 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Emergent Social World Models -- Evidence for Functional Integration of Theory of Mind and Pragmatic Reasoning in Language Models
Feb 10, 2026This paper investigates whether LMs recruit shared computational mechanisms for general Theory of Mind (ToM) and language-specific pragmatic reasoning in order to contribute to the general question of whether LMs may be said to have emergent "social world models", i.e., representations of mental states that are repurposed across tasks (the functional integration hypothesis). Using behavioral evaluations and causal-mechanistic experiments via functional localization methods inspired by cognitive neuroscience, we analyze LMs' performance across seven subcategories of ToM abilities (Beaudoin et al., 2020) on a substantially larger localizer dataset than used in prior like-minded work. Results from stringent hypothesis-driven statistical testing offer suggestive evidence for the functional integration hypothesis, indicating that LMs may develop interconnected "social world models" rather than isolated competencies. This work contributes novel ToM localizer data, methodological refinements to functional localization techniques, and empirical insights into the emergence of social cognition in artificial systems.
Privileged Self-Access Matters for Introspection in AI
Aug 20, 2025Whether AI models can introspect is an increasingly important practical question. But there is no consensus on how introspection is to be defined. Beginning from a recently proposed ''lightweight'' definition, we argue instead for a thicker one. According to our proposal, introspection in AI is any process which yields information about internal states through a process more reliable than one with equal or lower computational cost available to a third party. Using experiments where LLMs reason about their internal temperature parameters, we show they can appear to have lightweight introspection while failing to meaningfully introspect per our proposed definition.
Inside you are many wolves: Using cognitive models to interpret value trade-offs in LLMs
Jun 25, 2025



Navigating everyday social situations often requires juggling conflicting goals, such as conveying a harsh truth, maintaining trust, all while still being mindful of another person's feelings. These value trade-offs are an integral part of human decision-making and language use, however, current tools for interpreting such dynamic and multi-faceted notions of values in LLMs are limited. In cognitive science, so-called "cognitive models" provide formal accounts of these trade-offs in humans, by modeling the weighting of a speaker's competing utility functions in choosing an action or utterance. In this work, we use a leading cognitive model of polite speech to interpret the extent to which LLMs represent human-like trade-offs. We apply this lens to systematically evaluate value trade-offs in two encompassing model settings: degrees of reasoning "effort" in frontier black-box models, and RL post-training dynamics of open-source models. Our results highlight patterns of higher informational utility than social utility in reasoning models, and in open-source models shown to be stronger in mathematical reasoning. Our findings from LLMs' training dynamics suggest large shifts in utility values early on in training with persistent effects of the choice of base model and pretraining data, compared to feedback dataset or alignment method. We show that our method is responsive to diverse aspects of the rapidly evolving LLM landscape, with insights for forming hypotheses about other high-level behaviors, shaping training regimes for reasoning models, and better controlling trade-offs between values during model training.
A suite of LMs comprehend puzzle statements as well as humans
May 13, 2025

Recent claims suggest that large language models (LMs) underperform humans in comprehending minimally complex English statements (Dentella et al., 2024). Here, we revisit those findings and argue that human performance was overestimated, while LLM abilities were underestimated. Using the same stimuli, we report a preregistered study comparing human responses in two conditions: one allowed rereading (replicating the original study), and one that restricted rereading (a more naturalistic comprehension test). Human accuracy dropped significantly when rereading was restricted (73%), falling below that of Falcon-180B-Chat (76%) and GPT-4 (81%). The newer GPT-o1 model achieves perfect accuracy. Results further show that both humans and models are disproportionately challenged by queries involving potentially reciprocal actions (e.g., kissing), suggesting shared pragmatic sensitivities rather than model-specific deficits. Additional analyses using Llama-2-70B log probabilities, a recoding of open-ended model responses, and grammaticality ratings of other sentences reveal systematic underestimation of model performance. We find that GPT-4o can align with either naive or expert grammaticality judgments, depending on prompt framing. These findings underscore the need for more careful experimental design and coding practices in LLM evaluation, and they challenge the assumption that current models are inherently weaker than humans at language comprehension.
