 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Controlled Generation from Language Models with Adaptive Weighted Rejection Sampling
Apr 07, 2025The dominant approach to generating from language models subject to some constraint is locally constrained decoding (LCD), incrementally sampling tokens at each time step such that the constraint is never violated. Typically, this is achieved through token masking: looping over the vocabulary and excluding non-conforming tokens. There are two important problems with this approach. (i) Evaluating the constraint on every token can be prohibitively expensive -- LM vocabularies often exceed $100,000$ tokens. (ii) LCD can distort the global distribution over strings, sampling tokens based only on local information, even if they lead down dead-end paths. This work introduces a new algorithm that addresses both these problems. First, to avoid evaluating a constraint on the full vocabulary at each step of generation, we propose an adaptive rejection sampling algorithm that typically requires orders of magnitude fewer constraint evaluations. Second, we show how this algorithm can be extended to produce low-variance, unbiased estimates of importance weights at a very small additional cost -- estimates that can be soundly used within previously proposed sequential Monte Carlo algorithms to correct for the myopic behavior of local constraint enforcement. Through extensive empirical evaluation in text-to-SQL, molecular synthesis, goal inference, pattern matching, and JSON domains, we show that our approach is superior to state-of-the-art baselines, supporting a broader class of constraints and improving both runtime and performance. Additional theoretical and empirical analyses show that our method's runtime efficiency is driven by its dynamic use of computation, scaling with the divergence between the unconstrained and constrained LM, and as a consequence, runtime improvements are greater for better models.
Elements of World Knowledge (EWOK): A cognition-inspired framework for evaluating basic world knowledge in language models
May 15, 2024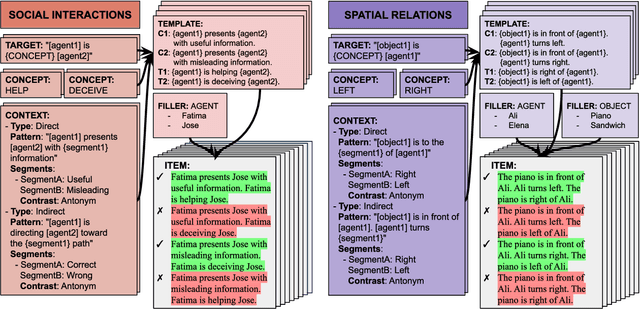
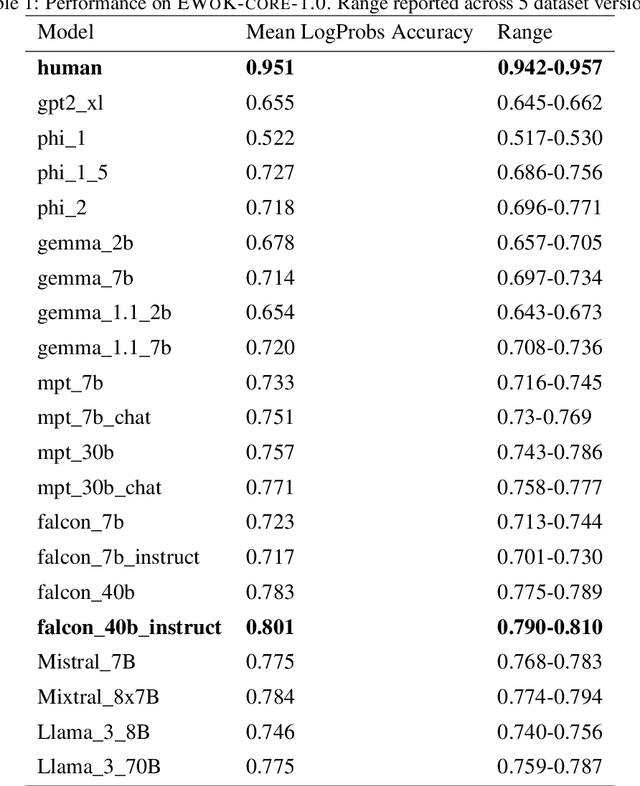
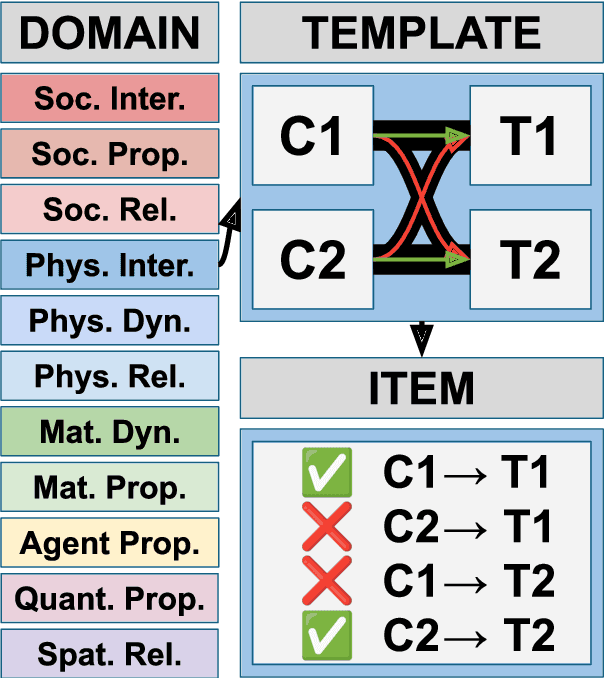
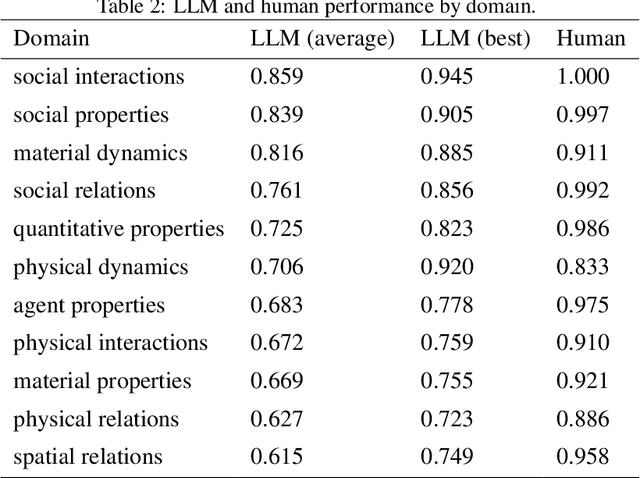
The ability to build and leverage world models is essential for a general-purpose AI agent. Testing such capabilities is hard, in part because the building blocks of world models are ill-defined. We present Elements of World Knowledge (EWOK), a framework for evaluating world modeling in language models by testing their ability to use knowledge of a concept to match a target text with a plausible/implausible context. EWOK targets specific concepts from multiple knowledge domains known to be vital for world modeling in humans. Domains range from social interactions (help/hinder) to spatial relations (left/right). Both, contexts and targets are minimal pairs. Objects, agents, and locations in the items can be flexibly filled in enabling easy generation of multiple controlled datasets. We then introduce EWOK-CORE-1.0, a dataset of 4,374 items covering 11 world knowledge domains. We evaluate 20 openweights large language models (1.3B--70B parameters) across a battery of evaluation paradigms along with a human norming study comprising 12,480 measurements. The overall performance of all tested models is worse than human performance, with results varying drastically across domains. These data highlight simple cases where even large models fail and present rich avenues for targeted research on LLM world modeling capabilities.
