 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBack to the Future: The Role of Past and Future Context Predictability in Incremental Language Production
Nov 12, 2025Contextual predictability shapes both the form and choice of words in online language production. The effects of the predictability of a word given its previous context are generally well-understood in both production and comprehension, but studies of naturalistic production have also revealed a poorly-understood backward predictability effect of a word given its future context, which may be related to future planning. Here, in two studies of naturalistic speech corpora, we investigate backward predictability effects using improved measures and more powerful language models, introducing a new principled and conceptually motivated information-theoretic predictability measure that integrates predictability from both the future and the past context. Our first study revisits classic predictability effects on word duration. Our second study investigates substitution errors within a generative framework that independently models the effects of lexical, contextual, and communicative factors on word choice, while predicting the actual words that surface as speech errors. We find that our proposed conceptually-motivated alternative to backward predictability yields qualitatively similar effects across both studies. Through a fine-grained analysis of substitution errors, we further show that different kinds of errors are suggestive of how speakers prioritize form, meaning, and context-based information during lexical planning. Together, these findings illuminate the functional roles of past and future context in how speakers encode and choose words, offering a bridge between contextual predictability effects and the mechanisms of sentence planning.
Clarifying orthography: Orthographic transparency as compressibility
May 19, 2025Orthographic transparency -- how directly spelling is related to sound -- lacks a unified, script-agnostic metric. Using ideas from algorithmic information theory, we quantify orthographic transparency in terms of the mutual compressibility between orthographic and phonological strings. Our measure provides a principled way to combine two factors that decrease orthographic transparency, capturing both irregular spellings and rule complexity in one quantity. We estimate our transparency measure using prequential code-lengths derived from neural sequence models. Evaluating 22 languages across a broad range of script types (alphabetic, abjad, abugida, syllabic, logographic) confirms common intuitions about relative transparency of scripts. Mutual compressibility offers a simple, principled, and general yardstick for orthographic transparency.
SPACER: A Parallel Dataset of Speech Production And Comprehension of Error Repairs
Mar 20, 2025
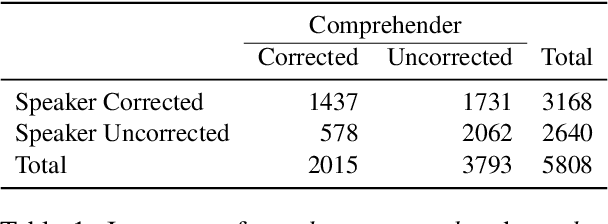


Speech errors are a natural part of communication, yet they rarely lead to complete communicative failure because both speakers and comprehenders can detect and correct errors. Although prior research has examined error monitoring and correction in production and comprehension separately, integrated investigation of both systems has been impeded by the scarcity of parallel data. In this study, we present SPACER, a parallel dataset that captures how naturalistic speech errors are corrected by both speakers and comprehenders. We focus on single-word substitution errors extracted from the Switchboard corpus, accompanied by speaker's self-repairs and comprehenders' responses from an offline text-editing experiment. Our exploratory analysis suggests asymmetries in error correction strategies: speakers are more likely to repair errors that introduce greater semantic and phonemic deviations, whereas comprehenders tend to correct errors that are phonemically similar to more plausible alternatives or do not fit into prior contexts. Our dataset enables future research on integrated approaches toward studying language production and comprehension.