Linking forward-pass dynamics in Transformers and real-time human processing
Apr 18, 2025Modern AI models are increasingly being used as theoretical tools to study human cognition. One dominant approach is to evaluate whether human-derived measures (such as offline judgments or real-time processing) are predicted by a model's output: that is, the end-product of forward pass(es) through the network. At the same time, recent advances in mechanistic interpretability have begun to reveal the internal processes that give rise to model outputs, raising the question of whether models and humans might arrive at outputs using similar "processing strategies". Here, we investigate the link between real-time processing in humans and "layer-time" dynamics in Transformer models. Across five studies spanning domains and modalities, we test whether the dynamics of computation in a single forward pass of pre-trained Transformers predict signatures of processing in humans, above and beyond properties of the model's output probability distribution. We consistently find that layer-time dynamics provide additional predictive power on top of output measures. Our results suggest that Transformer processing and human processing may be facilitated or impeded by similar properties of an input stimulus, and this similarity has emerged through general-purpose objectives such as next-token prediction or image recognition. Our work suggests a new way of using AI models to study human cognition: not just as a black box mapping stimuli to responses, but potentially also as explicit processing models.
Language Models Fail to Introspect About Their Knowledge of Language
Mar 10, 2025There has been recent interest in whether large language models (LLMs) can introspect about their own internal states. Such abilities would make LLMs more interpretable, and also validate the use of standard introspective methods in linguistics to evaluate grammatical knowledge in models (e.g., asking "Is this sentence grammatical?"). We systematically investigate emergent introspection across 21 open-source LLMs, in two domains where introspection is of theoretical interest: grammatical knowledge and word prediction. Crucially, in both domains, a model's internal linguistic knowledge can be theoretically grounded in direct measurements of string probability. We then evaluate whether models' responses to metalinguistic prompts faithfully reflect their internal knowledge. We propose a new measure of introspection: the degree to which a model's prompted responses predict its own string probabilities, beyond what would be predicted by another model with nearly identical internal knowledge. While both metalinguistic prompting and probability comparisons lead to high task accuracy, we do not find evidence that LLMs have privileged "self-access". Our findings complicate recent results suggesting that models can introspect, and add new evidence to the argument that prompted responses should not be conflated with models' linguistic generalizations.
Re-evaluating Theory of Mind evaluation in large language models
Feb 28, 2025The question of whether large language models (LLMs) possess Theory of Mind (ToM) -- often defined as the ability to reason about others' mental states -- has sparked significant scientific and public interest. However, the evidence as to whether LLMs possess ToM is mixed, and the recent growth in evaluations has not resulted in a convergence. Here, we take inspiration from cognitive science to re-evaluate the state of ToM evaluation in LLMs. We argue that a major reason for the disagreement on whether LLMs have ToM is a lack of clarity on whether models should be expected to match human behaviors, or the computations underlying those behaviors. We also highlight ways in which current evaluations may be deviating from "pure" measurements of ToM abilities, which also contributes to the confusion. We conclude by discussing several directions for future research, including the relationship between ToM and pragmatic communication, which could advance our understanding of artificial systems as well as human cognition.
