 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Real-Time Digging-In Effects: No Evidence from NP/Z Garden-Paths
Mar 24, 2026Digging-in effects, where disambiguation difficulty increases with longer ambiguous regions, have been cited as evidence for self-organized sentence processing, in which structural commitments strengthen over time. In contrast, surprisal theory predicts no such effect unless lengthening genuinely shifts statistical expectations, and neural language models appear to show the opposite pattern. Whether digging-in is a robust real-time phenomenon in human sentence processing -- or an artifact of wrap-up processes or methodological confounds -- remains unclear. We report two experiments on English NP/Z garden-path sentences using Maze and self-paced reading, comparing human behavior with predictions from an ensemble of large language models. We find no evidence for real-time digging-in effects. Critically, items with sentence-final versus nonfinal disambiguation show qualitatively different patterns: positive digging-in trends appear only sentence-finally, where wrap-up effects confound interpretation. Nonfinal items -- the cleaner test of real-time processing -- show reverse trends consistent with neural model predictions.
Algorithmic Consequences of Particle Filters for Sentence Processing: Amplified Garden-Paths and Digging-In Effects
Mar 12, 2026Under surprisal theory, linguistic representations affect processing difficulty only through the bottleneck of surprisal. Our best estimates of surprisal come from large language models, which have no explicit representation of structural ambiguity. While LLM surprisal robustly predicts reading times across languages, it systematically underpredicts difficulty when structural expectations are violated -- suggesting that representations of ambiguity are causally implicated in sentence processing. Particle filter models offer an alternative where structural hypotheses are explicitly represented as a finite set of particles. We prove several algorithmic consequences of particle filter models, including the amplification of garden-path effects. Most critically, we demonstrate that resampling, a common practice with these models, inherently produces real-time digging-in effects -- where disambiguation difficulty increases with ambiguous region length. Digging-in magnitude scales inversely with particle count: fully parallel models predict no such effect.
BabAR: from phoneme recognition to developmental measures of young children's speech production
Mar 05, 2026Studying early speech development at scale requires automatic tools, yet automatic phoneme recognition, especially for young children, remains largely unsolved. Building on decades of data collection, we curate TinyVox, a corpus of more than half a million phonetically transcribed child vocalizations in English, French, Portuguese, German, and Spanish. We use TinyVox to train BabAR, a cross-linguistic phoneme recognition system for child speech. We find that pretraining the system on multilingual child-centered daylong recordings substantially outperforms alternatives, and that providing 20 seconds of surrounding audio context during fine-tuning further improves performance. Error analyses show that substitutions predominantly fall within the same broad phonetic categories, suggesting suitability for coarse-grained developmental analyses. We validate BabAR by showing that its automatic measures of speech maturity align with developmental estimates from the literature.
Controlled Evaluation of Syntactic Knowledge in Multilingual Language Models
Nov 12, 2024Language models (LMs) are capable of acquiring elements of human-like syntactic knowledge. Targeted syntactic evaluation tests have been employed to measure how well they form generalizations about syntactic phenomena in high-resource languages such as English. However, we still lack a thorough understanding of LMs' capacity for syntactic generalizations in low-resource languages, which are responsible for much of the diversity of syntactic patterns worldwide. In this study, we develop targeted syntactic evaluation tests for three low-resource languages (Basque, Hindi, and Swahili) and use them to evaluate five families of open-access multilingual Transformer LMs. We find that some syntactic tasks prove relatively easy for LMs while others (agreement in sentences containing indirect objects in Basque, agreement across a prepositional phrase in Swahili) are challenging. We additionally uncover issues with publicly available Transformers, including a bias toward the habitual aspect in Hindi in multilingual BERT and underperformance compared to similar-sized models in XGLM-4.5B.