Strategic resource allocation in memory encoding: An efficiency principle shaping language processing
Mar 18, 2025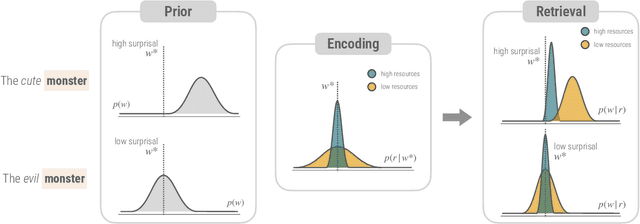
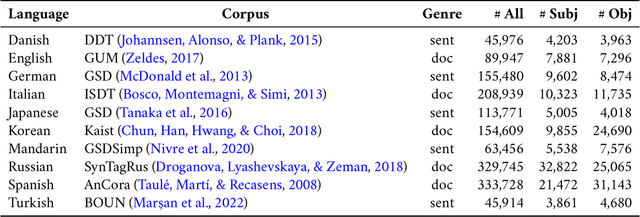
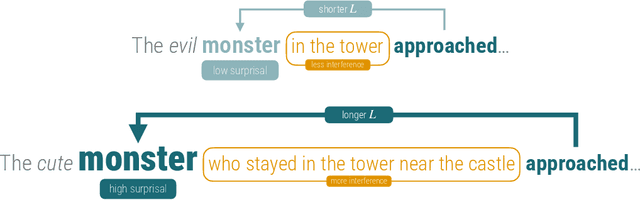
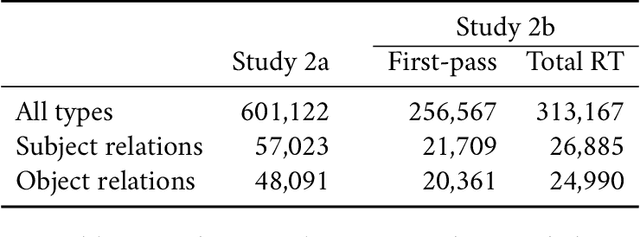
How is the limited capacity of working memory efficiently used to support human linguistic behaviors? In this paper, we investigate strategic resource allocation as an efficiency principle for memory encoding in sentence processing. The idea is that working memory resources are dynamically and strategically allocated to prioritize novel and unexpected information, enhancing their representations to make them less susceptible to memory decay and interference. Theoretically, from a resource-rational perspective, we argue that this efficiency principle naturally arises from two functional assumptions about working memory, namely, its limited capacity and its noisy representation. Empirically, through naturalistic corpus data, we find converging evidence for strategic resource allocation in the context of dependency locality from both the production and the comprehension side, where non-local dependencies with less predictable antecedents are associated with reduced locality effect. However, our results also reveal considerable cross-linguistic variability, highlighting the need for a closer examination of how strategic resource allocation, as a universal efficiency principle, interacts with language-specific phrase structures.
How Linguistics Learned to Stop Worrying and Love the Language Models
Jan 28, 2025



Language models can produce fluent, grammatical text. Nonetheless, some maintain that language models don't really learn language and also that, even if they did, that would not be informative for the study of human learning and processing. On the other side, there have been claims that the success of LMs obviates the need for studying linguistic theory and structure. We argue that both extremes are wrong. LMs can contribute to fundamental questions about linguistic structure, language processing, and learning. They force us to rethink arguments about learning and are informative for major questions in linguistic theory. But they do not replace linguistic structure and theory. We offer an optimistic take on the relationship between language models and linguistics.
Decomposition of surprisal: Unified computational model of ERP components in language processing
Sep 10, 2024The functional interpretation of language-related ERP components has been a central debate in psycholinguistics for decades. We advance an information-theoretic model of human language processing in the brain in which incoming linguistic input is processed at first shallowly and later with more depth, with these two kinds of information processing corresponding to distinct electroencephalographic signatures. Formally, we show that the information content (surprisal) of a word in context can be decomposed into two quantities: (A) heuristic surprise, which signals shallow processing difficulty for a word, and corresponds with the N400 signal; and (B) discrepancy signal, which reflects the discrepancy between shallow and deep interpretations, and corresponds to the P600 signal. Both of these quantities can be estimated straightforwardly using modern NLP models. We validate our theory by successfully simulating ERP patterns elicited by a variety of linguistic manipulations in previously-reported experimental data from six experiments, with successful novel qualitative and quantitative predictions. Our theory is compatible with traditional cognitive theories assuming a `good-enough' heuristic interpretation stage, but with a precise information-theoretic formulation. The model provides an information-theoretic model of ERP components grounded on cognitive processes, and brings us closer to a fully-specified neuro-computational model of language processing.
