 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal interventions expose implicit situation models for commonsense language understanding
Jun 07, 2023



Accounts of human language processing have long appealed to implicit ``situation models'' that enrich comprehension with relevant but unstated world knowledge. Here, we apply causal intervention techniques to recent transformer models to analyze performance on the Winograd Schema Challenge (WSC), where a single context cue shifts interpretation of an ambiguous pronoun. We identify a relatively small circuit of attention heads that are responsible for propagating information from the context word that guides which of the candidate noun phrases the pronoun ultimately attends to. We then compare how this circuit behaves in a closely matched ``syntactic'' control where the situation model is not strictly necessary. These analyses suggest distinct pathways through which implicit situation models are constructed to guide pronoun resolution.
Probing BERT's priors with serial reproduction chains
Mar 18, 2022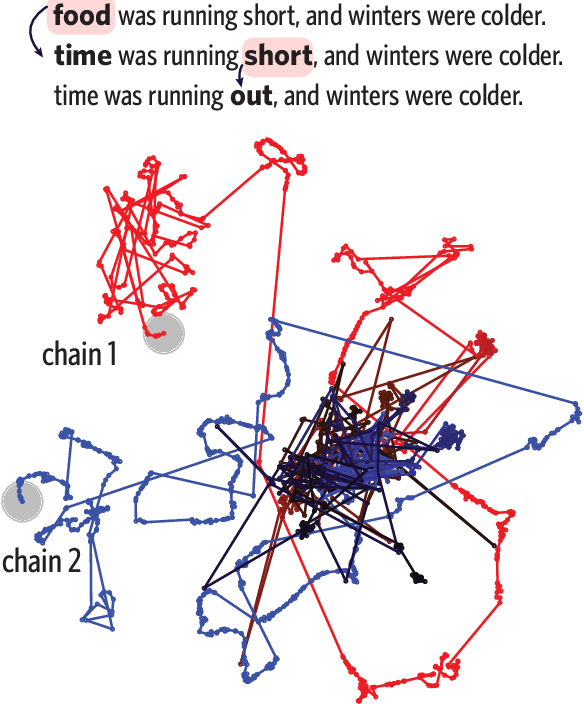

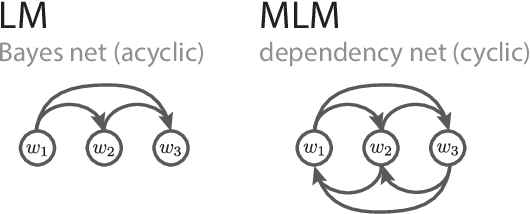
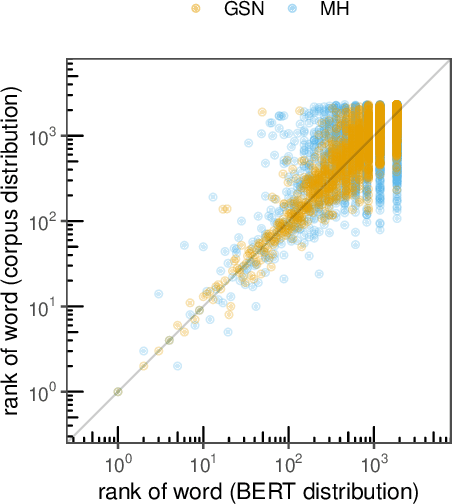
Sampling is a promising bottom-up method for exposing what generative models have learned about language, but it remains unclear how to generate representative samples from popular masked language models (MLMs) like BERT. The MLM objective yields a dependency network with no guarantee of consistent conditional distributions, posing a problem for naive approaches. Drawing from theories of iterated learning in cognitive science, we explore the use of serial reproduction chains to sample from BERT's priors. In particular, we observe that a unique and consistent estimator of the ground-truth joint distribution is given by a Generative Stochastic Network (GSN) sampler, which randomly selects which token to mask and reconstruct on each step. We show that the lexical and syntactic statistics of sentences from GSN chains closely match the ground-truth corpus distribution and perform better than other methods in a large corpus of naturalness judgments. Our findings establish a firmer theoretical foundation for bottom-up probing and highlight richer deviations from human priors.
Investigating representations of verb bias in neural language models
Oct 15, 2020
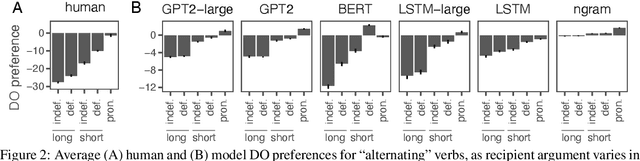
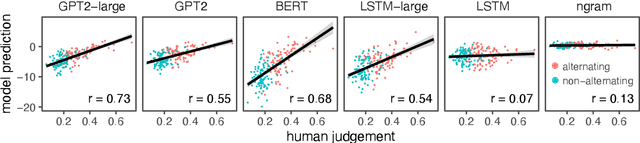
Languages typically provide more than one grammatical construction to express certain types of messages. A speaker's choice of construction is known to depend on multiple factors, including the choice of main verb -- a phenomenon known as \emph{verb bias}. Here we introduce DAIS, a large benchmark dataset containing 50K human judgments for 5K distinct sentence pairs in the English dative alternation. This dataset includes 200 unique verbs and systematically varies the definiteness and length of arguments. We use this dataset, as well as an existing corpus of naturally occurring data, to evaluate how well recent neural language models capture human preferences. Results show that larger models perform better than smaller models, and transformer architectures (e.g. GPT-2) tend to out-perform recurrent architectures (e.g. LSTMs) even under comparable parameter and training settings. Additional analyses of internal feature representations suggest that transformers may better integrate specific lexical information with grammatical constructions.