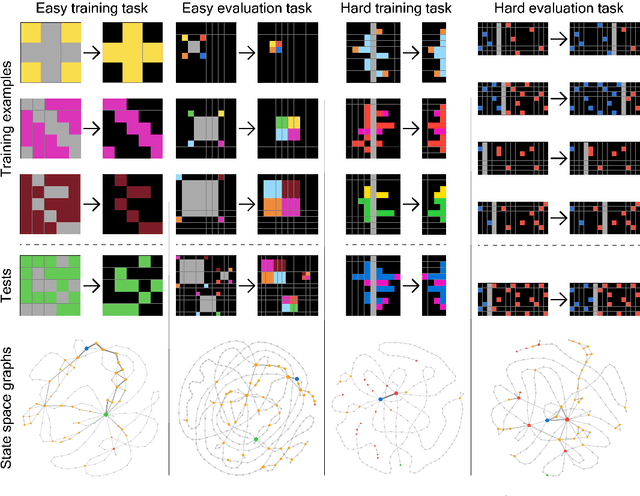
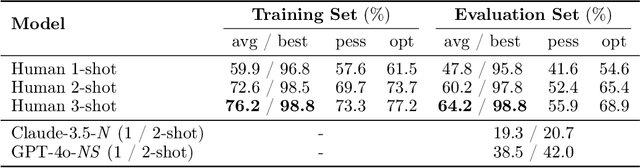
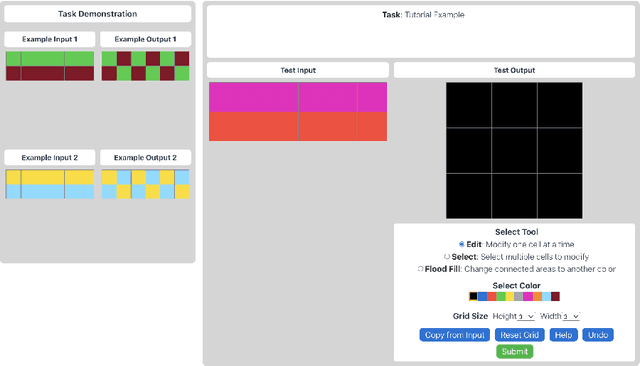
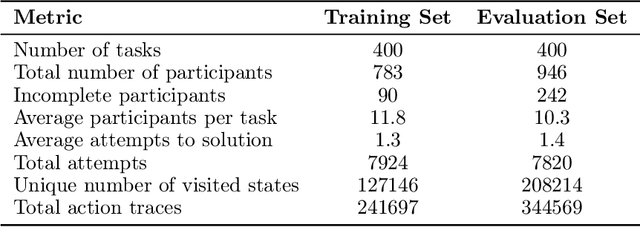
The Abstraction and Reasoning Corpus (ARC) is a visual program synthesis benchmark designed to test challenging out-of-distribution generalization in humans and machines. Since 2019, limited progress has been observed on the challenge using existing artificial intelligence methods. Comparing human and machine performance is important for the validity of the benchmark. While previous work explored how well humans can solve tasks from the ARC benchmark, they either did so using only a subset of tasks from the original dataset, or from variants of ARC, and therefore only provided a tentative estimate of human performance. In this work, we obtain a more robust estimate of human performance by evaluating 1729 humans on the full set of 400 training and 400 evaluation tasks from the original ARC problem set. We estimate that average human performance lies between 73.3% and 77.2% correct with a reported empirical average of 76.2% on the training set, and between 55.9% and 68.9% correct with a reported empirical average of 64.2% on the public evaluation set. However, we also find that 790 out of the 800 tasks were solvable by at least one person in three attempts, suggesting that the vast majority of the publicly available ARC tasks are in principle solvable by typical crowd-workers recruited over the internet. Notably, while these numbers are slightly lower than earlier estimates, human performance still greatly exceeds current state-of-the-art approaches for solving ARC. To facilitate research on ARC, we publicly release our dataset, called H-ARC (human-ARC), which includes all of the submissions and action traces from human participants.
