 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentArk: Distilling Multi-Agent Intelligence into a Single LLM Agent
Feb 03, 2026While large language model (LLM) multi-agent systems achieve superior reasoning performance through iterative debate, practical deployment is limited by their high computational cost and error propagation. This paper proposes AgentArk, a novel framework to distill multi-agent dynamics into the weights of a single model, effectively transforming explicit test-time interactions into implicit model capabilities. This equips a single agent with the intelligence of multi-agent systems while remaining computationally efficient. Specifically, we investigate three hierarchical distillation strategies across various models, tasks, scaling, and scenarios: reasoning-enhanced fine-tuning; trajectory-based augmentation; and process-aware distillation. By shifting the burden of computation from inference to training, the distilled models preserve the efficiency of one agent while exhibiting strong reasoning and self-correction performance of multiple agents. They further demonstrate enhanced robustness and generalization across diverse reasoning tasks. We hope this work can shed light on future research on efficient and robust multi-agent development. Our code is at https://github.com/AIFrontierLab/AgentArk.
Quantifying Fairness in LLMs Beyond Tokens: A Semantic and Statistical Perspective
Jun 23, 2025Large Language Models (LLMs) often generate responses with inherent biases, undermining their reliability in real-world applications. Existing evaluation methods often overlook biases in long-form responses and the intrinsic variability of LLM outputs. To address these challenges, we propose FiSCo(Fine-grained Semantic Computation), a novel statistical framework to evaluate group-level fairness in LLMs by detecting subtle semantic differences in long-form responses across demographic groups. Unlike prior work focusing on sentiment or token-level comparisons, FiSCo goes beyond surface-level analysis by operating at the claim level, leveraging entailment checks to assess the consistency of meaning across responses. We decompose model outputs into semantically distinct claims and apply statistical hypothesis testing to compare inter- and intra-group similarities, enabling robust detection of subtle biases. We formalize a new group counterfactual fairness definition and validate FiSCo on both synthetic and human-annotated datasets spanning gender, race, and age. Experiments show that FiSco more reliably identifies nuanced biases while reducing the impact of stochastic LLM variability, outperforming various evaluation metrics.
Topological Structure Learning Should Be A Research Priority for LLM-Based Multi-Agent Systems
May 29, 2025Large Language Model-based Multi-Agent Systems (MASs) have emerged as a powerful paradigm for tackling complex tasks through collaborative intelligence. Nevertheless, the question of how agents should be structurally organized for optimal cooperation remains largely unexplored. In this position paper, we aim to gently redirect the focus of the MAS research community toward this critical dimension: develop topology-aware MASs for specific tasks. Specifically, the system consists of three core components - agents, communication links, and communication patterns - that collectively shape its coordination performance and efficiency. To this end, we introduce a systematic, three-stage framework: agent selection, structure profiling, and topology synthesis. Each stage would trigger new research opportunities in areas such as language models, reinforcement learning, graph learning, and generative modeling; together, they could unleash the full potential of MASs in complicated real-world applications. Then, we discuss the potential challenges and opportunities in the evaluation of multiple systems. We hope our perspective and framework can offer critical new insights in the era of agentic AI.
On Path to Multimodal Historical Reasoning: HistBench and HistAgent
May 26, 2025Recent advances in large language models (LLMs) have led to remarkable progress across domains, yet their capabilities in the humanities, particularly history, remain underexplored. Historical reasoning poses unique challenges for AI, involving multimodal source interpretation, temporal inference, and cross-linguistic analysis. While general-purpose agents perform well on many existing benchmarks, they lack the domain-specific expertise required to engage with historical materials and questions. To address this gap, we introduce HistBench, a new benchmark of 414 high-quality questions designed to evaluate AI's capacity for historical reasoning and authored by more than 40 expert contributors. The tasks span a wide range of historical problems-from factual retrieval based on primary sources to interpretive analysis of manuscripts and images, to interdisciplinary challenges involving archaeology, linguistics, or cultural history. Furthermore, the benchmark dataset spans 29 ancient and modern languages and covers a wide range of historical periods and world regions. Finding the poor performance of LLMs and other agents on HistBench, we further present HistAgent, a history-specific agent equipped with carefully designed tools for OCR, translation, archival search, and image understanding in History. On HistBench, HistAgent based on GPT-4o achieves an accuracy of 27.54% pass@1 and 36.47% pass@2, significantly outperforming LLMs with online search and generalist agents, including GPT-4o (18.60%), DeepSeek-R1(14.49%) and Open Deep Research-smolagents(20.29% pass@1 and 25.12% pass@2). These results highlight the limitations of existing LLMs and generalist agents and demonstrate the advantages of HistAgent for historical reasoning.