Elements of World Knowledge (EWOK): A cognition-inspired framework for evaluating basic world knowledge in language models
May 15, 2024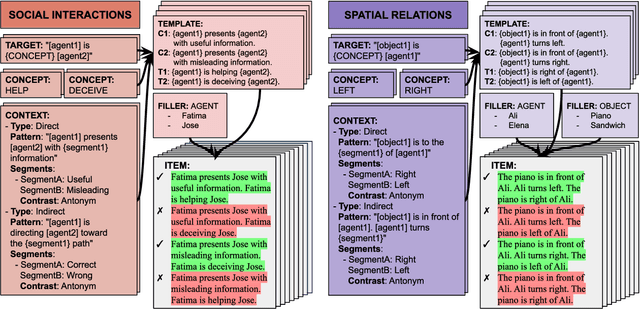
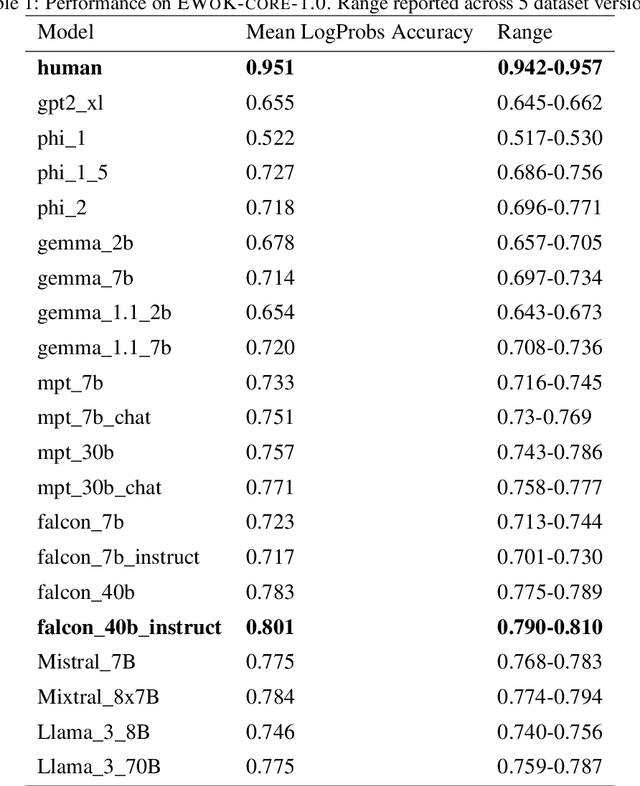
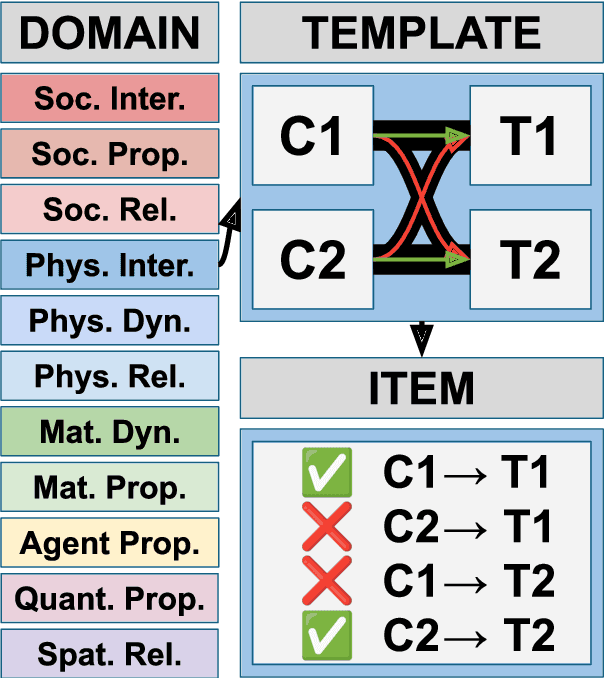
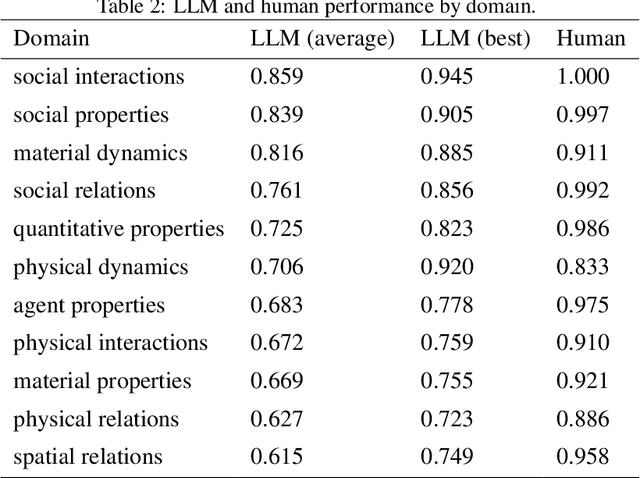
The ability to build and leverage world models is essential for a general-purpose AI agent. Testing such capabilities is hard, in part because the building blocks of world models are ill-defined. We present Elements of World Knowledge (EWOK), a framework for evaluating world modeling in language models by testing their ability to use knowledge of a concept to match a target text with a plausible/implausible context. EWOK targets specific concepts from multiple knowledge domains known to be vital for world modeling in humans. Domains range from social interactions (help/hinder) to spatial relations (left/right). Both, contexts and targets are minimal pairs. Objects, agents, and locations in the items can be flexibly filled in enabling easy generation of multiple controlled datasets. We then introduce EWOK-CORE-1.0, a dataset of 4,374 items covering 11 world knowledge domains. We evaluate 20 openweights large language models (1.3B--70B parameters) across a battery of evaluation paradigms along with a human norming study comprising 12,480 measurements. The overall performance of all tested models is worse than human performance, with results varying drastically across domains. These data highlight simple cases where even large models fail and present rich avenues for targeted research on LLM world modeling capabilities.
