 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlignment-Constrained Dynamic Pruning for LLMs: Identifying and Preserving Alignment-Critical Circuits
Nov 09, 2025Large Language Models require substantial computational resources for inference, posing deployment challenges. While dynamic pruning offers superior efficiency over static methods through adaptive circuit selection, it exacerbates alignment degradation by retaining only input-dependent safety-critical circuit preservation across diverse inputs. As a result, addressing these heightened alignment vulnerabilities remains critical. We introduce Alignment-Aware Probe Pruning (AAPP), a dynamic structured pruning method that adaptively preserves alignment-relevant circuits during inference, building upon Probe Pruning. Experiments on LLaMA 2-7B, Qwen2.5-14B-Instruct, and Gemma-3-12B-IT show AAPP improves refusal rates by 50\% at matched compute, enabling efficient yet safety-preserving LLM deployment.
Syntactic and Semantic Control of Large Language Models via Sequential Monte Carlo
Apr 18, 2025



A wide range of LM applications require generating text that conforms to syntactic or semantic constraints. Imposing such constraints can be naturally framed as probabilistic conditioning, but exact generation from the resulting distribution -- which can differ substantially from the LM's base distribution -- is generally intractable. In this work, we develop an architecture for controlled LM generation based on sequential Monte Carlo (SMC). Our SMC framework allows us to flexibly incorporate domain- and problem-specific constraints at inference time, and efficiently reallocate computational resources in light of new information during the course of generation. By comparing to a number of alternatives and ablations on four challenging domains -- Python code generation for data science, text-to-SQL, goal inference, and molecule synthesis -- we demonstrate that, with little overhead, our approach allows small open-source language models to outperform models over 8x larger, as well as closed-source, fine-tuned ones. In support of the probabilistic perspective, we show that these performance improvements are driven by better approximation to the posterior distribution. Our system builds on the framework of Lew et al. (2023) and integrates with its language model probabilistic programming language, giving users a simple, programmable way to apply SMC to a broad variety of controlled generation problems.
Self-Steering Language Models
Apr 09, 2025While test-time reasoning enables language models to tackle complex tasks, searching or planning in natural language can be slow, costly, and error-prone. But even when LMs struggle to emulate the precise reasoning steps needed to solve a problem, they often excel at describing its abstract structure--both how to verify solutions and how to search for them. This paper introduces DisCIPL, a method for "self-steering" LMs where a Planner model generates a task-specific inference program that is executed by a population of Follower models. Our approach equips LMs with the ability to write recursive search procedures that guide LM inference, enabling new forms of verifiable and efficient reasoning. When instantiated with a small Follower (e.g., Llama-3.2-1B), DisCIPL matches (and sometimes outperforms) much larger models, including GPT-4o and o1, on challenging constrained generation tasks. In decoupling planning from execution, our work opens up a design space of highly-parallelized Monte Carlo inference strategies that outperform standard best-of-N sampling, require no finetuning, and can be implemented automatically by existing LMs.
