 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGesturing Toward Abstraction: Multimodal Convention Formation in Collaborative Physical Tasks
Feb 09, 2026A quintessential feature of human intelligence is the ability to create ad hoc conventions over time to achieve shared goals efficiently. We investigate how communication strategies evolve through repeated collaboration as people coordinate on shared procedural abstractions. To this end, we conducted an online unimodal study (n = 98) using natural language to probe abstraction hierarchies. In a follow-up lab study (n = 40), we examined how multimodal communication (speech and gestures) changed during physical collaboration. Pairs used augmented reality to isolate their partner's hand and voice; one participant viewed a 3D virtual tower and sent instructions to the other, who built the physical tower. Participants became faster and more accurate by establishing linguistic and gestural abstractions and using cross-modal redundancy to emphasize key changes from previous interactions. Based on these findings, we extend probabilistic models of convention formation to multimodal settings, capturing shifts in modality preferences. Our findings and model provide building blocks for designing convention-aware intelligent agents situated in the physical world.
* Accepted at the 2026 CHI Conference on Human Factors in Computing Systems (CHI 2026). 15 pages
Act or Clarify? Modeling Sensitivity to Uncertainty and Cost in Communication
Feb 02, 2026When deciding how to act under uncertainty, agents may choose to act to reduce uncertainty or they may act despite that uncertainty.In communicative settings, an important way of reducing uncertainty is by asking clarification questions (CQs). We predict that the decision to ask a CQ depends on both contextual uncertainty and the cost of alternative actions, and that these factors interact: uncertainty should matter most when acting incorrectly is costly. We formalize this interaction in a computational model based on expected regret: how much an agent stands to lose by acting now rather than with full information. We test these predictions in two experiments, one examining purely linguistic responses to questions and another extending to choices between clarification and non-linguistic action. Taken together, our results suggest a rational tradeoff: humans tend to seek clarification proportional to the risk of substantial loss when acting under uncertainty.
Accommodation and Epistemic Vigilance: A Pragmatic Account of Why LLMs Fail to Challenge Harmful Beliefs
Jan 07, 2026Large language models (LLMs) frequently fail to challenge users' harmful beliefs in domains ranging from medical advice to social reasoning. We argue that these failures can be understood and addressed pragmatically as consequences of LLMs defaulting to accommodating users' assumptions and exhibiting insufficient epistemic vigilance. We show that social and linguistic factors known to influence accommodation in humans (at-issueness, linguistic encoding, and source reliability) similarly affect accommodation in LLMs, explaining performance differences across three safety benchmarks that test models' ability to challenge harmful beliefs, spanning misinformation (Cancer-Myth, SAGE-Eval) and sycophancy (ELEPHANT). We further show that simple pragmatic interventions, such as adding the phrase "wait a minute", significantly improve performance on these benchmarks while preserving low false-positive rates. Our results highlight the importance of considering pragmatics for evaluating LLM behavior and improving LLM safety.
Minding the Politeness Gap in Cross-cultural Communication
Jun 18, 2025Misunderstandings in cross-cultural communication often arise from subtle differences in interpretation, but it is unclear whether these differences arise from the literal meanings assigned to words or from more general pragmatic factors such as norms around politeness and brevity. In this paper, we report three experiments examining how speakers of British and American English interpret intensifiers like "quite" and "very." To better understand these cross-cultural differences, we developed a computational cognitive model where listeners recursively reason about speakers who balance informativity, politeness, and utterance cost. Our model comparisons suggested that cross-cultural differences in intensifier interpretation stem from a combination of (1) different literal meanings, (2) different weights on utterance cost. These findings challenge accounts based purely on semantic variation or politeness norms, demonstrating that cross-cultural differences in interpretation emerge from an intricate interplay between the two.
Comparing human and LLM politeness strategies in free production
Jun 11, 2025



