 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbing self-supervised speech models for phonetic and phonemic information: a case study in aspiration
Jun 09, 2023Textless self-supervised speech models have grown in capabilities in recent years, but the nature of the linguistic information they encode has not yet been thoroughly examined. We evaluate the extent to which these models' learned representations align with basic representational distinctions made by humans, focusing on a set of phonetic (low-level) and phonemic (more abstract) contrasts instantiated in word-initial stops. We find that robust representations of both phonetic and phonemic distinctions emerge in early layers of these models' architectures, and are preserved in the principal components of deeper layer representations. Our analyses suggest two sources for this success: some can only be explained by the optimization of the models on speech data, while some can be attributed to these models' high-dimensional architectures. Our findings show that speech-trained HuBERT derives a low-noise and low-dimensional subspace corresponding to abstract phonological distinctions.
The neural dynamics of auditory word recognition and integration
May 22, 2023



Listeners recognize and integrate words in rapid and noisy everyday speech by combining expectations about upcoming content with incremental sensory evidence. We present a computational model of word recognition which formalizes this perceptual process in Bayesian decision theory. We fit this model to explain scalp EEG signals recorded as subjects passively listened to a fictional story, revealing both the dynamics of the online auditory word recognition process and the neural correlates of the recognition and integration of words. The model reveals distinct neural processing of words depending on whether or not they can be quickly recognized. While all words trigger a neural response characteristic of probabilistic integration -- voltage modulations predicted by a word's surprisal in context -- these modulations are amplified for words which require more than roughly 100 ms of input to be recognized. We observe no difference in the latency of these neural responses according to words' recognition times.Our results support a two-part model of speech comprehension, combining an eager and rapid process of word recognition with a temporally independent process of word integration.
Language model acceptability judgements are not always robust to context
Dec 18, 2022Targeted syntactic evaluations of language models ask whether models show stable preferences for syntactically acceptable content over minimal-pair unacceptable inputs. Most targeted syntactic evaluation datasets ask models to make these judgements with just a single context-free sentence as input. This does not match language models' training regime, in which input sentences are always highly contextualized by the surrounding corpus. This mismatch raises an important question: how robust are models' syntactic judgements in different contexts? In this paper, we investigate the stability of language models' performance on targeted syntactic evaluations as we vary properties of the input context: the length of the context, the types of syntactic phenomena it contains, and whether or not there are violations of grammaticality. We find that model judgements are generally robust when placed in randomly sampled linguistic contexts. However, they are substantially unstable for contexts containing syntactic structures matching those in the critical test content. Among all tested models (GPT-2 and five variants of OPT), we significantly improve models' judgements by providing contexts with matching syntactic structures, and conversely significantly worsen them using unacceptable contexts with matching but violated syntactic structures. This effect is amplified by the length of the context, except for unrelated inputs. We show that these changes in model performance are not explainable by simple features matching the context and the test inputs, such as lexical overlap and dependency overlap. This sensitivity to highly specific syntactic features of the context can only be explained by the models' implicit in-context learning abilities.