FalseReject: A Resource for Improving Contextual Safety and Mitigating Over-Refusals in LLMs via Structured Reasoning
May 12, 2025Safety alignment approaches in large language models (LLMs) often lead to the over-refusal of benign queries, significantly diminishing their utility in sensitive scenarios. To address this challenge, we introduce FalseReject, a comprehensive resource containing 16k seemingly toxic queries accompanied by structured responses across 44 safety-related categories. We propose a graph-informed adversarial multi-agent interaction framework to generate diverse and complex prompts, while structuring responses with explicit reasoning to aid models in accurately distinguishing safe from unsafe contexts. FalseReject includes training datasets tailored for both standard instruction-tuned models and reasoning-oriented models, as well as a human-annotated benchmark test set. Our extensive benchmarking on 29 state-of-the-art (SOTA) LLMs reveals persistent over-refusal challenges. Empirical results demonstrate that supervised finetuning with FalseReject substantially reduces unnecessary refusals without compromising overall safety or general language capabilities.
Strategic resource allocation in memory encoding: An efficiency principle shaping language processing
Mar 18, 2025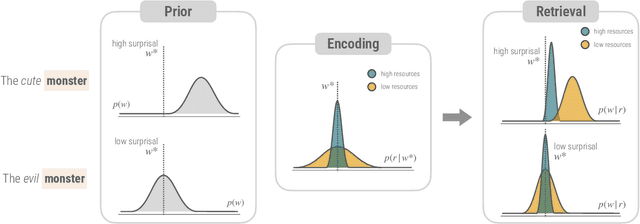
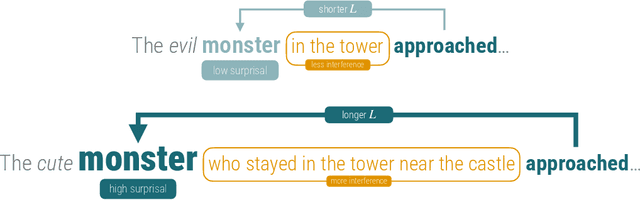
How is the limited capacity of working memory efficiently used to support human linguistic behaviors? In this paper, we investigate strategic resource allocation as an efficiency principle for memory encoding in sentence processing. The idea is that working memory resources are dynamically and strategically allocated to prioritize novel and unexpected information, enhancing their representations to make them less susceptible to memory decay and interference. Theoretically, from a resource-rational perspective, we argue that this efficiency principle naturally arises from two functional assumptions about working memory, namely, its limited capacity and its noisy representation. Empirically, through naturalistic corpus data, we find converging evidence for strategic resource allocation in the context of dependency locality from both the production and the comprehension side, where non-local dependencies with less predictable antecedents are associated with reduced locality effect. However, our results also reveal considerable cross-linguistic variability, highlighting the need for a closer examination of how strategic resource allocation, as a universal efficiency principle, interacts with language-specific phrase structures.
Neural Topic Modeling with Large Language Models in the Loop
Nov 13, 2024Topic modeling is a fundamental task in natural language processing, allowing the discovery of latent thematic structures in text corpora. While Large Language Models (LLMs) have demonstrated promising capabilities in topic discovery, their direct application to topic modeling suffers from issues such as incomplete topic coverage, misalignment of topics, and inefficiency. To address these limitations, we propose LLM-ITL, a novel LLM-in-the-loop framework that integrates LLMs with many existing Neural Topic Models (NTMs). In LLM-ITL, global topics and document representations are learned through the NTM, while an LLM refines the topics via a confidence-weighted Optimal Transport (OT)-based alignment objective. This process enhances the interpretability and coherence of the learned topics, while maintaining the efficiency of NTMs. Extensive experiments demonstrate that LLM-ITL can help NTMs significantly improve their topic interpretability while maintaining the quality of document representation.
HR-Agent: A Task-Oriented Dialogue (TOD) LLM Agent Tailored for HR Applications
Oct 15, 2024Recent LLM (Large Language Models) advancements benefit many fields such as education and finance, but HR has hundreds of repetitive processes, such as access requests, medical claim filing and time-off submissions, which are unaddressed. We relate these tasks to the LLM agent, which has addressed tasks such as writing assisting and customer support. We present HR-Agent, an efficient, confidential, and HR-specific LLM-based task-oriented dialogue system tailored for automating repetitive HR processes such as medical claims and access requests. Since conversation data is not sent to an LLM during inference, it preserves confidentiality required in HR-related tasks.