Learning Phonotactics from Linguistic Informants
May 08, 2024We propose an interactive approach to language learning that utilizes linguistic acceptability judgments from an informant (a competent language user) to learn a grammar. Given a grammar formalism and a framework for synthesizing data, our model iteratively selects or synthesizes a data-point according to one of a range of information-theoretic policies, asks the informant for a binary judgment, and updates its own parameters in preparation for the next query. We demonstrate the effectiveness of our model in the domain of phonotactics, the rules governing what kinds of sound-sequences are acceptable in a language, and carry out two experiments, one with typologically-natural linguistic data and another with a range of procedurally-generated languages. We find that the information-theoretic policies that our model uses to select items to query the informant achieve sample efficiency comparable to, and sometimes greater than, fully supervised approaches.
Language models align with human judgments on key grammatical constructions
Jan 19, 2024

Do Large Language Models (LLMs) make human-like linguistic generalizations? Dentella et al. (2023; "DGL") prompt several LLMs ("Is the following sentence grammatically correct in English?") to elicit grammaticality judgments of 80 English sentences, concluding that LLMs demonstrate a "yes-response bias" and a "failure to distinguish grammatical from ungrammatical sentences". We re-evaluate LLM performance using well-established practices and find that DGL's data in fact provide evidence for just how well LLMs capture human behaviors. Models not only achieve high accuracy overall, but also capture fine-grained variation in human linguistic judgments.
LINC: A Neurosymbolic Approach for Logical Reasoning by Combining Language Models with First-Order Logic Provers
Oct 23, 2023



Logical reasoning, i.e., deductively inferring the truth value of a conclusion from a set of premises, is an important task for artificial intelligence with wide potential impacts on science, mathematics, and society. While many prompting-based strategies have been proposed to enable Large Language Models (LLMs) to do such reasoning more effectively, they still appear unsatisfactory, often failing in subtle and unpredictable ways. In this work, we investigate the validity of instead reformulating such tasks as modular neurosymbolic programming, which we call LINC: Logical Inference via Neurosymbolic Computation. In LINC, the LLM acts as a semantic parser, translating premises and conclusions from natural language to expressions in first-order logic. These expressions are then offloaded to an external theorem prover, which symbolically performs deductive inference. Leveraging this approach, we observe significant performance gains on FOLIO and a balanced subset of ProofWriter for three different models in nearly all experimental conditions we evaluate. On ProofWriter, augmenting the comparatively small open-source StarCoder+ (15.5B parameters) with LINC even outperforms GPT-3.5 and GPT-4 with Chain-of-Thought (CoT) prompting by an absolute 38% and 10%, respectively. When used with GPT-4, LINC scores 26% higher than CoT on ProofWriter while performing comparatively on FOLIO. Further analysis reveals that although both methods on average succeed roughly equally often on this dataset, they exhibit distinct and complementary failure modes. We thus provide promising evidence for how logical reasoning over natural language can be tackled through jointly leveraging LLMs alongside symbolic provers. All corresponding code is publicly available at https://github.com/benlipkin/linc
Probing self-supervised speech models for phonetic and phonemic information: a case study in aspiration
Jun 09, 2023Textless self-supervised speech models have grown in capabilities in recent years, but the nature of the linguistic information they encode has not yet been thoroughly examined. We evaluate the extent to which these models' learned representations align with basic representational distinctions made by humans, focusing on a set of phonetic (low-level) and phonemic (more abstract) contrasts instantiated in word-initial stops. We find that robust representations of both phonetic and phonemic distinctions emerge in early layers of these models' architectures, and are preserved in the principal components of deeper layer representations. Our analyses suggest two sources for this success: some can only be explained by the optimization of the models on speech data, while some can be attributed to these models' high-dimensional architectures. Our findings show that speech-trained HuBERT derives a low-noise and low-dimensional subspace corresponding to abstract phonological distinctions.
A Cross-Linguistic Pressure for Uniform Information Density in Word Order
Jun 06, 2023While natural languages differ widely in both canonical word order and word order flexibility, their word orders still follow shared cross-linguistic statistical patterns, often attributed to functional pressures. In the effort to identify these pressures, prior work has compared real and counterfactual word orders. Yet one functional pressure has been overlooked in such investigations: the uniform information density (UID) hypothesis, which holds that information should be spread evenly throughout an utterance. Here, we ask whether a pressure for UID may have influenced word order patterns cross-linguistically. To this end, we use computational models to test whether real orders lead to greater information uniformity than counterfactual orders. In our empirical study of 10 typologically diverse languages, we find that: (i) among SVO languages, real word orders consistently have greater uniformity than reverse word orders, and (ii) only linguistically implausible counterfactual orders consistently exceed the uniformity of real orders. These findings are compatible with a pressure for information uniformity in the development and usage of natural languages.