Beyond the Doors of Perception: Vision Transformers Represent Relations Between Objects
Jun 22, 2024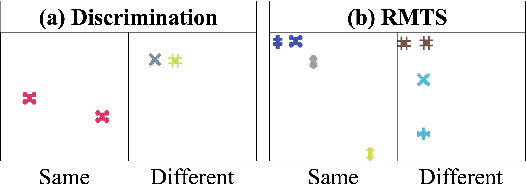
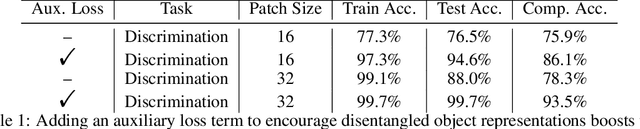
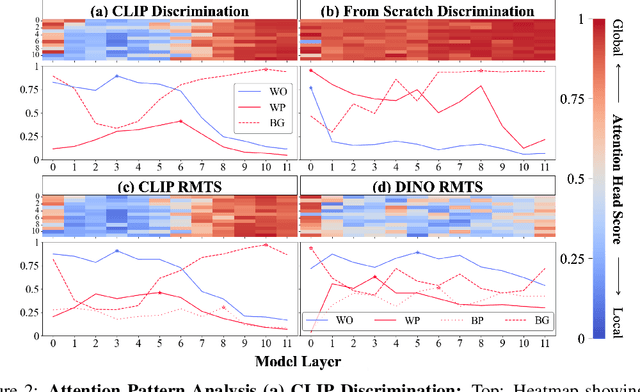
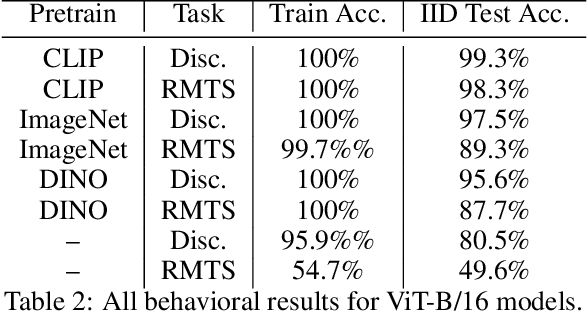
Though vision transformers (ViTs) have achieved state-of-the-art performance in a variety of settings, they exhibit surprising failures when performing tasks involving visual relations. This begs the question: how do ViTs attempt to perform tasks that require computing visual relations between objects? Prior efforts to interpret ViTs tend to focus on characterizing relevant low-level visual features. In contrast, we adopt methods from mechanistic interpretability to study the higher-level visual algorithms that ViTs use to perform abstract visual reasoning. We present a case study of a fundamental, yet surprisingly difficult, relational reasoning task: judging whether two visual entities are the same or different. We find that pretrained ViTs fine-tuned on this task often exhibit two qualitatively different stages of processing despite having no obvious inductive biases to do so: 1) a perceptual stage wherein local object features are extracted and stored in a disentangled representation, and 2) a relational stage wherein object representations are compared. In the second stage, we find evidence that ViTs can learn to represent somewhat abstract visual relations, a capability that has long been considered out of reach for artificial neural networks. Finally, we demonstrate that failure points at either stage can prevent a model from learning a generalizable solution to our fairly simple tasks. By understanding ViTs in terms of discrete processing stages, one can more precisely diagnose and rectify shortcomings of existing and future models.
Deep Neural Networks Can Learn Generalizable Same-Different Visual Relations
Oct 14, 2023



Although deep neural networks can achieve human-level performance on many object recognition benchmarks, prior work suggests that these same models fail to learn simple abstract relations, such as determining whether two objects are the same or different. Much of this prior work focuses on training convolutional neural networks to classify images of two same or two different abstract shapes, testing generalization on within-distribution stimuli. In this article, we comprehensively study whether deep neural networks can acquire and generalize same-different relations both within and out-of-distribution using a variety of architectures, forms of pretraining, and fine-tuning datasets. We find that certain pretrained transformers can learn a same-different relation that generalizes with near perfect accuracy to out-of-distribution stimuli. Furthermore, we find that fine-tuning on abstract shapes that lack texture or color provides the strongest out-of-distribution generalization. Our results suggest that, with the right approach, deep neural networks can learn generalizable same-different visual relations.
