 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Do LLMs Use Their Depth?
Oct 21, 2025Growing evidence suggests that large language models do not use their depth uniformly, yet we still lack a fine-grained understanding of their layer-wise prediction dynamics. In this paper, we trace the intermediate representations of several open-weight models during inference and reveal a structured and nuanced use of depth. Specifically, we propose a "Guess-then-Refine" framework that explains how LLMs internally structure their computations to make predictions. We first show that the top-ranked predictions in early LLM layers are composed primarily of high-frequency tokens, which act as statistical guesses proposed by the model early on due to the lack of appropriate contextual information. As contextual information develops deeper into the model, these initial guesses get refined into contextually appropriate tokens. Even high-frequency token predictions from early layers get refined >70% of the time, indicating that correct token prediction is not "one-and-done". We then go beyond frequency-based prediction to examine the dynamic usage of layer depth across three case studies. (i) Part-of-speech analysis shows that function words are, on average, the earliest to be predicted correctly. (ii) Fact recall task analysis shows that, in a multi-token answer, the first token requires more computational depth than the rest. (iii) Multiple-choice task analysis shows that the model identifies the format of the response within the first half of the layers, but finalizes its response only toward the end. Together, our results provide a detailed view of depth usage in LLMs, shedding light on the layer-by-layer computations that underlie successful predictions and providing insights for future works to improve computational efficiency in transformer-based models.
Multilevel Interpretability Of Artificial Neural Networks: Leveraging Framework And Methods From Neuroscience
Aug 26, 2024
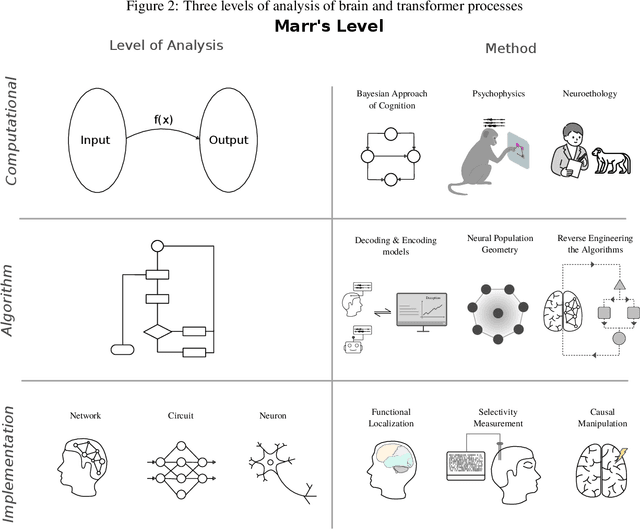
As deep learning systems are scaled up to many billions of parameters, relating their internal structure to external behaviors becomes very challenging. Although daunting, this problem is not new: Neuroscientists and cognitive scientists have accumulated decades of experience analyzing a particularly complex system - the brain. In this work, we argue that interpreting both biological and artificial neural systems requires analyzing those systems at multiple levels of analysis, with different analytic tools for each level. We first lay out a joint grand challenge among scientists who study the brain and who study artificial neural networks: understanding how distributed neural mechanisms give rise to complex cognition and behavior. We then present a series of analytical tools that can be used to analyze biological and artificial neural systems, organizing those tools according to Marr's three levels of analysis: computation/behavior, algorithm/representation, and implementation. Overall, the multilevel interpretability framework provides a principled way to tackle neural system complexity; links structure, computation, and behavior; clarifies assumptions and research priorities at each level; and paves the way toward a unified effort for understanding intelligent systems, may they be biological or artificial.
Language models align with human judgments on key grammatical constructions
Jan 19, 2024

Do Large Language Models (LLMs) make human-like linguistic generalizations? Dentella et al. (2023; "DGL") prompt several LLMs ("Is the following sentence grammatically correct in English?") to elicit grammaticality judgments of 80 English sentences, concluding that LLMs demonstrate a "yes-response bias" and a "failure to distinguish grammatical from ungrammatical sentences". We re-evaluate LLM performance using well-established practices and find that DGL's data in fact provide evidence for just how well LLMs capture human behaviors. Models not only achieve high accuracy overall, but also capture fine-grained variation in human linguistic judgments.
A Better Way to Do Masked Language Model Scoring
May 23, 2023Estimating the log-likelihood of a given sentence under an autoregressive language model is straightforward: one can simply apply the chain rule and sum the log-likelihood values for each successive token. However, for masked language models (MLMs), there is no direct way to estimate the log-likelihood of a sentence. To address this issue, Salazar et al. (2020) propose to estimate sentence pseudo-log-likelihood (PLL) scores, computed by successively masking each sentence token, retrieving its score using the rest of the sentence as context, and summing the resulting values. Here, we demonstrate that the original PLL method yields inflated scores for out-of-vocabulary words and propose an adapted metric, in which we mask not only the target token, but also all within-word tokens to the right of the target. We show that our adapted metric (PLL-word-l2r) outperforms both the original PLL metric and a PLL metric in which all within-word tokens are masked. In particular, it better satisfies theoretical desiderata and better correlates with scores from autoregressive models. Finally, we show that the choice of metric affects even tightly controlled, minimal pair evaluation benchmarks (such as BLiMP), underscoring the importance of selecting an appropriate scoring metric for evaluating MLM properties.
Does the brain represent words? An evaluation of brain decoding studies of language understanding
Jun 02, 2018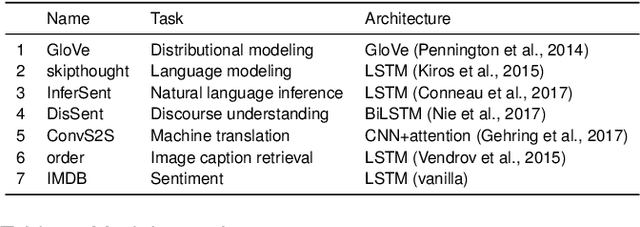


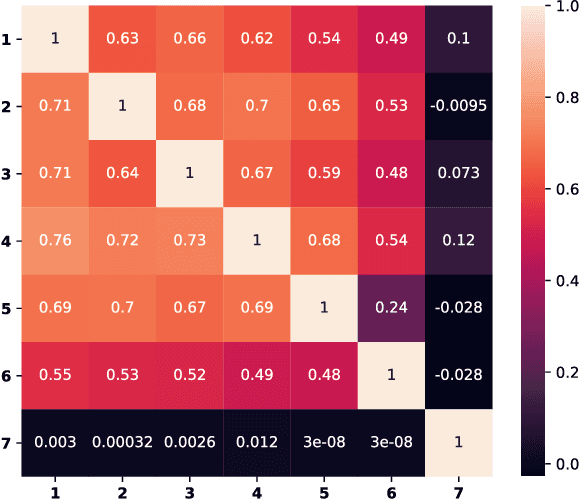
Language decoding studies have identified word representations which can be used to predict brain activity in response to novel words and sentences (Anderson et al., 2016; Pereira et al., 2018). The unspoken assumption of these studies is that, during processing, linguistic information is transformed into some shared semantic space, and those semantic representations are then used for a variety of linguistic and non-linguistic tasks. We claim that current studies vastly underdetermine the content of these representations, the algorithms which the brain deploys to produce and consume them, and the computational tasks which they are designed to solve. We illustrate this indeterminacy with an extension of the sentence-decoding experiment of Pereira et al. (2018), showing how standard evaluations fail to distinguish between language processing models which deploy different mechanisms and which are optimized to solve very different tasks. We conclude by suggesting changes to the brain decoding paradigm which can support stronger claims of neural representation.