LINC: A Neurosymbolic Approach for Logical Reasoning by Combining Language Models with First-Order Logic Provers
Oct 23, 2023



Logical reasoning, i.e., deductively inferring the truth value of a conclusion from a set of premises, is an important task for artificial intelligence with wide potential impacts on science, mathematics, and society. While many prompting-based strategies have been proposed to enable Large Language Models (LLMs) to do such reasoning more effectively, they still appear unsatisfactory, often failing in subtle and unpredictable ways. In this work, we investigate the validity of instead reformulating such tasks as modular neurosymbolic programming, which we call LINC: Logical Inference via Neurosymbolic Computation. In LINC, the LLM acts as a semantic parser, translating premises and conclusions from natural language to expressions in first-order logic. These expressions are then offloaded to an external theorem prover, which symbolically performs deductive inference. Leveraging this approach, we observe significant performance gains on FOLIO and a balanced subset of ProofWriter for three different models in nearly all experimental conditions we evaluate. On ProofWriter, augmenting the comparatively small open-source StarCoder+ (15.5B parameters) with LINC even outperforms GPT-3.5 and GPT-4 with Chain-of-Thought (CoT) prompting by an absolute 38% and 10%, respectively. When used with GPT-4, LINC scores 26% higher than CoT on ProofWriter while performing comparatively on FOLIO. Further analysis reveals that although both methods on average succeed roughly equally often on this dataset, they exhibit distinct and complementary failure modes. We thus provide promising evidence for how logical reasoning over natural language can be tackled through jointly leveraging LLMs alongside symbolic provers. All corresponding code is publicly available at https://github.com/benlipkin/linc
StarCoder: may the source be with you!
May 09, 2023



The BigCode community, an open-scientific collaboration working on the responsible development of Large Language Models for Code (Code LLMs), introduces StarCoder and StarCoderBase: 15.5B parameter models with 8K context length, infilling capabilities and fast large-batch inference enabled by multi-query attention. StarCoderBase is trained on 1 trillion tokens sourced from The Stack, a large collection of permissively licensed GitHub repositories with inspection tools and an opt-out process. We fine-tuned StarCoderBase on 35B Python tokens, resulting in the creation of StarCoder. We perform the most comprehensive evaluation of Code LLMs to date and show that StarCoderBase outperforms every open Code LLM that supports multiple programming languages and matches or outperforms the OpenAI code-cushman-001 model. Furthermore, StarCoder outperforms every model that is fine-tuned on Python, can be prompted to achieve 40\% pass@1 on HumanEval, and still retains its performance on other programming languages. We take several important steps towards a safe open-access model release, including an improved PII redaction pipeline and a novel attribution tracing tool, and make the StarCoder models publicly available under a more commercially viable version of the Open Responsible AI Model license.