Abstract Visual Reasoning with Tangram Shapes
Nov 29, 2022


We introduce KiloGram, a resource for studying abstract visual reasoning in humans and machines. Drawing on the history of tangram puzzles as stimuli in cognitive science, we build a richly annotated dataset that, with >1k distinct stimuli, is orders of magnitude larger and more diverse than prior resources. It is both visually and linguistically richer, moving beyond whole shape descriptions to include segmentation maps and part labels. We use this resource to evaluate the abstract visual reasoning capacities of recent multi-modal models. We observe that pre-trained weights demonstrate limited abstract reasoning, which dramatically improves with fine-tuning. We also observe that explicitly describing parts aids abstract reasoning for both humans and models, especially when jointly encoding the linguistic and visual inputs. KiloGram is available at https://lil.nlp.cornell.edu/kilogram .
A Developmentally-Inspired Examination of Shape versus Texture Bias in Machines
Feb 16, 2022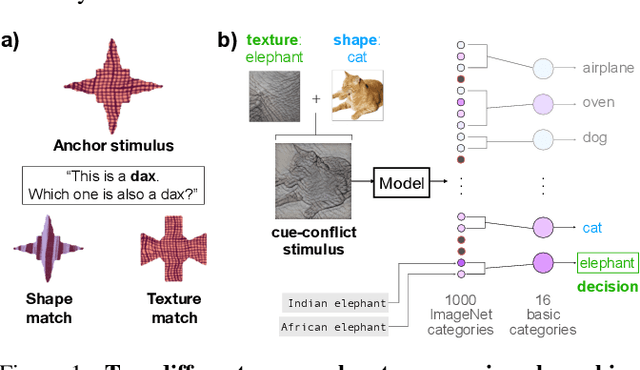
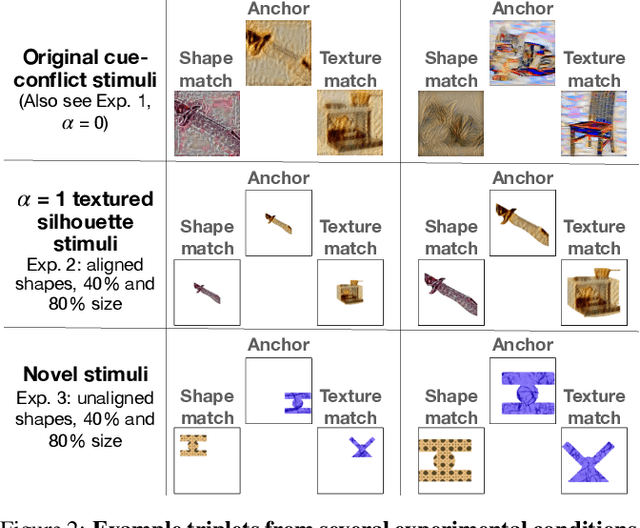
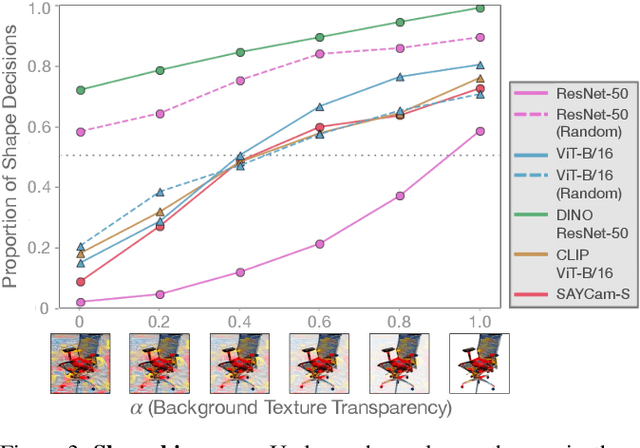
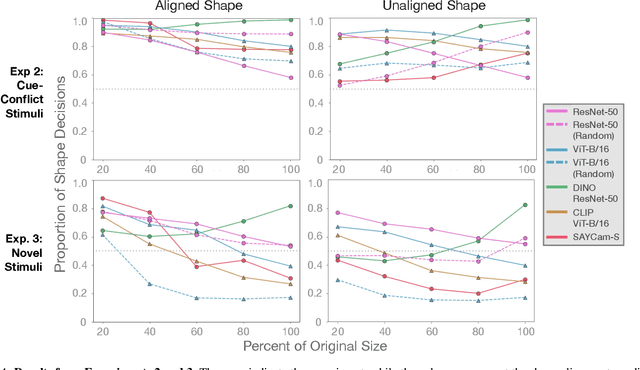
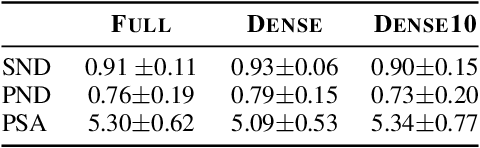
Early in development, children learn to extend novel category labels to objects with the same shape, a phenomenon known as the shape bias. Inspired by these findings, Geirhos et al. (2019) examined whether deep neural networks show a shape or texture bias by constructing images with conflicting shape and texture cues. They found that convolutional neural networks strongly preferred to classify familiar objects based on texture as opposed to shape, suggesting a texture bias. However, there are a number of differences between how the networks were tested in this study versus how children are typically tested. In this work, we re-examine the inductive biases of neural networks by adapting the stimuli and procedure from Geirhos et al. (2019) to more closely follow the developmental paradigm and test on a wide range of pre-trained neural networks. Across three experiments, we find that deep neural networks exhibit a preference for shape rather than texture when tested under conditions that more closely replicate the developmental procedure.
