 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTAR: A Benchmark for Situated Reasoning in Real-World Videos
May 15, 2024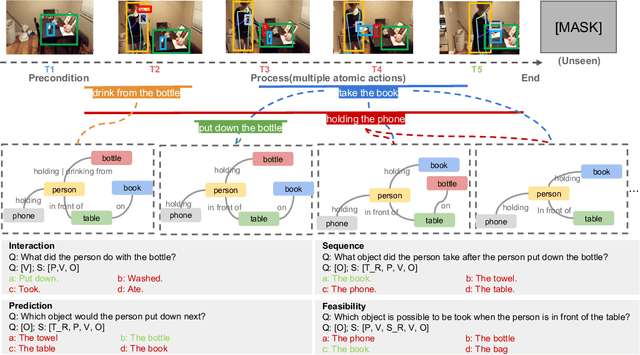
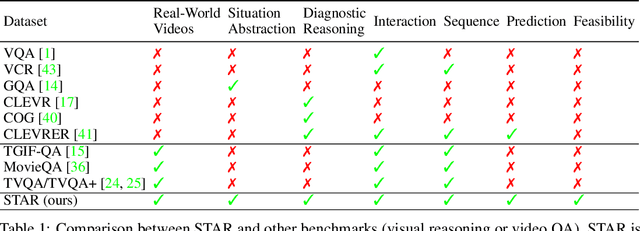
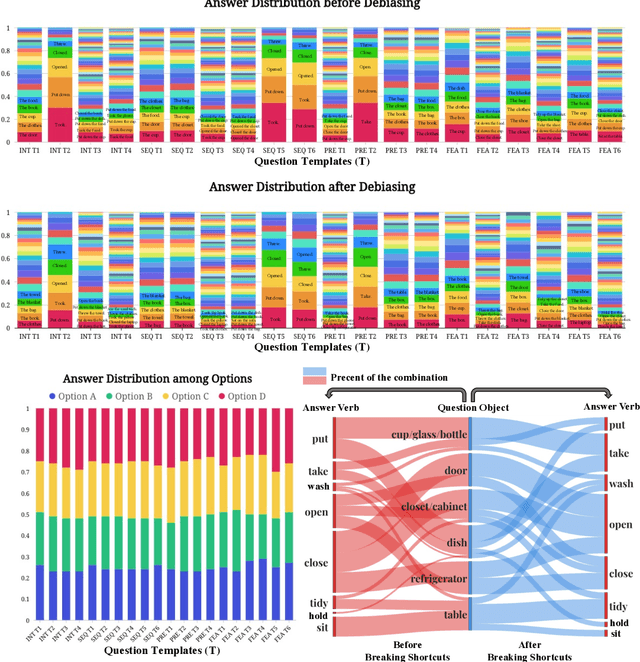
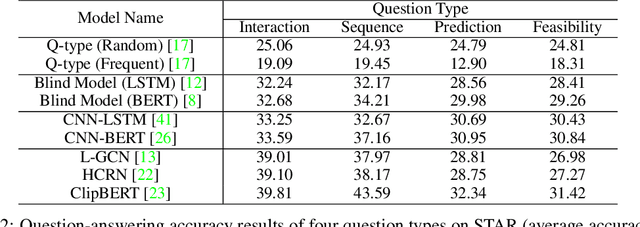
Reasoning in the real world is not divorced from situations. How to capture the present knowledge from surrounding situations and perform reasoning accordingly is crucial and challenging for machine intelligence. This paper introduces a new benchmark that evaluates the situated reasoning ability via situation abstraction and logic-grounded question answering for real-world videos, called Situated Reasoning in Real-World Videos (STAR Benchmark). This benchmark is built upon the real-world videos associated with human actions or interactions, which are naturally dynamic, compositional, and logical. The dataset includes four types of questions, including interaction, sequence, prediction, and feasibility. We represent the situations in real-world videos by hyper-graphs connecting extracted atomic entities and relations (e.g., actions, persons, objects, and relationships). Besides visual perception, situated reasoning also requires structured situation comprehension and logical reasoning. Questions and answers are procedurally generated. The answering logic of each question is represented by a functional program based on a situation hyper-graph. We compare various existing video reasoning models and find that they all struggle on this challenging situated reasoning task. We further propose a diagnostic neuro-symbolic model that can disentangle visual perception, situation abstraction, language understanding, and functional reasoning to understand the challenges of this benchmark.