Evaluating statistical language models as pragmatic reasoners
May 01, 2023

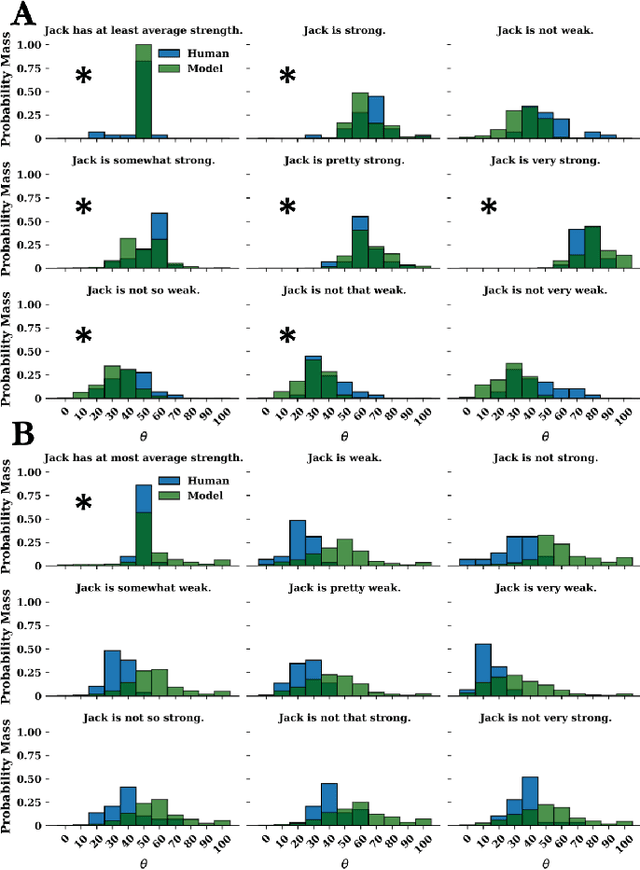
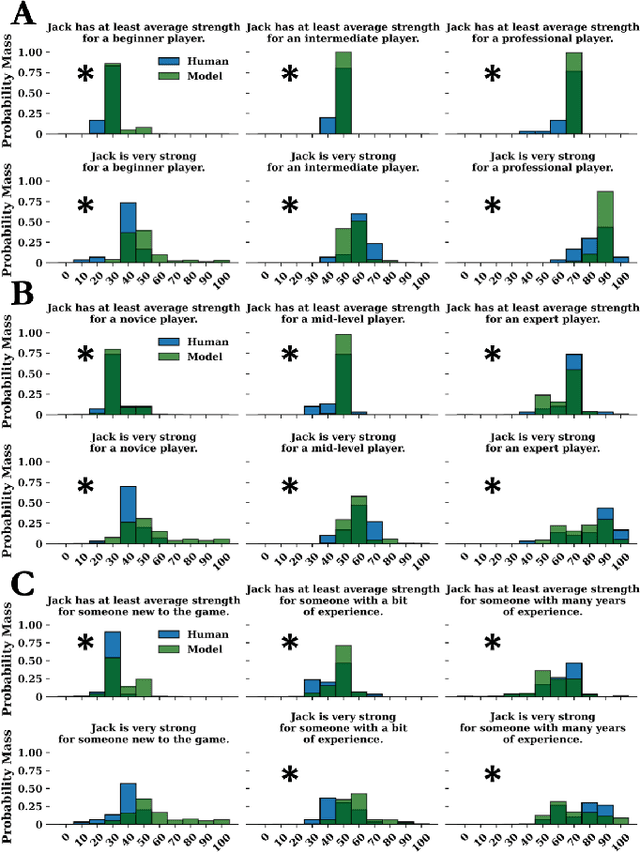
The relationship between communicated language and intended meaning is often probabilistic and sensitive to context. Numerous strategies attempt to estimate such a mapping, often leveraging recursive Bayesian models of communication. In parallel, large language models (LLMs) have been increasingly applied to semantic parsing applications, tasked with inferring logical representations from natural language. While existing LLM explorations have been largely restricted to literal language use, in this work, we evaluate the capacity of LLMs to infer the meanings of pragmatic utterances. Specifically, we explore the case of threshold estimation on the gradable adjective ``strong'', contextually conditioned on a strength prior, then extended to composition with qualification, negation, polarity inversion, and class comparison. We find that LLMs can derive context-grounded, human-like distributions over the interpretations of several complex pragmatic utterances, yet struggle composing with negation. These results inform the inferential capacity of statistical language models, and their use in pragmatic and semantic parsing applications. All corresponding code is made publicly available (https://github.com/benlipkin/probsem/tree/CogSci2023).