On the Predictive Power of Neural Language Models for Human Real-Time Comprehension Behavior
Jun 02, 2020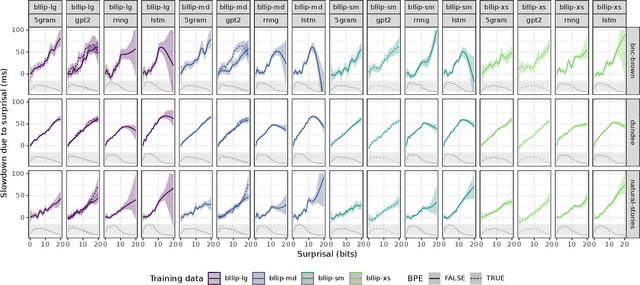
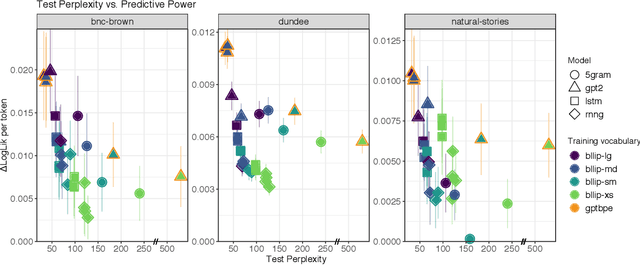
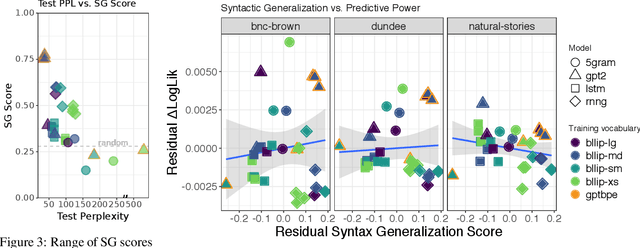
Human reading behavior is tuned to the statistics of natural language: the time it takes human subjects to read a word can be predicted from estimates of the word's probability in context. However, it remains an open question what computational architecture best characterizes the expectations deployed in real time by humans that determine the behavioral signatures of reading. Here we test over two dozen models, independently manipulating computational architecture and training dataset size, on how well their next-word expectations predict human reading time behavior on naturalistic text corpora. We find that across model architectures and training dataset sizes the relationship between word log-probability and reading time is (near-)linear. We next evaluate how features of these models determine their psychometric predictive power, or ability to predict human reading behavior. In general, the better a model's next-word expectations, the better its psychometric predictive power. However, we find nontrivial differences across model architectures. For any given perplexity, deep Transformer models and n-gram models generally show superior psychometric predictive power over LSTM or structurally supervised neural models, especially for eye movement data. Finally, we compare models' psychometric predictive power to the depth of their syntactic knowledge, as measured by a battery of syntactic generalization tests developed using methods from controlled psycholinguistic experiments. Once perplexity is controlled for, we find no significant relationship between syntactic knowledge and predictive power. These results suggest that different approaches may be required to best model human real-time language comprehension behavior in naturalistic reading versus behavior for controlled linguistic materials designed for targeted probing of syntactic knowledge.
A Systematic Assessment of Syntactic Generalization in Neural Language Models
May 23, 2020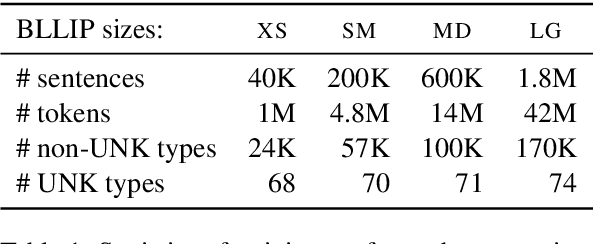
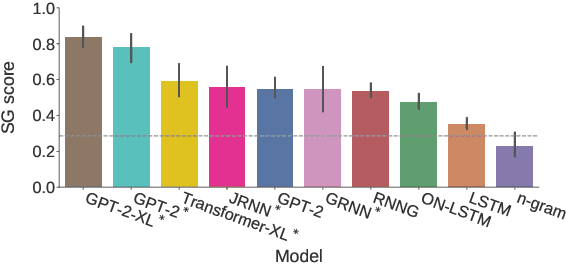
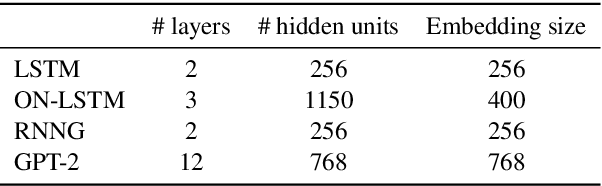