Evaluating statistical language models as pragmatic reasoners
May 01, 2023

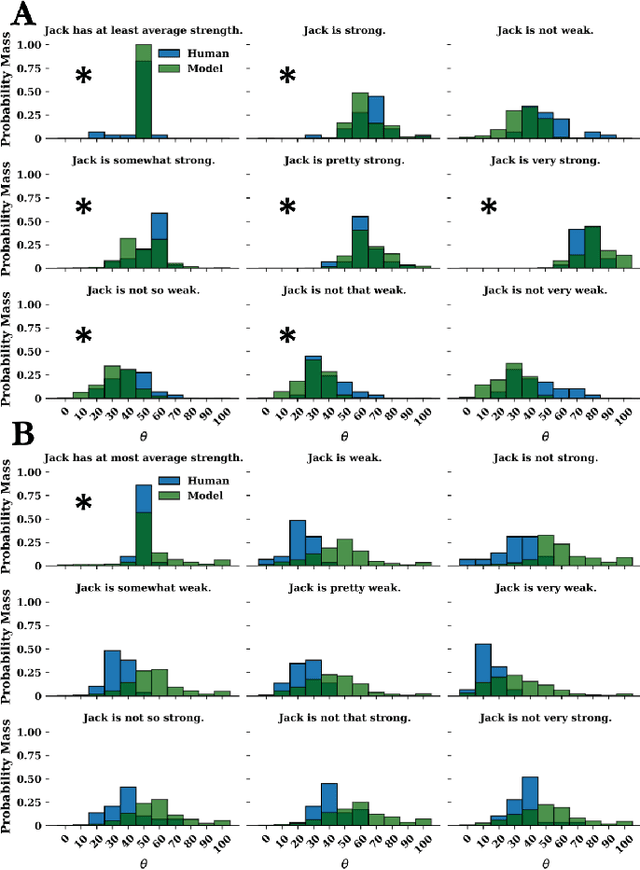
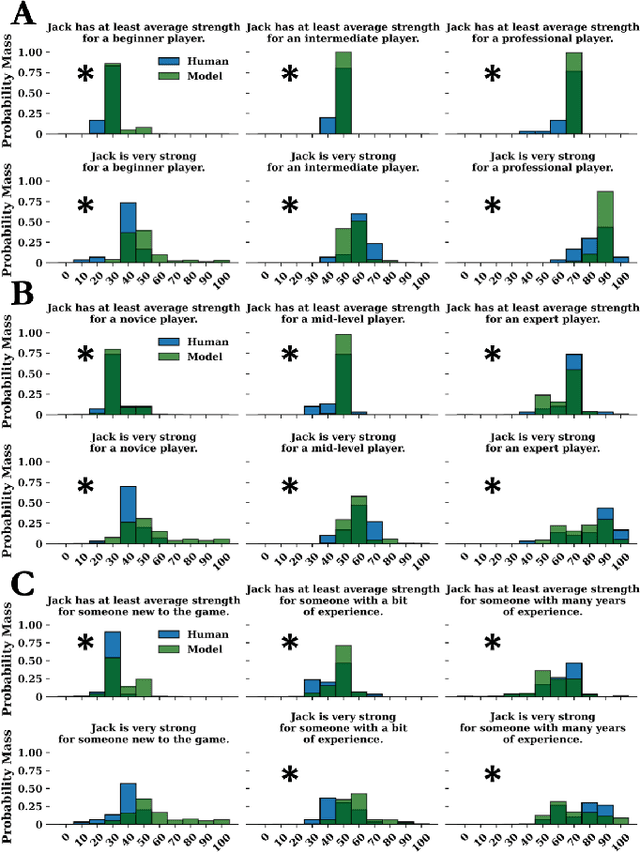
The relationship between communicated language and intended meaning is often probabilistic and sensitive to context. Numerous strategies attempt to estimate such a mapping, often leveraging recursive Bayesian models of communication. In parallel, large language models (LLMs) have been increasingly applied to semantic parsing applications, tasked with inferring logical representations from natural language. While existing LLM explorations have been largely restricted to literal language use, in this work, we evaluate the capacity of LLMs to infer the meanings of pragmatic utterances. Specifically, we explore the case of threshold estimation on the gradable adjective ``strong'', contextually conditioned on a strength prior, then extended to composition with qualification, negation, polarity inversion, and class comparison. We find that LLMs can derive context-grounded, human-like distributions over the interpretations of several complex pragmatic utterances, yet struggle composing with negation. These results inform the inferential capacity of statistical language models, and their use in pragmatic and semantic parsing applications. All corresponding code is made publicly available (https://github.com/benlipkin/probsem/tree/CogSci2023).