Shades of Zero: Distinguishing Impossibility from Inconceivability
Feb 27, 2025Some things are impossible, but some things may be even more impossible than impossible. Levitating a feather using one's mind is impossible in our world, but fits into our intuitive theories of possible worlds, whereas levitating a feather using the number five cannot be conceived in any possible world ("inconceivable"). While prior work has examined the distinction between improbable and impossible events, there has been little empirical research on inconceivability. Here, we investigate whether people maintain a distinction between impossibility and inconceivability, and how such distinctions might be made. We find that people can readily distinguish the impossible from the inconceivable, using categorization studies similar to those used to investigate the differences between impossible and improbable (Experiment 1). However, this distinction is not explained by people's subjective ratings of event likelihood, which are near zero and indistinguishable between impossible and inconceivable event descriptions (Experiment 2). Finally, we ask whether the probabilities assigned to event descriptions by statistical language models (LMs) can be used to separate modal categories, and whether these probabilities align with people's ratings (Experiment 3). We find high-level similarities between people and LMs: both distinguish among impossible and inconceivable event descriptions, and LM-derived string probabilities predict people's ratings of event likelihood across modal categories. Our findings suggest that fine-grained knowledge about exceedingly rare events (i.e., the impossible and inconceivable) may be learned via statistical learning over linguistic forms, yet leave open the question of whether people represent the distinction between impossible and inconceivable as a difference not of degree, but of kind.
One fish, two fish, but not the whole sea: Alignment reduces language models' conceptual diversity
Nov 07, 2024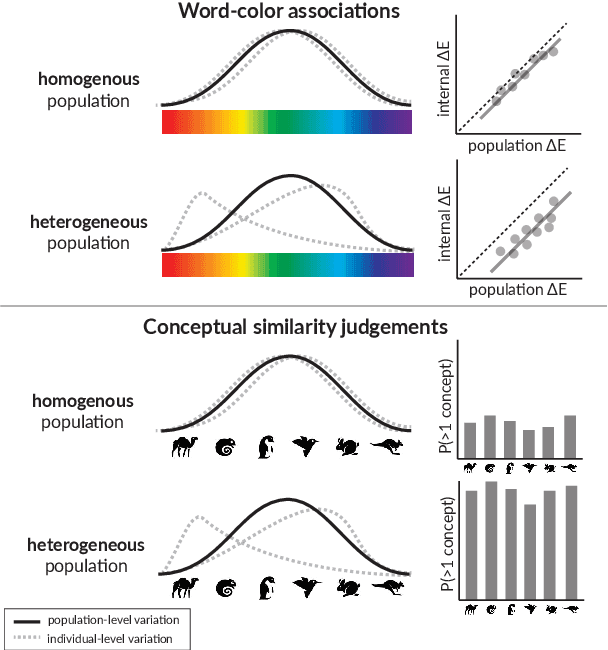
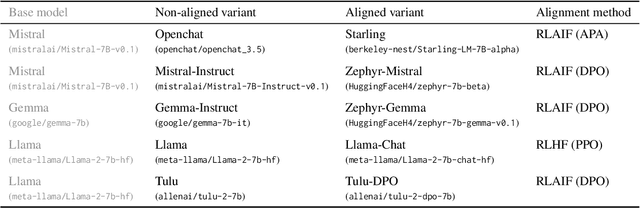
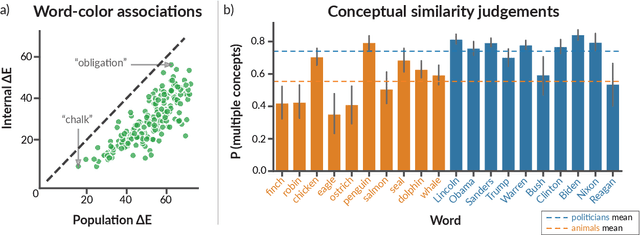
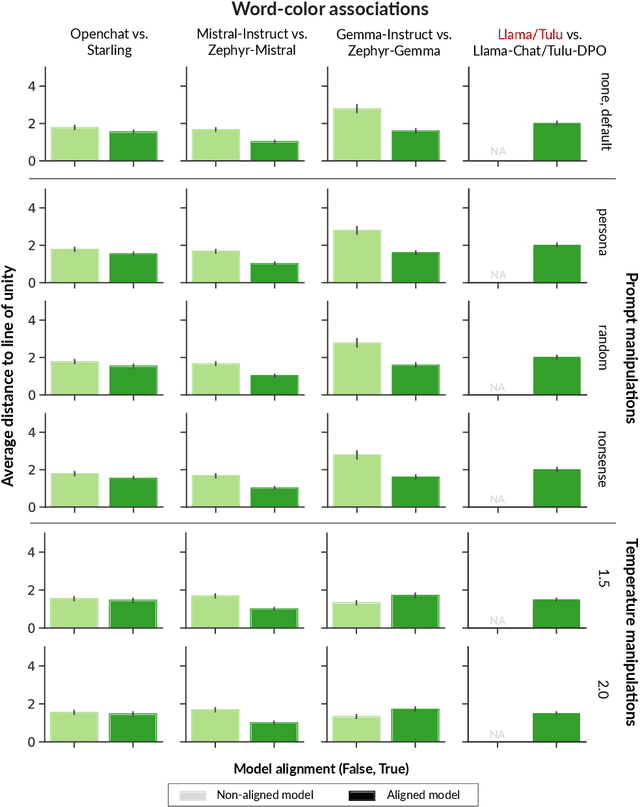
Researchers in social science and psychology have recently proposed using large language models (LLMs) as replacements for humans in behavioral research. In addition to arguments about whether LLMs accurately capture population-level patterns, this has raised questions about whether LLMs capture human-like conceptual diversity. Separately, it is debated whether post-training alignment (RLHF or RLAIF) affects models' internal diversity. Inspired by human studies, we use a new way of measuring the conceptual diversity of synthetically-generated LLM "populations" by relating the internal variability of simulated individuals to the population-level variability. We use this approach to evaluate non-aligned and aligned LLMs on two domains with rich human behavioral data. While no model reaches human-like diversity, aligned models generally display less diversity than their instruction fine-tuned counterparts. Our findings highlight potential trade-offs between increasing models' value alignment and decreasing the diversity of their conceptual representations.