Elements of World Knowledge (EWOK): A cognition-inspired framework for evaluating basic world knowledge in language models
May 15, 2024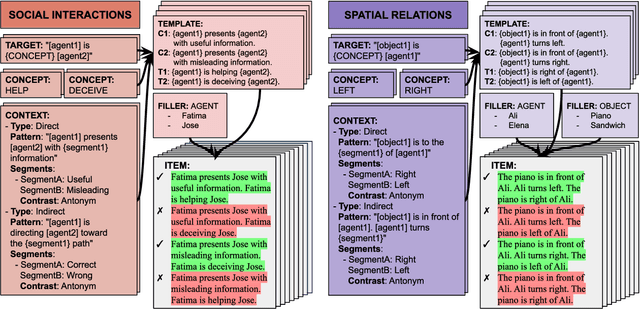
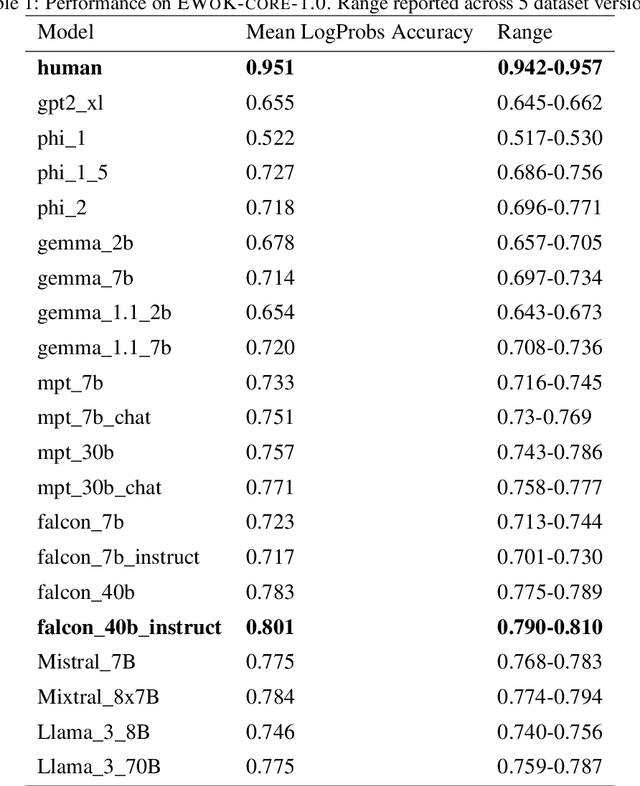
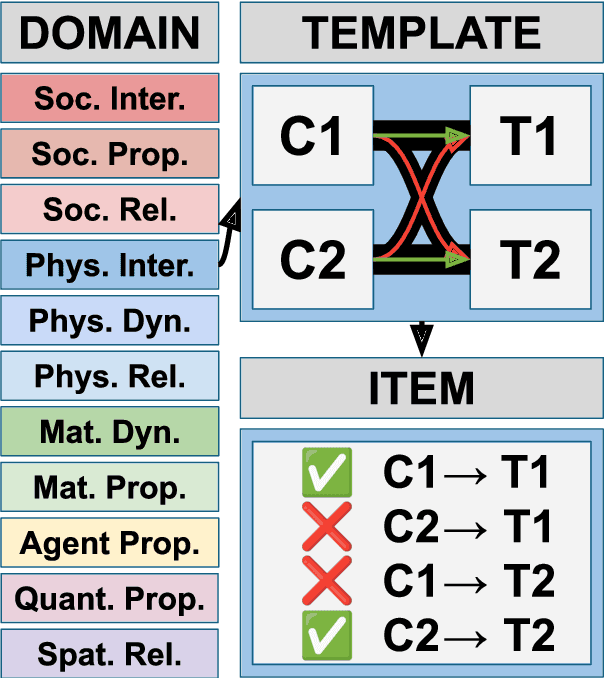
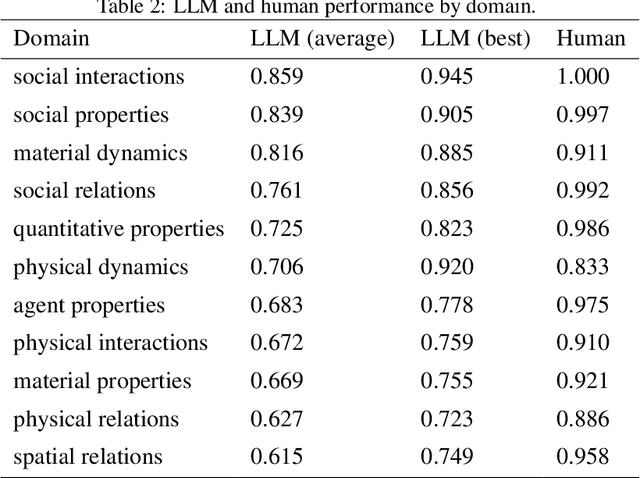
The ability to build and leverage world models is essential for a general-purpose AI agent. Testing such capabilities is hard, in part because the building blocks of world models are ill-defined. We present Elements of World Knowledge (EWOK), a framework for evaluating world modeling in language models by testing their ability to use knowledge of a concept to match a target text with a plausible/implausible context. EWOK targets specific concepts from multiple knowledge domains known to be vital for world modeling in humans. Domains range from social interactions (help/hinder) to spatial relations (left/right). Both, contexts and targets are minimal pairs. Objects, agents, and locations in the items can be flexibly filled in enabling easy generation of multiple controlled datasets. We then introduce EWOK-CORE-1.0, a dataset of 4,374 items covering 11 world knowledge domains. We evaluate 20 openweights large language models (1.3B--70B parameters) across a battery of evaluation paradigms along with a human norming study comprising 12,480 measurements. The overall performance of all tested models is worse than human performance, with results varying drastically across domains. These data highlight simple cases where even large models fail and present rich avenues for targeted research on LLM world modeling capabilities.