Polite speech poses a fundamental alignment challenge for large language models (LLMs). Humans deploy a rich repertoire of linguistic strategies to balance informational and social goals -- from positive approaches that build rapport (compliments, expressions of interest) to negative strategies that minimize imposition (hedging, indirectness). We investigate whether LLMs employ a similarly context-sensitive repertoire by comparing human and LLM responses in both constrained and open-ended production tasks. We find that larger models ($\ge$70B parameters) successfully replicate key preferences from the computational pragmatics literature, and human evaluators surprisingly prefer LLM-generated responses in open-ended contexts. However, further linguistic analyses reveal that models disproportionately rely on negative politeness strategies even in positive contexts, potentially leading to misinterpretations. While modern LLMs demonstrate an impressive handle on politeness strategies, these subtle differences raise important questions about pragmatic alignment in AI systems.
Learning a Hierarchical Planner from Humans in Multiple Generations
Oct 17, 2023A typical way in which a machine acquires knowledge from humans is by programming. Compared to learning from demonstrations or experiences, programmatic learning allows the machine to acquire a novel skill as soon as the program is written, and, by building a library of programs, a machine can quickly learn how to perform complex tasks. However, as programs often take their execution contexts for granted, they are brittle when the contexts change, making it difficult to adapt complex programs to new contexts. We present natural programming, a library learning system that combines programmatic learning with a hierarchical planner. Natural programming maintains a library of decompositions, consisting of a goal, a linguistic description of how this goal decompose into sub-goals, and a concrete instance of its decomposition into sub-goals. A user teaches the system via curriculum building, by identifying a challenging yet not impossible goal along with linguistic hints on how this goal may be decomposed into sub-goals. The system solves for the goal via hierarchical planning, using the linguistic hints to guide its probability distribution in proposing the right plans. The system learns from this interaction by adding newly found decompositions in the successful search into its library. Simulated studies and a human experiment (n=360) on a controlled environment demonstrate that natural programming can robustly compose programs learned from different users and contexts, adapting faster and solving more complex tasks when compared to programmatic baselines.
Causal interventions expose implicit situation models for commonsense language understanding
Jun 07, 2023



Accounts of human language processing have long appealed to implicit ``situation models'' that enrich comprehension with relevant but unstated world knowledge. Here, we apply causal intervention techniques to recent transformer models to analyze performance on the Winograd Schema Challenge (WSC), where a single context cue shifts interpretation of an ambiguous pronoun. We identify a relatively small circuit of attention heads that are responsible for propagating information from the context word that guides which of the candidate noun phrases the pronoun ultimately attends to. We then compare how this circuit behaves in a closely matched ``syntactic'' control where the situation model is not strictly necessary. These analyses suggest distinct pathways through which implicit situation models are constructed to guide pronoun resolution.
Overinformative Question Answering by Humans and Machines
May 11, 2023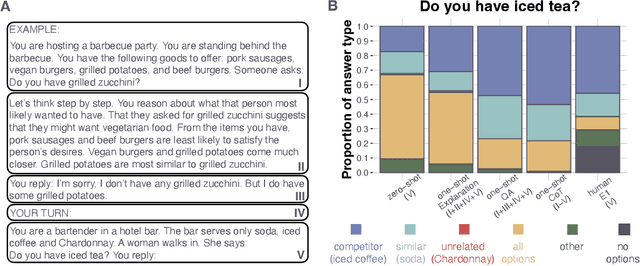


When faced with a polar question, speakers often provide overinformative answers going beyond a simple "yes" or "no". But what principles guide the selection of additional information? In this paper, we provide experimental evidence from two studies suggesting that overinformativeness in human answering is driven by considerations of relevance to the questioner's goals which they flexibly adjust given the functional context in which the question is uttered. We take these human results as a strong benchmark for investigating question-answering performance in state-of-the-art neural language models, conducting an extensive evaluation on items from human experiments. We find that most models fail to adjust their answering behavior in a human-like way and tend to include irrelevant information. We show that GPT-3 is highly sensitive to the form of the prompt and only achieves human-like answer patterns when guided by an example and cognitively-motivated explanation.
Semantic uncertainty guides the extension of conventions to new referents
May 11, 2023