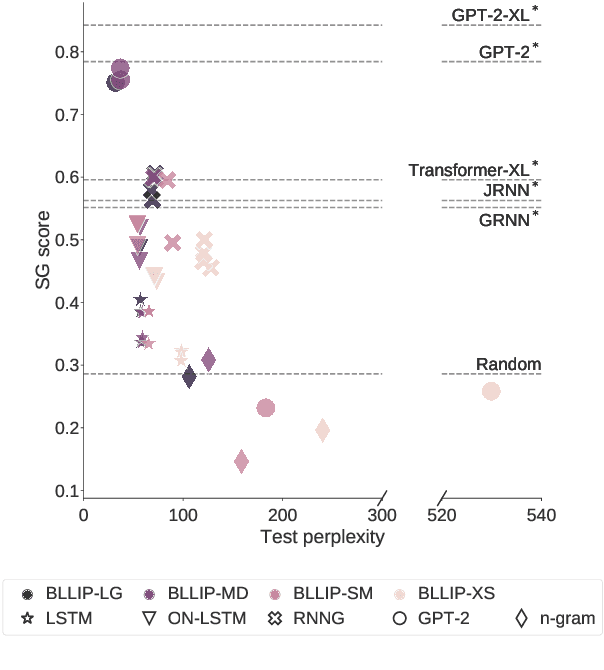
While state-of-the-art neural network models continue to achieve lower perplexity scores on language modeling benchmarks, it remains unknown whether optimizing for broad-coverage predictive performance leads to human-like syntactic knowledge. Furthermore, existing work has not provided a clear picture about the model properties required to produce proper syntactic generalizations. We present a systematic evaluation of the syntactic knowledge of neural language models, testing 20 combinations of model types and data sizes on a set of 34 English-language syntactic test suites. We find substantial differences in syntactic generalization performance by model architecture, with sequential models underperforming other architectures. Factorially manipulating model architecture and training dataset size (1M--40M words), we find that variability in syntactic generalization performance is substantially greater by architecture than by dataset size for the corpora tested in our experiments. Our results also reveal a dissociation between perplexity and syntactic generalization performance.
Linking artificial and human neural representations of language
Oct 02, 2019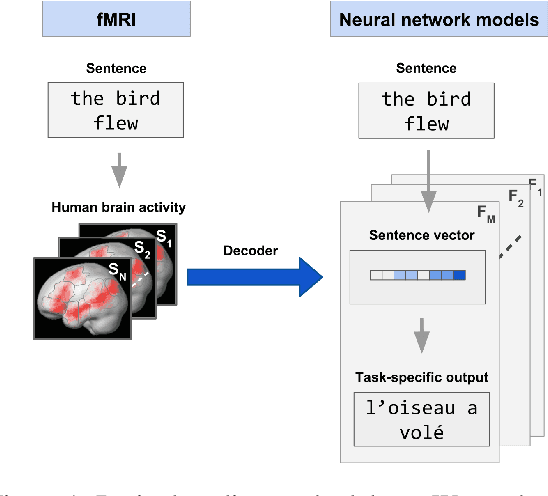

What information from an act of sentence understanding is robustly represented in the human brain? We investigate this question by comparing sentence encoding models on a brain decoding task, where the sentence that an experimental participant has seen must be predicted from the fMRI signal evoked by the sentence. We take a pre-trained BERT architecture as a baseline sentence encoding model and fine-tune it on a variety of natural language understanding (NLU) tasks, asking which lead to improvements in brain-decoding performance. We find that none of the sentence encoding tasks tested yield significant increases in brain decoding performance. Through further task ablations and representational analyses, we find that tasks which produce syntax-light representations yield significant improvements in brain decoding performance. Our results constrain the space of NLU models that could best account for human neural representations of language, but also suggest limits on the possibility of decoding fine-grained syntactic information from fMRI human neuroimaging.