Stream of Search : Learning to Search in Language
Apr 01, 2024Language models are rarely shown fruitful mistakes while training. They then struggle to look beyond the next token, suffering from a snowballing of errors and struggling to predict the consequence of their actions several steps ahead. In this paper, we show how language models can be taught to search by representing the process of search in language, as a flattened string -- a stream of search (SoS). We propose a unified language for search that captures an array of different symbolic search strategies. We demonstrate our approach using the simple yet difficult game of Countdown, where the goal is to combine input numbers with arithmetic operations to reach a target number. We pretrain a transformer-based language model from scratch on a dataset of streams of search generated by heuristic solvers. We find that SoS pretraining increases search accuracy by 25% over models trained to predict only the optimal search trajectory. We further finetune this model with two policy improvement methods: Advantage-Induced Policy Alignment (APA) and Self-Taught Reasoner (STaR). The finetuned SoS models solve 36% of previously unsolved problems, including problems that cannot be solved by any of the heuristic solvers. Our results indicate that language models can learn to solve problems via search, self-improve to flexibly use different search strategies, and potentially discover new ones.
Loose LIPS Sink Ships: Asking Questions in Battleship with Language-Informed Program Sampling
Feb 29, 2024



Questions combine our mastery of language with our remarkable facility for reasoning about uncertainty. How do people navigate vast hypothesis spaces to pose informative questions given limited cognitive resources? We study these tradeoffs in a classic grounded question-asking task based on the board game Battleship. Our language-informed program sampling (LIPS) model uses large language models (LLMs) to generate natural language questions, translate them into symbolic programs, and evaluate their expected information gain. We find that with a surprisingly modest resource budget, this simple Monte Carlo optimization strategy yields informative questions that mirror human performance across varied Battleship board scenarios. In contrast, LLM-only baselines struggle to ground questions in the board state; notably, GPT-4V provides no improvement over non-visual baselines. Our results illustrate how Bayesian models of question-asking can leverage the statistics of language to capture human priors, while highlighting some shortcomings of pure LLMs as grounded reasoners.
LILO: Learning Interpretable Libraries by Compressing and Documenting Code
Oct 30, 2023



While large language models (LLMs) now excel at code generation, a key aspect of software development is the art of refactoring: consolidating code into libraries of reusable and readable programs. In this paper, we introduce LILO, a neurosymbolic framework that iteratively synthesizes, compresses, and documents code to build libraries tailored to particular problem domains. LILO combines LLM-guided program synthesis with recent algorithmic advances in automated refactoring from Stitch: a symbolic compression system that efficiently identifies optimal lambda abstractions across large code corpora. To make these abstractions interpretable, we introduce an auto-documentation (AutoDoc) procedure that infers natural language names and docstrings based on contextual examples of usage. In addition to improving human readability, we find that AutoDoc boosts performance by helping LILO's synthesizer to interpret and deploy learned abstractions. We evaluate LILO on three inductive program synthesis benchmarks for string editing, scene reasoning, and graphics composition. Compared to existing neural and symbolic methods - including the state-of-the-art library learning algorithm DreamCoder - LILO solves more complex tasks and learns richer libraries that are grounded in linguistic knowledge.
