 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Rollout On-Policy Distillation via Peer Successes and Failures
May 12, 2026Large language models are often post-trained with sparse verifier rewards, which indicate whether a sampled trajectory succeeds but provide limited guidance about where reasoning succeeds or fails. On-policy distillation (OPD) offers denser token-level supervision by training on student-generated trajectories, yet existing methods typically distill each rollout independently and ignore the other attempts sampled for the same prompt. We introduce Multi-Rollout On-Policy Distillation (MOPD), a peer-conditioned distillation framework that uses the student's local rollout group to construct more informative teacher signals. MOPD conditions the teacher on both successful and failed peer rollouts: successes provide positive evidence for valid reasoning patterns, while failures provide structured negative evidence about plausible mistakes to avoid. We study two peer-context constructions: positive peer imitation and contrastive success-failure conditioning. Experiments on competitive programming, mathematical reasoning, scientific question answering, and tool-use benchmarks show that MOPD consistently improves over standard on-policy baselines. Further teacher-signal analysis shows that mixed success-failure contexts better align teacher scores with verifier rewards, indicating that the gains arise from more faithful, instance-adaptive supervision. These results indicate that effective on-policy distillation should exploit the student's multi-rollout trial-and-error behavior rather than treating rollouts as isolated samples.
The Vision Wormhole: Latent-Space Communication in Heterogeneous Multi-Agent Systems
Feb 17, 2026Multi-Agent Systems (MAS) powered by Large Language Models have unlocked advanced collaborative reasoning, yet they remain shackled by the inefficiency of discrete text communication, which imposes significant runtime overhead and information quantization loss. While latent state transfer offers a high-bandwidth alternative, existing approaches either assume homogeneous sender-receiver architectures or rely on pair-specific learned translators, limiting scalability and modularity across diverse model families with disjoint manifolds. In this work, we propose the Vision Wormhole, a novel framework that repurposes the visual interface of Vision-Language Models (VLMs) to enable model-agnostic, text-free communication. By introducing a Universal Visual Codec, we map heterogeneous reasoning traces into a shared continuous latent space and inject them directly into the receiver's visual pathway, effectively treating the vision encoder as a universal port for inter-agent telepathy. Our framework adopts a hub-and-spoke topology to reduce pairwise alignment complexity from O(N^2) to O(N) and leverages a label-free, teacher-student distillation objective to align the high-speed visual channel with the robust reasoning patterns of the text pathway. Extensive experiments across heterogeneous model families (e.g., Qwen-VL, Gemma) demonstrate that the Vision Wormhole reduces end-to-end wall-clock time in controlled comparisons while maintaining reasoning fidelity comparable to standard text-based MAS. Code is available at https://github.com/xz-liu/heterogeneous-latent-mas
AgentArk: Distilling Multi-Agent Intelligence into a Single LLM Agent
Feb 03, 2026While large language model (LLM) multi-agent systems achieve superior reasoning performance through iterative debate, practical deployment is limited by their high computational cost and error propagation. This paper proposes AgentArk, a novel framework to distill multi-agent dynamics into the weights of a single model, effectively transforming explicit test-time interactions into implicit model capabilities. This equips a single agent with the intelligence of multi-agent systems while remaining computationally efficient. Specifically, we investigate three hierarchical distillation strategies across various models, tasks, scaling, and scenarios: reasoning-enhanced fine-tuning; trajectory-based augmentation; and process-aware distillation. By shifting the burden of computation from inference to training, the distilled models preserve the efficiency of one agent while exhibiting strong reasoning and self-correction performance of multiple agents. They further demonstrate enhanced robustness and generalization across diverse reasoning tasks. We hope this work can shed light on future research on efficient and robust multi-agent development. Our code is at https://github.com/AIFrontierLab/AgentArk.