Does the brain represent words? An evaluation of brain decoding studies of language understanding
Jun 02, 2018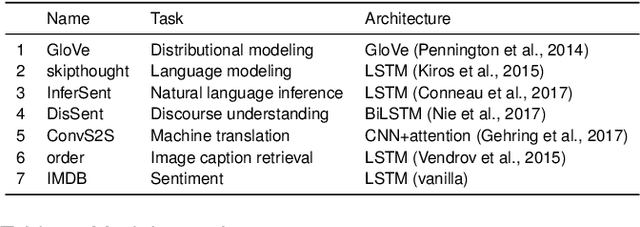


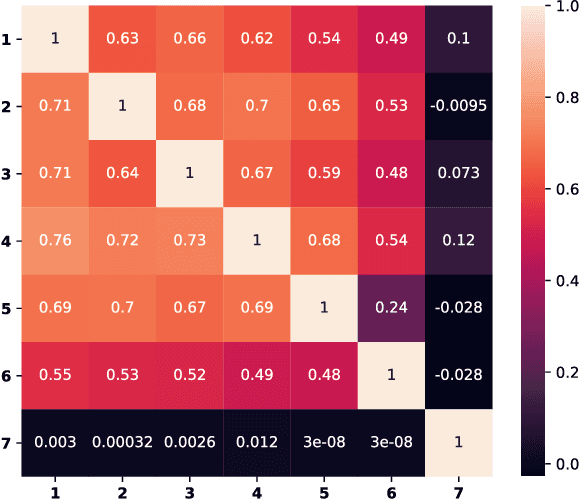
Language decoding studies have identified word representations which can be used to predict brain activity in response to novel words and sentences (Anderson et al., 2016; Pereira et al., 2018). The unspoken assumption of these studies is that, during processing, linguistic information is transformed into some shared semantic space, and those semantic representations are then used for a variety of linguistic and non-linguistic tasks. We claim that current studies vastly underdetermine the content of these representations, the algorithms which the brain deploys to produce and consume them, and the computational tasks which they are designed to solve. We illustrate this indeterminacy with an extension of the sentence-decoding experiment of Pereira et al. (2018), showing how standard evaluations fail to distinguish between language processing models which deploy different mechanisms and which are optimized to solve very different tasks. We conclude by suggesting changes to the brain decoding paradigm which can support stronger claims of neural representation.
Word learning and the acquisition of syntactic--semantic overhypotheses
May 14, 2018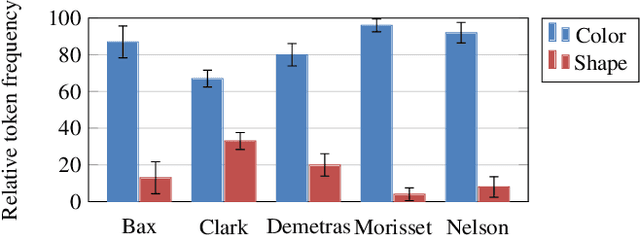
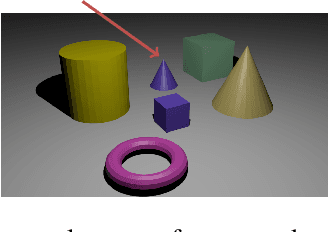

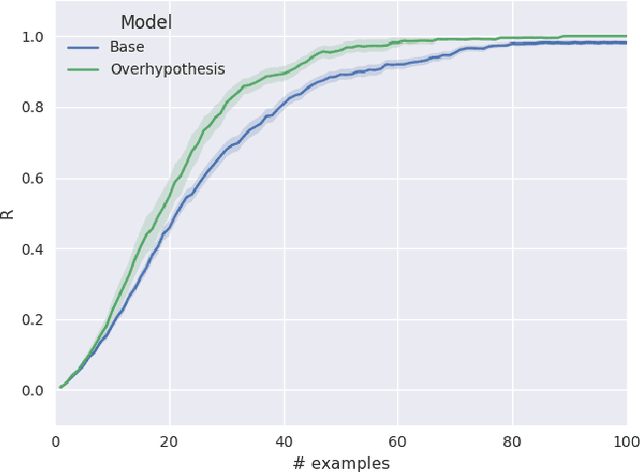
Children learning their first language face multiple problems of induction: how to learn the meanings of words, and how to build meaningful phrases from those words according to syntactic rules. We consider how children might solve these problems efficiently by solving them jointly, via a computational model that learns the syntax and semantics of multi-word utterances in a grounded reference game. We select a well-studied empirical case in which children are aware of patterns linking the syntactic and semantic properties of words --- that the properties picked out by base nouns tend to be related to shape, while prenominal adjectives tend to refer to other properties such as color. We show that children applying such inductive biases are accurately reflecting the statistics of child-directed speech, and that inducing similar biases in our computational model captures children's behavior in a classic adjective learning experiment. Our model incorporating such biases also demonstrates a clear data efficiency in learning, relative to a baseline model that learns without forming syntax-sensitive overhypotheses of word meaning. Thus solving a more complex joint inference problem may make the full problem of language acquisition easier, not harder.