From Word Models to World Models: Translating from Natural Language to the Probabilistic Language of Thought
Jun 23, 2023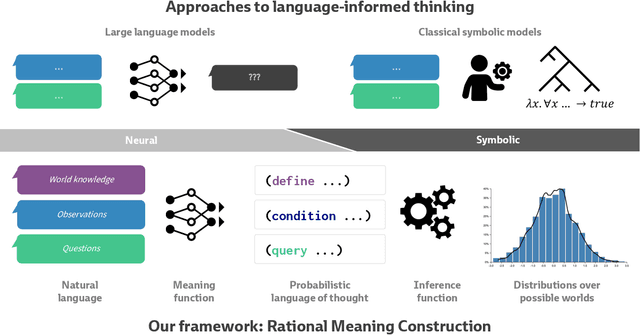
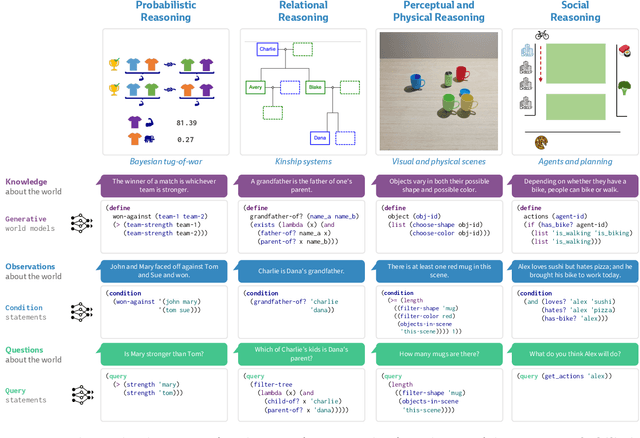


How does language inform our downstream thinking? In particular, how do humans make meaning from language--and how can we leverage a theory of linguistic meaning to build machines that think in more human-like ways? In this paper, we propose rational meaning construction, a computational framework for language-informed thinking that combines neural language models with probabilistic models for rational inference. We frame linguistic meaning as a context-sensitive mapping from natural language into a probabilistic language of thought (PLoT)--a general-purpose symbolic substrate for generative world modeling. Our architecture integrates two computational tools that have not previously come together: we model thinking with probabilistic programs, an expressive representation for commonsense reasoning; and we model meaning construction with large language models (LLMs), which support broad-coverage translation from natural language utterances to code expressions in a probabilistic programming language. We illustrate our framework through examples covering four core domains from cognitive science: probabilistic reasoning, logical and relational reasoning, visual and physical reasoning, and social reasoning. In each, we show that LLMs can generate context-sensitive translations that capture pragmatically-appropriate linguistic meanings, while Bayesian inference with the generated programs supports coherent and robust commonsense reasoning. We extend our framework to integrate cognitively-motivated symbolic modules (physics simulators, graphics engines, and planning algorithms) to provide a unified commonsense thinking interface from language. Finally, we explore how language can drive the construction of world models themselves. We hope this work will provide a roadmap towards cognitive models and AI systems that synthesize the insights of both modern and classical computational perspectives.
Sequential Monte Carlo Steering of Large Language Models using Probabilistic Programs
Jun 05, 2023Even after fine-tuning and reinforcement learning, large language models (LLMs) can be difficult, if not impossible, to control reliably with prompts alone. We propose a new inference-time approach to enforcing syntactic and semantic constraints on the outputs of LLMs, called sequential Monte Carlo (SMC) steering. The key idea is to specify language generation tasks as posterior inference problems in a class of discrete probabilistic sequence models, and replace standard decoding with sequential Monte Carlo inference. For a computational cost similar to that of beam search, SMC can steer LLMs to solve diverse tasks, including infilling, generation under syntactic constraints, and prompt intersection. To facilitate experimentation with SMC steering, we present a probabilistic programming library, LLaMPPL (https://github.com/probcomp/LLaMPPL), for concisely specifying new generation tasks as language model probabilistic programs, and automating steering of LLaMA-family Transformers.
