 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating statistical language models as pragmatic reasoners
Paper and Code


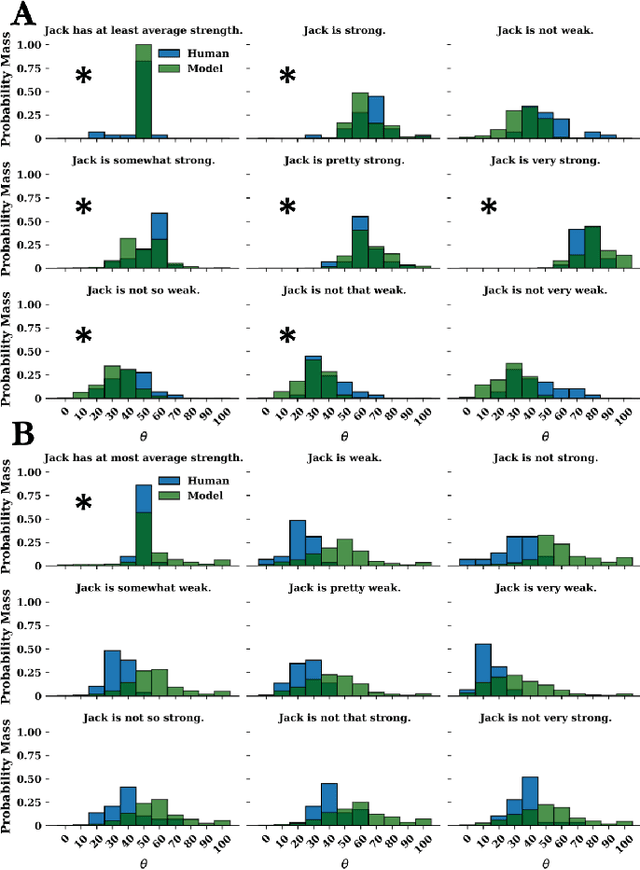
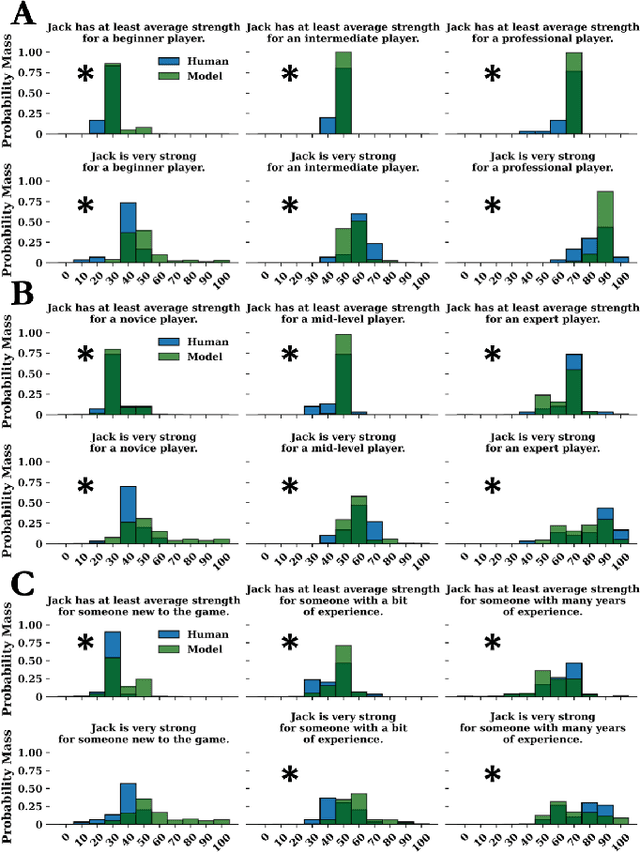
The relationship between communicated language and intended meaning is often probabilistic and sensitive to context. Numerous strategies attempt to estimate such a mapping, often leveraging recursive Bayesian models of communication. In parallel, large language models (LLMs) have been increasingly applied to semantic parsing applications, tasked with inferring logical representations from natural language. While existing LLM explorations have been largely restricted to literal language use, in this work, we evaluate the capacity of LLMs to infer the meanings of pragmatic utterances. Specifically, we explore the case of threshold estimation on the gradable adjective ``strong'', contextually conditioned on a strength prior, then extended to composition with qualification, negation, polarity inversion, and class comparison. We find that LLMs can derive context-grounded, human-like distributions over the interpretations of several complex pragmatic utterances, yet struggle composing with negation. These results inform the inferential capacity of statistical language models, and their use in pragmatic and semantic parsing applications. All corresponding code is made publicly available (https://github.com/benlipkin/probsem/tree/CogSci2023).