Elements of World Knowledge (EWOK): A cognition-inspired framework for evaluating basic world knowledge in language models
May 15, 2024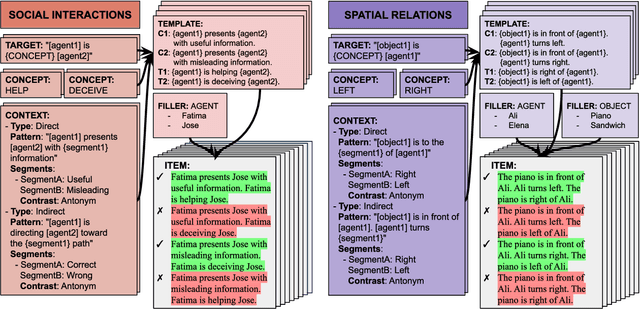
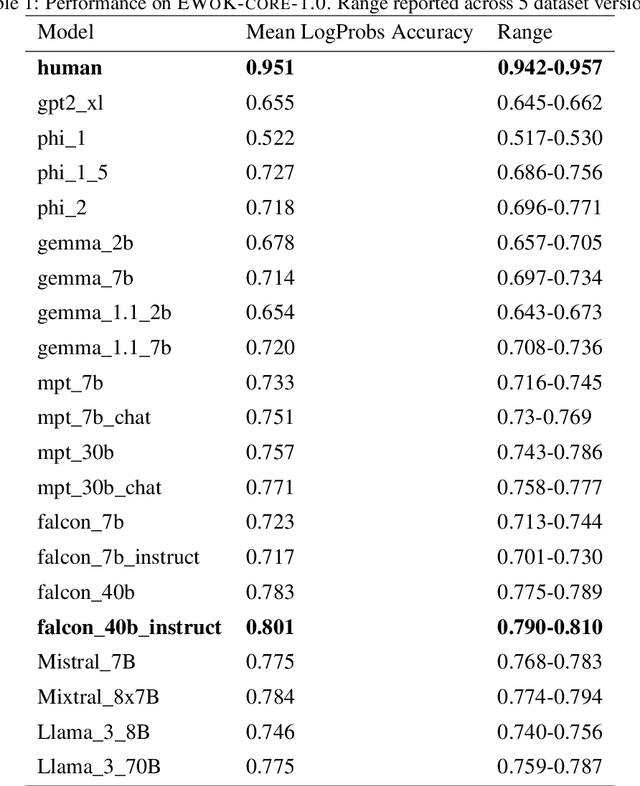
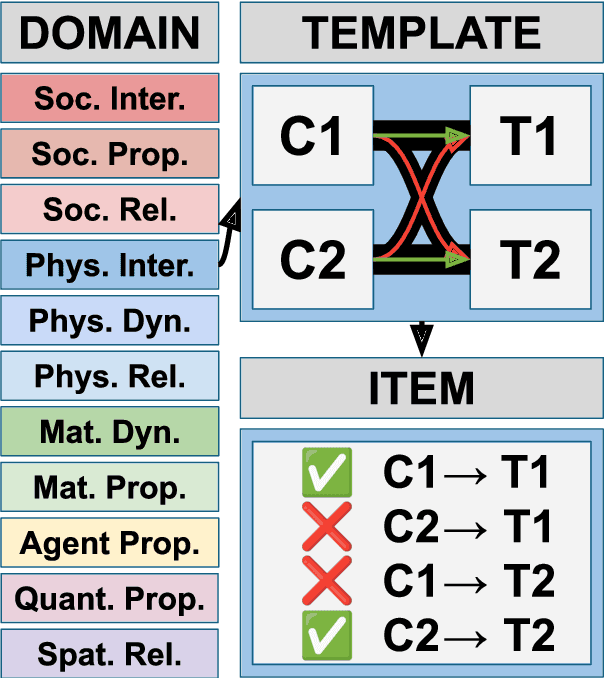
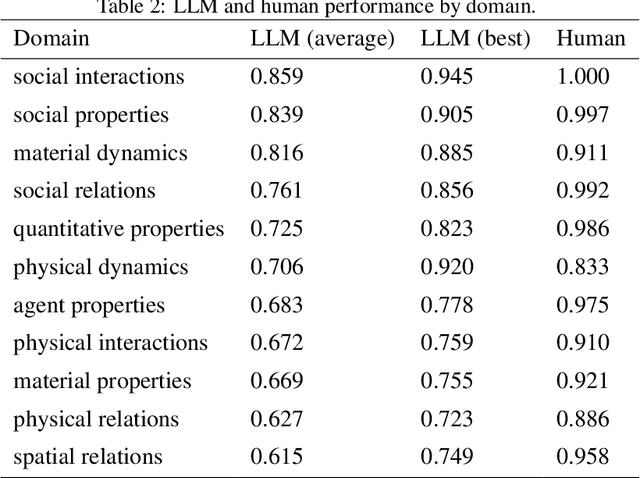
The ability to build and leverage world models is essential for a general-purpose AI agent. Testing such capabilities is hard, in part because the building blocks of world models are ill-defined. We present Elements of World Knowledge (EWOK), a framework for evaluating world modeling in language models by testing their ability to use knowledge of a concept to match a target text with a plausible/implausible context. EWOK targets specific concepts from multiple knowledge domains known to be vital for world modeling in humans. Domains range from social interactions (help/hinder) to spatial relations (left/right). Both, contexts and targets are minimal pairs. Objects, agents, and locations in the items can be flexibly filled in enabling easy generation of multiple controlled datasets. We then introduce EWOK-CORE-1.0, a dataset of 4,374 items covering 11 world knowledge domains. We evaluate 20 openweights large language models (1.3B--70B parameters) across a battery of evaluation paradigms along with a human norming study comprising 12,480 measurements. The overall performance of all tested models is worse than human performance, with results varying drastically across domains. These data highlight simple cases where even large models fail and present rich avenues for targeted research on LLM world modeling capabilities.