 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParallelograms Strike Back: LLMs Generate Better Analogies than People
Mar 19, 2026Four-term word analogies (A:B::C:D) are classically modeled geometrically as ''parallelograms,'' yet recent work suggests this model poorly captures how humans produce analogies, with simple local-similarity heuristics often providing a better account (Peterson et al., 2020). But does the parallelogram model fail because it is a bad model of analogical relations, or because people are not very good at generating relation-preserving analogies? We compared human and large language model (LLM) analogy completions on the same set of analogy problems from (Peterson et al., 2020). We find that LLM-generated analogies are reliably judged as better than human-generated ones, and are also more closely aligned with the parallelogram structure in a distributional embedding space (GloVe). Crucially, we show that the improvement over human analogies was driven by greater parallelogram alignment and reduced reliance on accessible words rather than enhanced sensitivity to local similarity. Moreover, the LLM advantage is driven not by uniformly superior responses by LLMs, but by humans producing a long tail of weak completions: when only modal (most frequent) responses by both systems are compared, the LLM advantage disappears. However, greater parallelogram alignment and lower word frequency continue to predict which LLM completions are rated higher than those of humans. Overall, these results suggest that the parallelogram model is not a poor account of word analogy. Rather, humans may often fail to produce completions that satisfy this relational constraint, whereas LLMs do so more consistently.
For GPT-4 as with Humans: Information Structure Predicts Acceptability of Long-Distance Dependencies
May 13, 2025It remains debated how well any LM understands natural language or generates reliable metalinguistic judgments. Moreover, relatively little work has demonstrated that LMs can represent and respect subtle relationships between form and function proposed by linguists. We here focus on a particular such relationship established in recent work: English speakers' judgments about the information structure of canonical sentences predicts independently collected acceptability ratings on corresponding 'long distance dependency' [LDD] constructions, across a wide array of base constructions and multiple types of LDDs. To determine whether any LM captures this relationship, we probe GPT-4 on the same tasks used with humans and new extensions.Results reveal reliable metalinguistic skill on the information structure and acceptability tasks, replicating a striking interaction between the two, despite the zero-shot, explicit nature of the tasks, and little to no chance of contamination [Studies 1a, 1b]. Study 2 manipulates the information structure of base sentences and confirms a causal relationship: increasing the prominence of a constituent in a context sentence increases the subsequent acceptability ratings on an LDD construction. The findings suggest a tight relationship between natural and GPT-4 generated English, and between information structure and syntax, which begs for further exploration.
Causal interventions expose implicit situation models for commonsense language understanding
Jun 07, 2023



Accounts of human language processing have long appealed to implicit ``situation models'' that enrich comprehension with relevant but unstated world knowledge. Here, we apply causal intervention techniques to recent transformer models to analyze performance on the Winograd Schema Challenge (WSC), where a single context cue shifts interpretation of an ambiguous pronoun. We identify a relatively small circuit of attention heads that are responsible for propagating information from the context word that guides which of the candidate noun phrases the pronoun ultimately attends to. We then compare how this circuit behaves in a closely matched ``syntactic'' control where the situation model is not strictly necessary. These analyses suggest distinct pathways through which implicit situation models are constructed to guide pronoun resolution.
Investigating representations of verb bias in neural language models
Oct 15, 2020
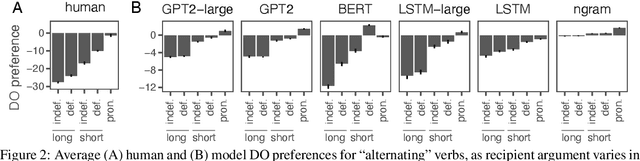
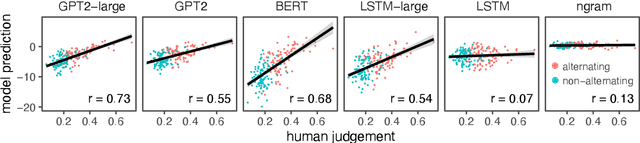
Languages typically provide more than one grammatical construction to express certain types of messages. A speaker's choice of construction is known to depend on multiple factors, including the choice of main verb -- a phenomenon known as \emph{verb bias}. Here we introduce DAIS, a large benchmark dataset containing 50K human judgments for 5K distinct sentence pairs in the English dative alternation. This dataset includes 200 unique verbs and systematically varies the definiteness and length of arguments. We use this dataset, as well as an existing corpus of naturally occurring data, to evaluate how well recent neural language models capture human preferences. Results show that larger models perform better than smaller models, and transformer architectures (e.g. GPT-2) tend to out-perform recurrent architectures (e.g. LSTMs) even under comparable parameter and training settings. Additional analyses of internal feature representations suggest that transformers may better integrate specific lexical information with grammatical constructions.
Generalizing meanings from partners to populations: Hierarchical inference supports convention formation on networks
Feb 04, 2020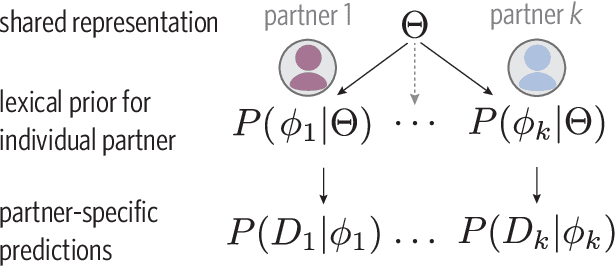
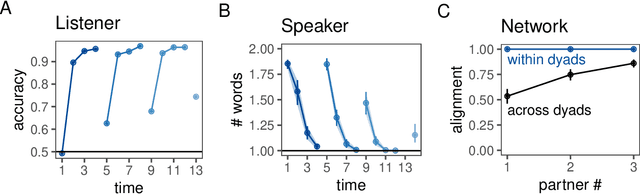
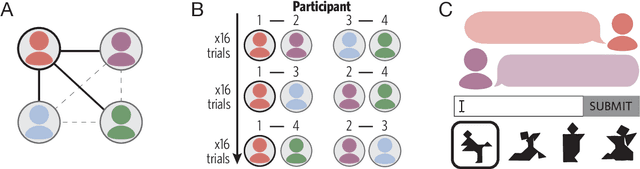
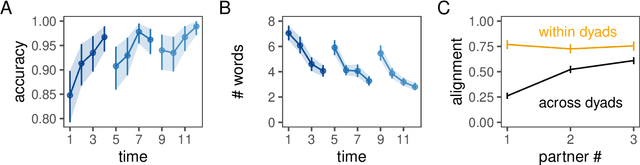
A key property of linguistic conventions is that they hold over an entire community of speakers, allowing us to communicate efficiently even with people we have never met before. At the same time, much of our language use is partner-specific: we know that words may be understood differently by different people based on local common ground. This poses a challenge for accounts of convention formation. Exactly how do agents make the inferential leap to community-wide expectations while maintaining partner-specific knowledge? We propose a hierarchical Bayesian model of convention to explain how speakers and listeners abstract away meanings that seem to be shared across partners. To evaluate our model's predictions, we conducted an experiment where participants played an extended natural-language communication game with different partners in a small community. We examine several measures of generalization across partners, and find key signatures of local adaptation as well as collective convergence. These results suggest that local partner-specific learning is not only compatible with global convention formation but may facilitate it when coupled with a powerful hierarchical inductive mechanism.