Fast and flexible: Human program induction in abstract reasoning tasks
Mar 10, 2021

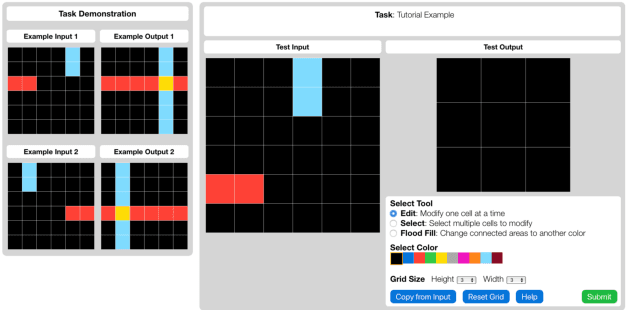
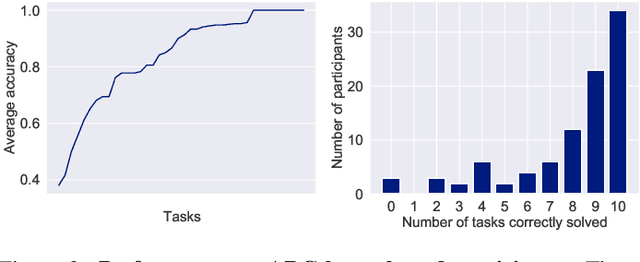
The Abstraction and Reasoning Corpus (ARC) is a challenging program induction dataset that was recently proposed by Chollet (2019). Here, we report the first set of results collected from a behavioral study of humans solving a subset of tasks from ARC (40 out of 1000). Although this subset of tasks contains considerable variation, our results showed that humans were able to infer the underlying program and generate the correct test output for a novel test input example, with an average of 80% of tasks solved per participant, and with 65% of tasks being solved by more than 80% of participants. Additionally, we find interesting patterns of behavioral consistency and variability within the action sequences during the generation process, the natural language descriptions to describe the transformations for each task, and the errors people made. Our findings suggest that people can quickly and reliably determine the relevant features and properties of a task to compose a correct solution. Future modeling work could incorporate these findings, potentially by connecting the natural language descriptions we collected here to the underlying semantics of ARC.