Evaluating statistical language models as pragmatic reasoners
May 01, 2023

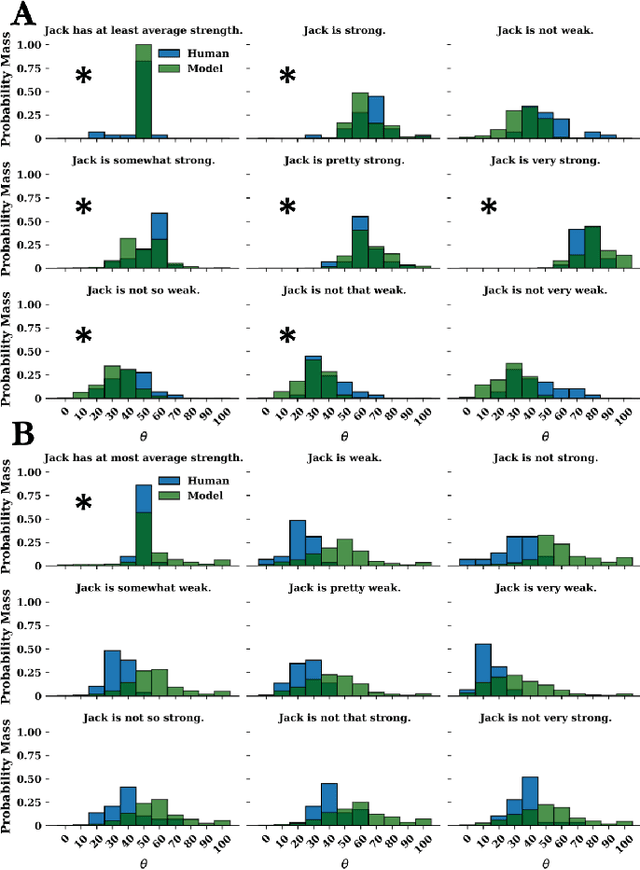
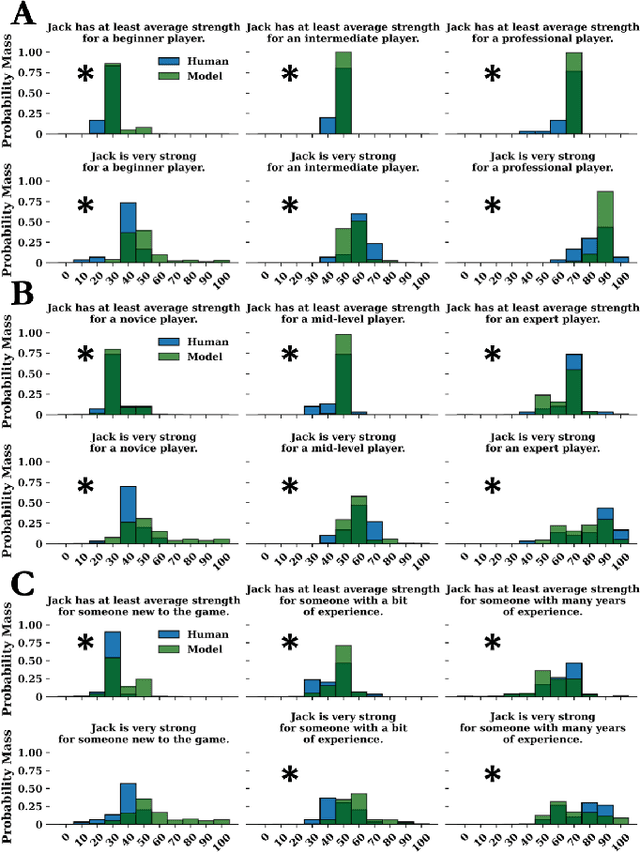
The relationship between communicated language and intended meaning is often probabilistic and sensitive to context. Numerous strategies attempt to estimate such a mapping, often leveraging recursive Bayesian models of communication. In parallel, large language models (LLMs) have been increasingly applied to semantic parsing applications, tasked with inferring logical representations from natural language. While existing LLM explorations have been largely restricted to literal language use, in this work, we evaluate the capacity of LLMs to infer the meanings of pragmatic utterances. Specifically, we explore the case of threshold estimation on the gradable adjective ``strong'', contextually conditioned on a strength prior, then extended to composition with qualification, negation, polarity inversion, and class comparison. We find that LLMs can derive context-grounded, human-like distributions over the interpretations of several complex pragmatic utterances, yet struggle composing with negation. These results inform the inferential capacity of statistical language models, and their use in pragmatic and semantic parsing applications. All corresponding code is made publicly available (https://github.com/benlipkin/probsem/tree/CogSci2023).