The Trojan in the Vocabulary: Stealthy Sabotage of LLM Composition
Dec 31, 2025The open-weight LLM ecosystem is increasingly defined by model composition techniques (such as weight merging, speculative decoding, and vocabulary expansion) that remix capabilities from diverse sources. A critical prerequisite for applying these methods across different model families is tokenizer transplant, which aligns incompatible vocabularies to a shared embedding space. We demonstrate that this essential interoperability step introduces a supply-chain vulnerability: we engineer a single "breaker token" that is functionally inert in a donor model yet reliably reconstructs into a high-salience malicious feature after transplant into a base model. By exploiting the geometry of coefficient reuse, our attack creates an asymmetric realizability gap that sabotages the base model's generation while leaving the donor's utility statistically indistinguishable from nominal behavior. We formalize this as a dual-objective optimization problem and instantiate the attack using a sparse solver. Empirically, the attack is training-free and achieves spectral mimicry to evade outlier detection, while demonstrating structural persistence against fine-tuning and weight merging, highlighting a hidden risk in the pipeline of modular AI composition. Code is available at https://github.com/xz-liu/tokenforge
SafeRBench: A Comprehensive Benchmark for Safety Assessment in Large Reasoning Models
Nov 19, 2025Large Reasoning Models (LRMs) improve answer quality through explicit chain-of-thought, yet this very capability introduces new safety risks: harmful content can be subtly injected, surface gradually, or be justified by misleading rationales within the reasoning trace. Existing safety evaluations, however, primarily focus on output-level judgments and rarely capture these dynamic risks along the reasoning process. In this paper, we present SafeRBench, the first benchmark that assesses LRM safety end-to-end -- from inputs and intermediate reasoning to final outputs. (1) Input Characterization: We pioneer the incorporation of risk categories and levels into input design, explicitly accounting for affected groups and severity, and thereby establish a balanced prompt suite reflecting diverse harm gradients. (2) Fine-Grained Output Analysis: We introduce a micro-thought chunking mechanism to segment long reasoning traces into semantically coherent units, enabling fine-grained evaluation across ten safety dimensions. (3) Human Safety Alignment: We validate LLM-based evaluations against human annotations specifically designed to capture safety judgments. Evaluations on 19 LRMs demonstrate that SafeRBench enables detailed, multidimensional safety assessment, offering insights into risks and protective mechanisms from multiple perspectives.
Sample-aware RandAugment: Search-free Automatic Data Augmentation for Effective Image Recognition
Aug 11, 2025Automatic data augmentation (AutoDA) plays an important role in enhancing the generalization of neural networks. However, mainstream AutoDA methods often encounter two challenges: either the search process is excessively time-consuming, hindering practical application, or the performance is suboptimal due to insufficient policy adaptation during training. To address these issues, we propose Sample-aware RandAugment (SRA), an asymmetric, search-free AutoDA method that dynamically adjusts augmentation policies while maintaining straightforward implementation. SRA incorporates a heuristic scoring module that evaluates the complexity of the original training data, enabling the application of tailored augmentations for each sample. Additionally, an asymmetric augmentation strategy is employed to maximize the potential of this scoring module. In multiple experimental settings, SRA narrows the performance gap between search-based and search-free AutoDA methods, achieving a state-of-the-art Top-1 accuracy of 78.31\% on ImageNet with ResNet-50. Notably, SRA demonstrates good compatibility with existing augmentation pipelines and solid generalization across new tasks, without requiring hyperparameter tuning. The pretrained models leveraging SRA also enhance recognition in downstream object detection tasks. SRA represents a promising step towards simpler, more effective, and practical AutoDA designs applicable to a variety of future tasks. Our code is available at \href{https://github.com/ainieli/Sample-awareRandAugment}{https://github.com/ainieli/Sample-awareRandAugment
Transferable Adversarial Attacks on Black-Box Vision-Language Models
May 02, 2025



Vision Large Language Models (VLLMs) are increasingly deployed to offer advanced capabilities on inputs comprising both text and images. While prior research has shown that adversarial attacks can transfer from open-source to proprietary black-box models in text-only and vision-only contexts, the extent and effectiveness of such vulnerabilities remain underexplored for VLLMs. We present a comprehensive analysis demonstrating that targeted adversarial examples are highly transferable to widely-used proprietary VLLMs such as GPT-4o, Claude, and Gemini. We show that attackers can craft perturbations to induce specific attacker-chosen interpretations of visual information, such as misinterpreting hazardous content as safe, overlooking sensitive or restricted material, or generating detailed incorrect responses aligned with the attacker's intent. Furthermore, we discover that universal perturbations -- modifications applicable to a wide set of images -- can consistently induce these misinterpretations across multiple proprietary VLLMs. Our experimental results on object recognition, visual question answering, and image captioning show that this vulnerability is common across current state-of-the-art models, and underscore an urgent need for robust mitigations to ensure the safe and secure deployment of VLLMs.
Is Your Text-to-Image Model Robust to Caption Noise?