Mitigating belief projection in explainable artificial intelligence via Bayesian Teaching
Feb 07, 2021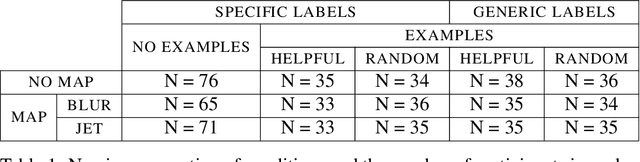

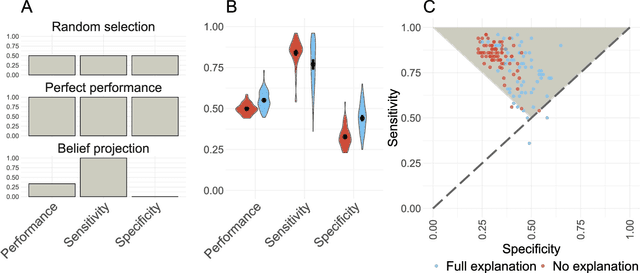
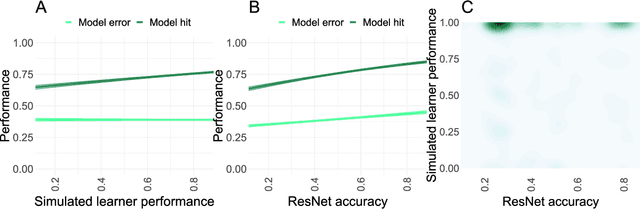
State-of-the-art deep-learning systems use decision rules that are challenging for humans to model. Explainable AI (XAI) attempts to improve human understanding but rarely accounts for how people typically reason about unfamiliar agents. We propose explicitly modeling the human explainee via Bayesian Teaching, which evaluates explanations by how much they shift explainees' inferences toward a desired goal. We assess Bayesian Teaching in a binary image classification task across a variety of contexts. Absent intervention, participants predict that the AI's classifications will match their own, but explanations generated by Bayesian Teaching improve their ability to predict the AI's judgements by moving them away from this prior belief. Bayesian Teaching further allows each case to be broken down into sub-examples (here saliency maps). These sub-examples complement whole examples by improving error detection for familiar categories, whereas whole examples help predict correct AI judgements of unfamiliar cases.
Learning word-referent mappings and concepts from raw inputs
Mar 12, 2020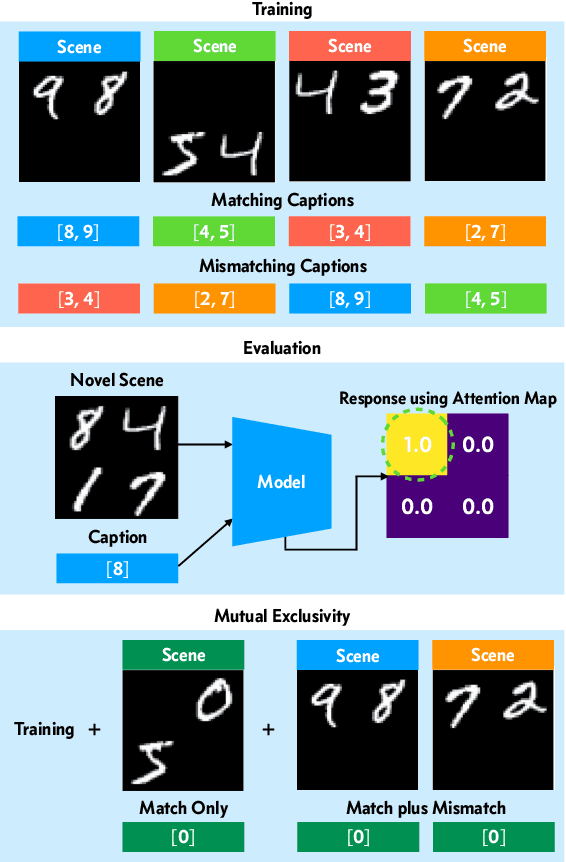
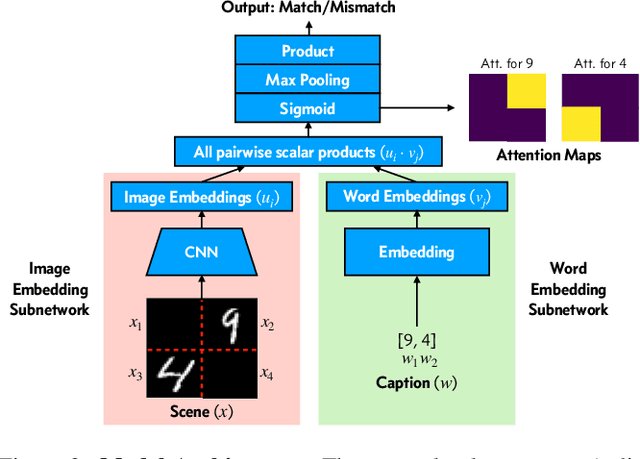
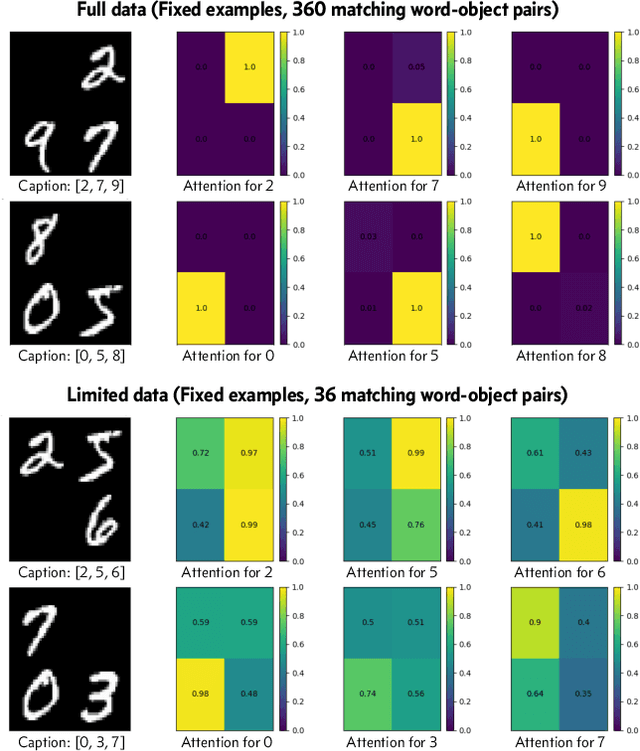
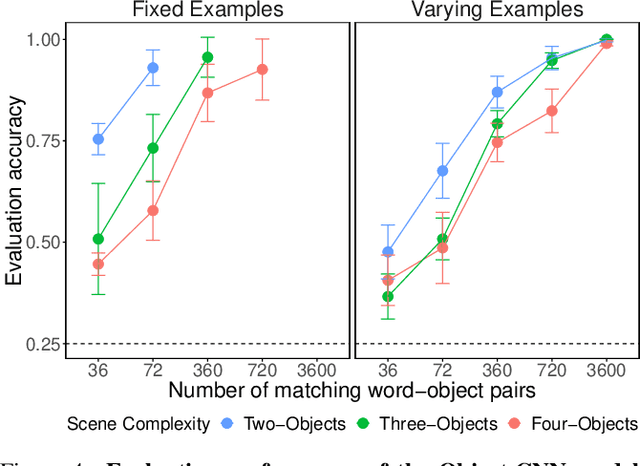
How do children learn correspondences between the language and the world from noisy, ambiguous, naturalistic input? One hypothesis is via cross-situational learning: tracking words and their possible referents across multiple situations allows learners to disambiguate correct word-referent