Are distributional representations ready for the real world? Evaluating word vectors for grounded perceptual meaning
May 31, 2017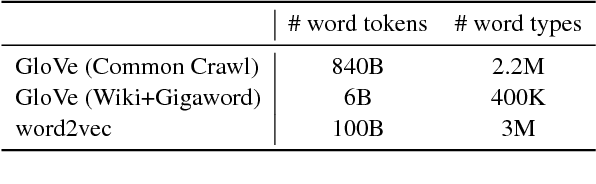

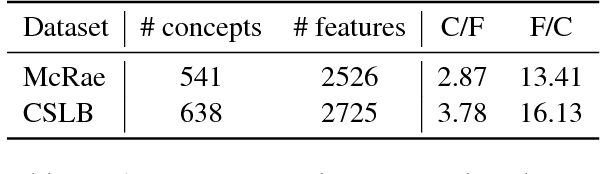
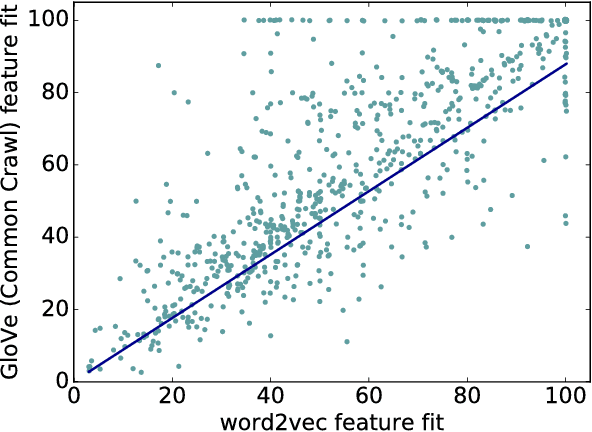
Distributional word representation methods exploit word co-occurrences to build compact vector encodings of words. While these representations enjoy widespread use in modern natural language processing, it is unclear whether they accurately encode all necessary facets of conceptual meaning. In this paper, we evaluate how well these representations can predict perceptual and conceptual features of concrete concepts, drawing on two semantic norm datasets sourced from human participants. We find that several standard word representations fail to encode many salient perceptual features of concepts, and show that these deficits correlate with word-word similarity prediction errors. Our analyses provide motivation for grounded and embodied language learning approaches, which may help to remedy these deficits.
A Paradigm for Situated and Goal-Driven Language Learning
Oct 12, 2016A distinguishing property of human intelligence is the ability to flexibly use language in order to communicate complex ideas with other humans in a variety of contexts. Research in natural language dialogue should focus on designing communicative agents which can integrate themselves into these contexts and productively collaborate with humans. In this abstract, we propose a general situated language learning paradigm which is designed to bring about robust language agents able to cooperate productively with humans.