Mitigating Selection Bias with Node Pruning and Auxiliary Options
Sep 27, 2024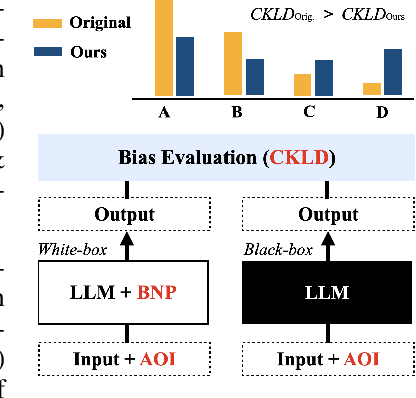
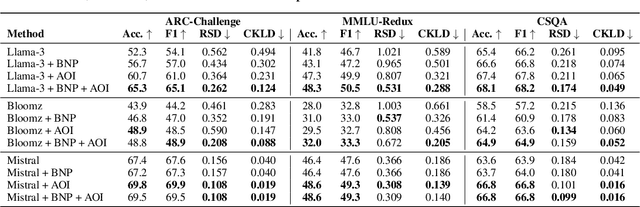
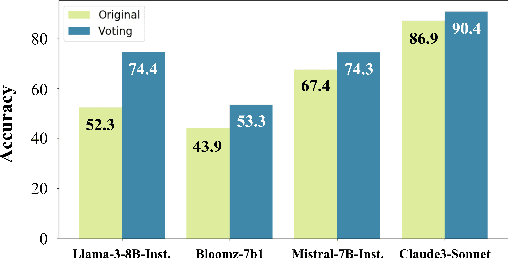
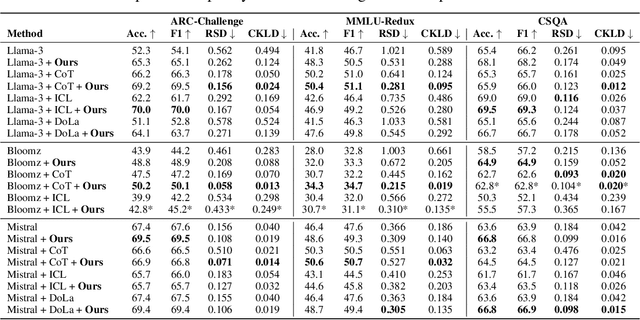
Large language models (LLMs) often show unwarranted preference for certain choice options when responding to multiple-choice questions, posing significant reliability concerns in LLM-automated systems. To mitigate this selection bias problem, previous solutions utilized debiasing methods to adjust the model's input and/or output. Our work, in contrast, investigates the model's internal representation of the selection bias. Specifically, we introduce a novel debiasing approach, Bias Node Pruning (BNP), which eliminates the linear layer parameters that contribute to the bias. Furthermore, we present Auxiliary Option Injection (AOI), a simple yet effective input modification technique for debiasing, which is compatible even with black-box LLMs. To provide a more systematic evaluation of selection bias, we review existing metrics and introduce Choice Kullback-Leibler Divergence (CKLD), which addresses the insensitivity of the commonly used metrics to label imbalance. Experiments show that our methods are robust and adaptable across various datasets when applied to three LLMs.
Synthesizing Conversations from Unlabeled Documents using Automatic Response Segmentation
Jun 06, 2024
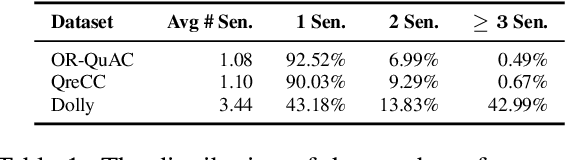
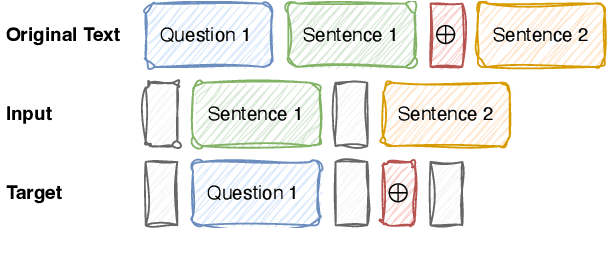
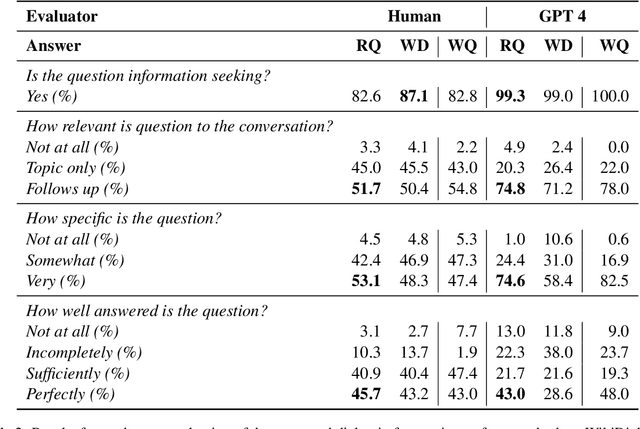
In this study, we tackle the challenge of inadequate and costly training data that has hindered the development of conversational question answering (ConvQA) systems. Enterprises have a large corpus of diverse internal documents. Instead of relying on a searching engine, a more compelling approach for people to comprehend these documents is to create a dialogue system. In this paper, we propose a robust dialog synthesising method. We learn the segmentation of data for the dialog task instead of using segmenting at sentence boundaries. The synthetic dataset generated by our proposed method achieves superior quality when compared to WikiDialog, as assessed through machine and human evaluations. By employing our inpainted data for ConvQA retrieval system pre-training, we observed a notable improvement in performance across OR-QuAC benchmarks.