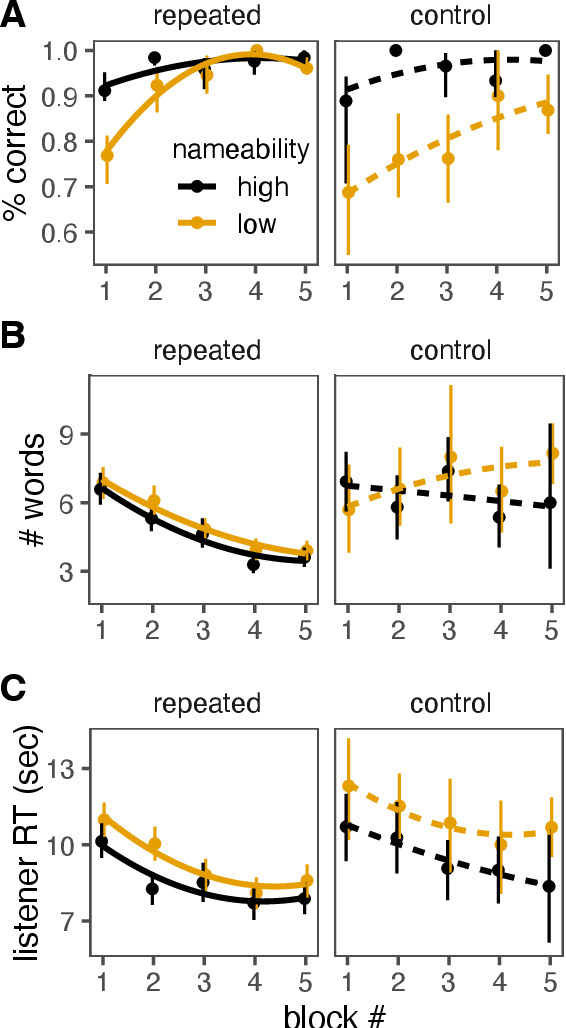

A long tradition of studies in psycholinguistics has examined the formation and generalization of ad hoc conventions in reference games, showing how newly acquired conventions for a given target transfer to new referential contexts. However, another axis of generalization remains understudied: how do conventions formed for one target transfer to completely distinct targets, when specific lexical choices are unlikely to repeat? This paper presents two dyadic studies (N = 240) that address this axis of generalization, focusing on the role of nameability -- the a priori likelihood that two individuals will share the same label. We leverage the recently-released KiloGram dataset, a collection of abstract tangram images that is orders of magnitude larger than previously available, exhibiting high diversity of properties like nameability. Our first study asks how nameability shapes convention formation, while the second asks how new conventions generalize to entirely new targets of reference. Our results raise new questions about how ad hoc conventions extend beyond target-specific re-use of specific lexical choices.
Abstract Visual Reasoning with Tangram Shapes
Nov 29, 2022


We introduce KiloGram, a resource for studying abstract visual reasoning in humans and machines. Drawing on the history of tangram puzzles as stimuli in cognitive science, we build a richly annotated dataset that, with >1k distinct stimuli, is orders of magnitude larger and more diverse than prior resources. It is both visually and linguistically richer, moving beyond whole shape descriptions to include segmentation maps and part labels. We use this resource to evaluate the abstract visual reasoning capacities of recent multi-modal models. We observe that pre-trained weights demonstrate limited abstract reasoning, which dramatically improves with fine-tuning. We also observe that explicitly describing parts aids abstract reasoning for both humans and models, especially when jointly encoding the linguistic and visual inputs. KiloGram is available at https://lil.nlp.cornell.edu/kilogram .