Stochastic Prediction of Multi-Agent Interactions from Partial Observations
Feb 25, 2019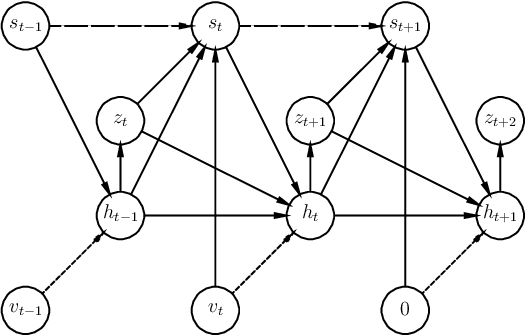

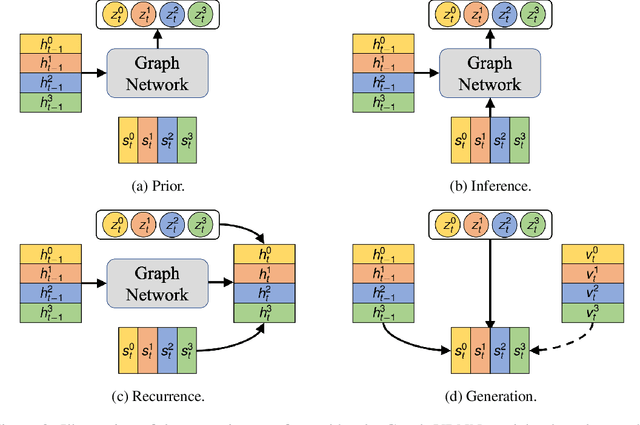

We present a method that learns to integrate temporal information, from a learned dynamics model, with ambiguous visual information, from a learned vision model, in the context of interacting agents. Our method is based on a graph-structured variational recurrent neural network (Graph-VRNN), which is trained end-to-end to infer the current state of the (partially observed) world, as well as to forecast future states. We show that our method outperforms various baselines on two sports datasets, one based on real basketball trajectories, and one generated by a soccer game engine.
The Three Pillars of Machine Programming
May 08, 2018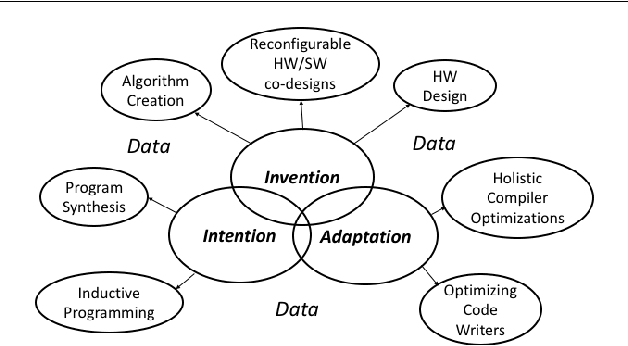
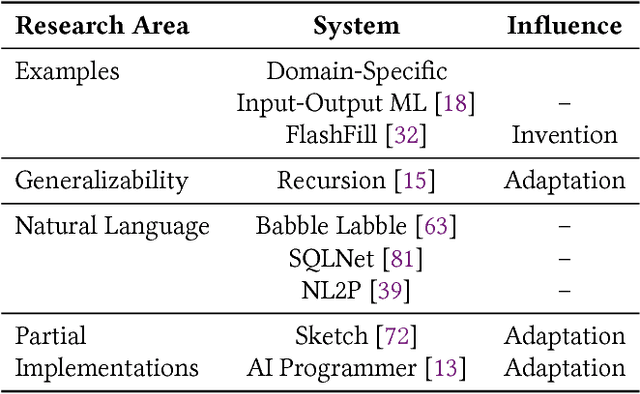
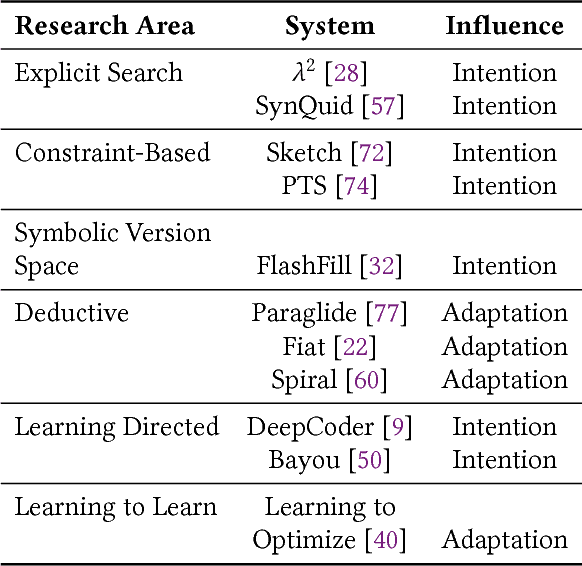
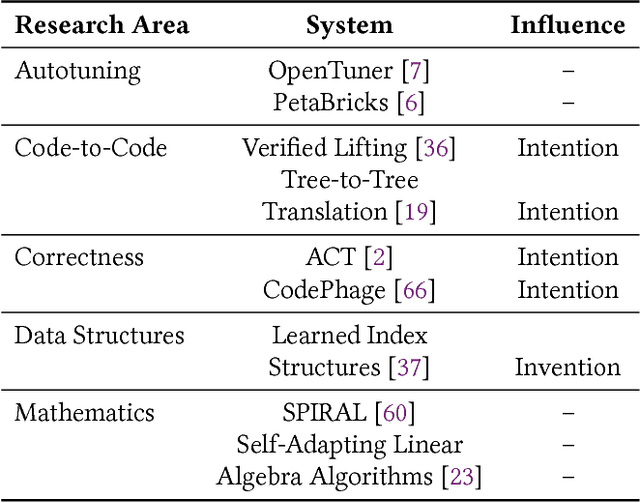
In this position paper, we describe our vision of the future of machine programming through a categorical examination of three pillars of research. Those pillars are: (i) intention, (ii) invention, and(iii) adaptation. Intention emphasizes advancements in the human-to-computer and computer-to-machine-learning interfaces. Invention emphasizes the creation or refinement of algorithms or core hardware and software building blocks through machine learning (ML). Adaptation emphasizes advances in the use of ML-based constructs to autonomously evolve software.
