 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbing BERT's priors with serial reproduction chains
Paper and Code
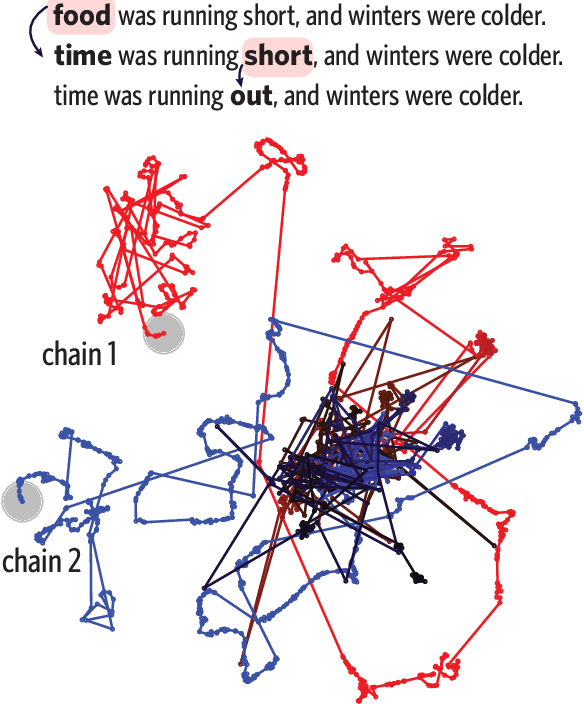

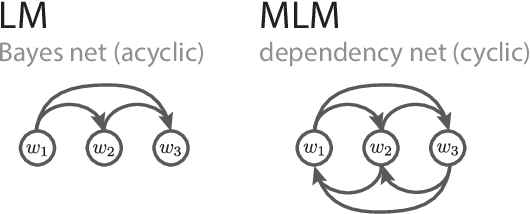
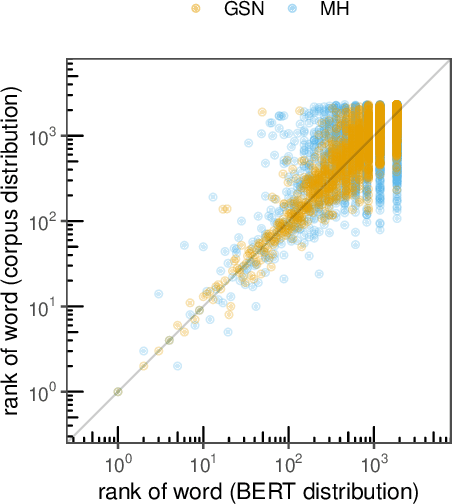
Sampling is a promising bottom-up method for exposing what generative models have learned about language, but it remains unclear how to generate representative samples from popular masked language models (MLMs) like BERT. The MLM objective yields a dependency network with no guarantee of consistent conditional distributions, posing a problem for naive approaches. Drawing from theories of iterated learning in cognitive science, we explore the use of serial reproduction chains to sample from BERT's priors. In particular, we observe that a unique and consistent estimator of the ground-truth joint distribution is given by a Generative Stochastic Network (GSN) sampler, which randomly selects which token to mask and reconstruct on each step. We show that the lexical and syntactic statistics of sentences from GSN chains closely match the ground-truth corpus distribution and perform better than other methods in a large corpus of naturalness judgments. Our findings establish a firmer theoretical foundation for bottom-up probing and highlight richer deviations from human priors.