Dec 27, 2024In text-to-image (T2I) generation, a prevalent training technique involves utilizing Vision Language Models (VLMs) for image re-captioning. Even though VLMs are known to exhibit hallucination, generating descriptive content that deviates from the visual reality, the ramifications of such caption hallucinations on T2I generation performance remain under-explored. Through our empirical investigation, we first establish a comprehensive dataset comprising VLM-generated captions, and then systematically analyze how caption hallucination influences generation outcomes. Our findings reveal that (1) the disparities in caption quality persistently impact model outputs during fine-tuning. (2) VLMs confidence scores serve as reliable indicators for detecting and characterizing noise-related patterns in the data distribution. (3) even subtle variations in caption fidelity have significant effects on the quality of learned representations. These findings collectively emphasize the profound impact of caption quality on model performance and highlight the need for more sophisticated robust training algorithm in T2I. In response to these observations, we propose a approach leveraging VLM confidence score to mitigate caption noise, thereby enhancing the robustness of T2I models against hallucination in caption.
Efficient LLM Jailbreak via Adaptive Dense-to-sparse Constrained Optimization
May 15, 2024
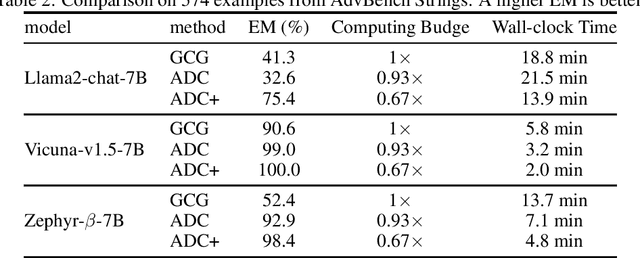


Recent research indicates that large language models (LLMs) are susceptible to jailbreaking attacks that can generate harmful content. This paper introduces a novel token-level attack method, Adaptive Dense-to-Sparse Constrained Optimization (ADC), which effectively jailbreaks several open-source LLMs. Our approach relaxes the discrete jailbreak optimization into a continuous optimization and progressively increases the sparsity of the optimizing vectors. Consequently, our method effectively bridges the gap between discrete and continuous space optimization. Experimental results demonstrate that our method is more effective and efficient than existing token-level methods. On Harmbench, our method achieves state of the art attack success rate on seven out of eight LLMs. Code will be made available. Trigger Warning: This paper contains model behavior that can be offensive in nature.
Debiasing Large Visual Language Models
Mar 08, 2024

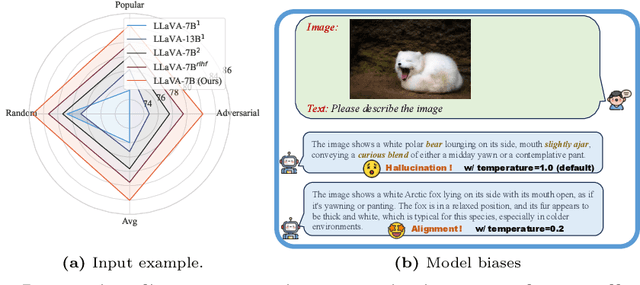

In the realms of computer vision and natural language processing, Large Vision-Language Models (LVLMs) have become indispensable tools, proficient in generating textual descriptions based on visual inputs. Despite their advancements, our investigation reveals a noteworthy bias in the generated content, where the output is primarily influenced by the underlying Large Language Models (LLMs) prior rather than the input image. Our empirical experiments underscore the persistence of this bias, as LVLMs often provide confident answers even in the absence of relevant images or given incongruent visual input. To rectify these biases and redirect the model's focus toward vision information, we introduce two simple, training-free strategies. Firstly, for tasks such as classification or multi-choice question-answering (QA), we propose a ``calibration'' step through affine transformation to adjust the output distribution. This ``Post-Hoc debias'' approach ensures uniform scores for each answer when the image is absent, serving as an effective regularization technique to alleviate the influence of LLM priors. For more intricate open-ended generation tasks, we extend this method to ``Debias sampling'', drawing inspirations from contrastive decoding methods. Furthermore, our investigation sheds light on the instability of LVLMs across various decoding configurations. Through systematic exploration of different settings, we significantly enhance performance, surpassing reported results and raising concerns about the fairness of existing evaluations. Comprehensive experiments substantiate the effectiveness of our proposed strategies in mitigating biases. These strategies not only prove beneficial in minimizing hallucinations but also contribute to the generation of more helpful and precise illustrations.