MarrNet: 3D Shape Reconstruction via 2.5D Sketches
Nov 08, 2017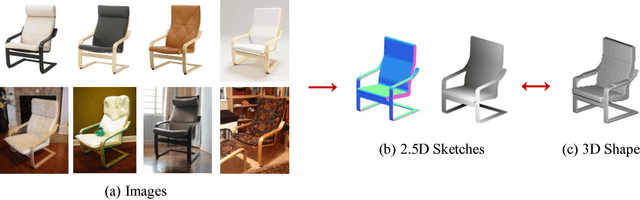
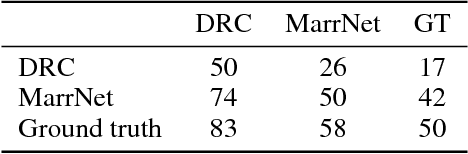
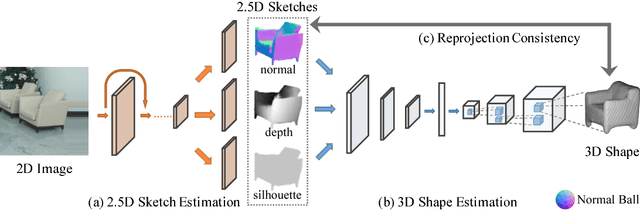
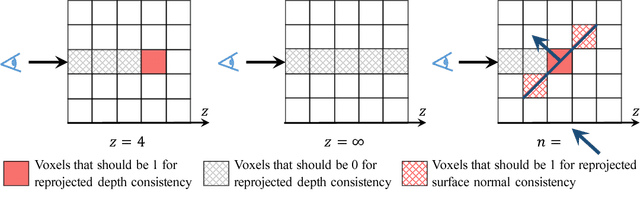
3D object reconstruction from a single image is a highly under-determined problem, requiring strong prior knowledge of plausible 3D shapes. This introduces challenges for learning-based approaches, as 3D object annotations are scarce in real images. Previous work chose to train on synthetic data with ground truth 3D information, but suffered from domain adaptation when tested on real data. In this work, we propose MarrNet, an end-to-end trainable model that sequentially estimates 2.5D sketches and 3D object shape. Our disentangled, two-step formulation has three advantages. First, compared to full 3D shape, 2.5D sketches are much easier to be recovered from a 2D image; models that recover 2.5D sketches are also more likely to transfer from synthetic to real data. Second, for 3D reconstruction from 2.5D sketches, systems can learn purely from synthetic data. This is because we can easily render realistic 2.5D sketches without modeling object appearance variations in real images, including lighting, texture, etc. This further relieves the domain adaptation problem. Third, we derive differentiable projective functions from 3D shape to 2.5D sketches; the framework is therefore end-to-end trainable on real images, requiring no human annotations. Our model achieves state-of-the-art performance on 3D shape reconstruction.