mappings (Yu & Smith, 2007). However, previous models of cross-situational word learning operate on highly simplified representations, side-stepping two important aspects of the actual learning problem. First, how can word-referent mappings be learned from raw inputs such as images? Second, how can these learned mappings generalize to novel instances of a known word? In this paper, we present a neural network model trained from scratch via self-supervision that takes in raw images and words as inputs, and show that it can learn word-referent mappings from fully ambiguous scenes and utterances through cross-situational learning. In addition, the model generalizes to novel word instances, locates referents of words in a scene, and shows a preference for mutual exclusivity.
Optimal Cooperative Inference
Jan 25, 2018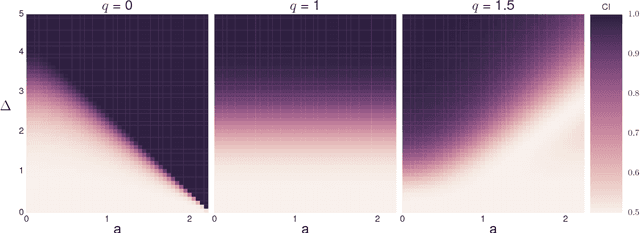
Cooperative transmission of data fosters rapid accumulation of knowledge by efficiently combining experiences across learners. Although well studied in human learning and increasingly in machine learning, we lack formal frameworks through which we may reason about the benefits and limitations of cooperative inference. We present such a framework. We introduce novel indices for measuring the effectiveness of probabilistic and cooperative information transmission. We relate our indices to the well-known Teaching Dimension in deterministic settings. We prove conditions under which optimal cooperative inference can be achieved, including a representation theorem that constrains the form of inductive biases for learners optimized for cooperative inference. We conclude by demonstrating how these principles may inform the design of machine learning algorithms and discuss implications for human and machine learning.