A hierarchical Bayesian model for syntactic priming
May 24, 2024



The effect of syntactic priming exhibits three well-documented empirical properties: the lexical boost, the inverse frequency effect, and the asymmetrical decay. We aim to show how these three empirical phenomena can be reconciled in a general learning framework, the hierarchical Bayesian model (HBM). The model represents syntactic knowledge in a hierarchical structure of syntactic statistics, where a lower level represents the verb-specific biases of syntactic decisions, and a higher level represents the abstract bias as an aggregation of verb-specific biases. This knowledge is updated in response to experience by Bayesian inference. In simulations, we show that the HBM captures the above-mentioned properties of syntactic priming. The results indicate that some properties of priming which are usually explained by a residual activation account can also be explained by an implicit learning account. We also discuss the model's implications for the lexical basis of syntactic priming.
Linguistic Structure from a Bottleneck on Sequential Information Processing
May 20, 2024Human language is a unique form of communication in the natural world, distinguished by its structured nature. Most fundamentally, it is systematic, meaning that signals can be broken down into component parts that are individually meaningful -- roughly, words -- which are combined in a regular way to form sentences. Furthermore, the way in which these parts are combined maintains a kind of locality: words are usually concatenated together, and they form contiguous phrases, keeping related parts of sentences close to each other. We address the challenge of understanding how these basic properties of language arise from broader principles of efficient communication under information processing constraints. Here we show that natural-language-like systematicity arises from minimization of excess entropy, a measure of statistical complexity that represents the minimum amount of information necessary for predicting the future of a sequence based on its past. In simulations, we show that codes that minimize excess entropy factorize their source distributions into approximately independent components, and then express those components systematically and locally. Next, in a series of massively cross-linguistic corpus studies, we show that human languages are structured to have low excess entropy at the level of phonology, morphology, syntax, and semantics. Our result suggests that human language performs a sequential generalization of Independent Components Analysis on the statistical distribution over meanings that need to be expressed. It establishes a link between the statistical and algebraic structure of human language, and reinforces the idea that the structure of human language may have evolved to minimize cognitive load while maximizing communicative expressiveness.
An information-theoretic model of shallow and deep language comprehension
May 13, 2024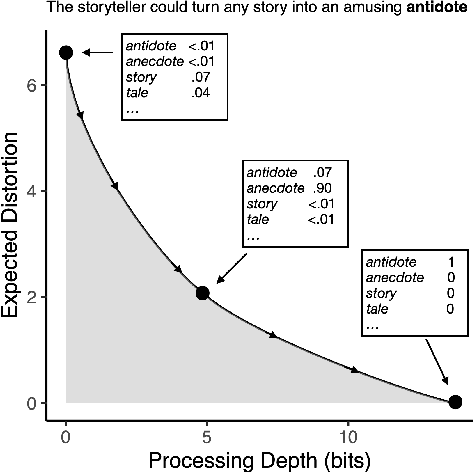
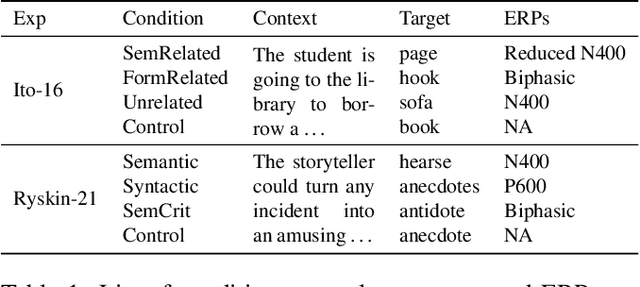
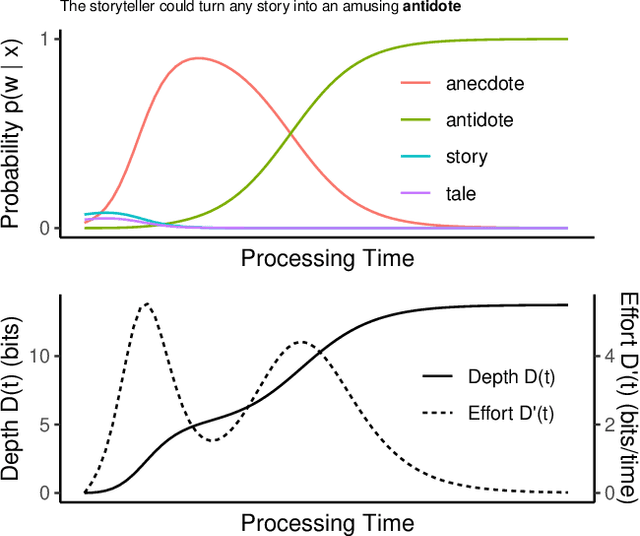
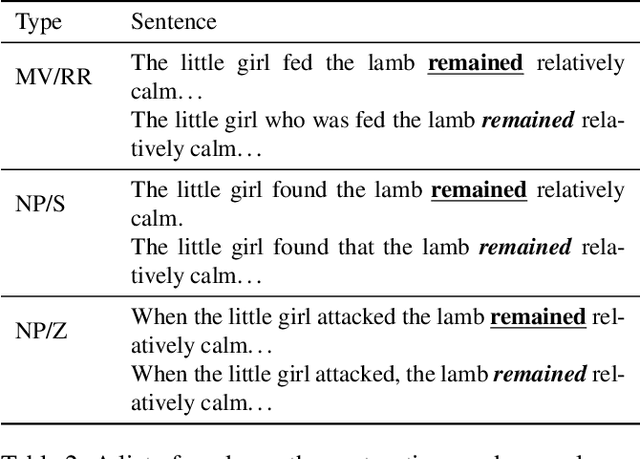
A large body of work in psycholinguistics has focused on the idea that online language comprehension can be shallow or `good enough': given constraints on time or available computation, comprehenders may form interpretations of their input that are plausible but inaccurate. However, this idea has not yet been linked with formal theories of computation under resource constraints. Here we use information theory to formulate a model of language comprehension as an optimal trade-off between accuracy and processing depth, formalized as bits of information extracted from the input, which increases with processing time. The model provides a measure of processing effort as the change in processing depth, which we link to EEG signals and reading times. We validate our theory against a large-scale dataset of garden path sentence reading times, and EEG experiments featuring N400, P600 and biphasic ERP effects. By quantifying the timecourse of language processing as it proceeds from shallow to deep, our model provides a unified framework to explain behavioral and neural signatures of language comprehension.
Mission: Impossible Language Models
Jan 12, 2024



Chomsky and others have very directly claimed that large language models (LLMs) are equally capable of learning languages that are possible and impossible for humans to learn. However, there is very little published experimental evidence to support such a claim. Here, we develop a set of synthetic impossible languages of differing complexity, each designed by systematically altering English data with unnatural word orders and grammar rules. These languages lie on an impossibility continuum: at one end are languages that are inherently impossible, such as random and irreversible shuffles of English words, and on the other, languages that may not be intuitively impossible but are often considered so in linguistics, particularly those with rules based on counting word positions. We report on a wide range of evaluations to assess the capacity of GPT-2 small models to learn these uncontroversially impossible languages, and crucially, we perform these assessments at various stages throughout training to compare the learning process for each language. Our core finding is that GPT-2 struggles to learn impossible languages when compared to English as a control, challenging the core claim. More importantly, we hope our approach opens up a productive line of inquiry in which different LLM architectures are tested on a variety of impossible languages in an effort to learn more about how LLMs can be used as tools for these cognitive and typological investigations.