 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Geometric Invariance for Gait Recognition
Jan 09, 2026The goal of gait recognition is to extract identity-invariant features of an individual under various gait conditions, e.g., cross-view and cross-clothing. Most gait models strive to implicitly learn the common traits across different gait conditions in a data-driven manner to pull different gait conditions closer for recognition. However, relatively few studies have explicitly explored the inherent relations between different gait conditions. For this purpose, we attempt to establish connections among different gait conditions and propose a new perspective to achieve gait recognition: variations in different gait conditions can be approximately viewed as a combination of geometric transformations. In this case, all we need is to determine the types of geometric transformations and achieve geometric invariance, then identity invariance naturally follows. As an initial attempt, we explore three common geometric transformations (i.e., Reflect, Rotate, and Scale) and design a $\mathcal{R}$eflect-$\mathcal{R}$otate-$\mathcal{S}$cale invariance learning framework, named ${\mathcal{RRS}}$-Gait. Specifically, it first flexibly adjusts the convolution kernel based on the specific geometric transformations to achieve approximate feature equivariance. Then these three equivariant-aware features are respectively fed into a global pooling operation for final invariance-aware learning. Extensive experiments on four popular gait datasets (Gait3D, GREW, CCPG, SUSTech1K) show superior performance across various gait conditions.
QAGait: Revisit Gait Recognition from a Quality Perspective
Jan 24, 2024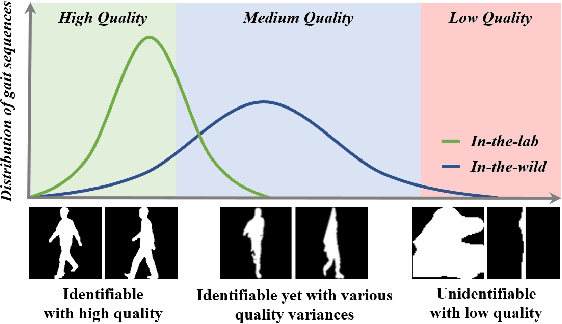
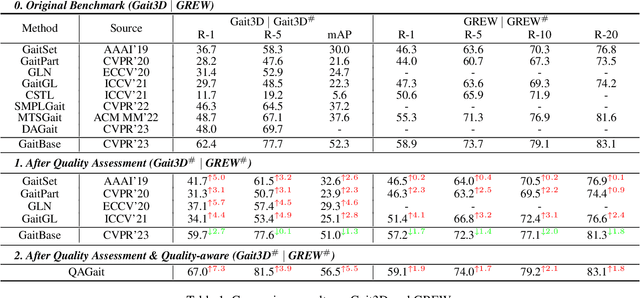
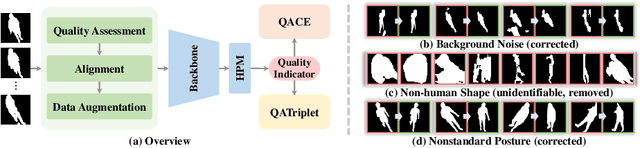
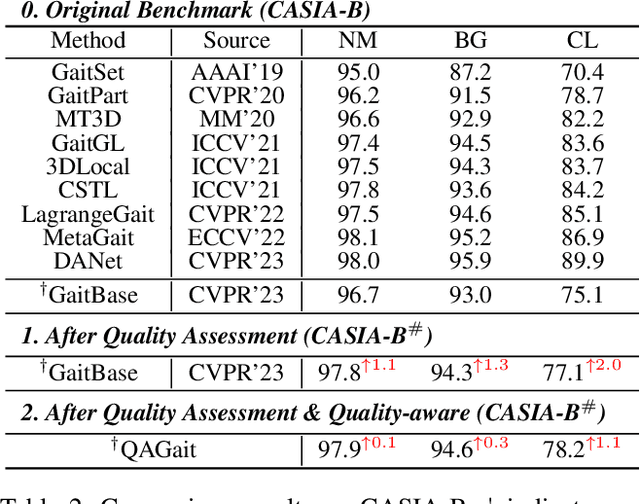
Gait recognition is a promising biometric method that aims to identify pedestrians from their unique walking patterns. Silhouette modality, renowned for its easy acquisition, simple structure, sparse representation, and convenient modeling, has been widely employed in controlled in-the-lab research. However, as gait recognition rapidly advances from in-the-lab to in-the-wild scenarios, various conditions raise significant challenges for silhouette modality, including 1) unidentifiable low-quality silhouettes (abnormal segmentation, severe occlusion, or even non-human shape), and 2) identifiable but challenging silhouettes (background noise, non-standard posture, slight occlusion). To address these challenges, we revisit gait recognition pipeline and approach gait recognition from a quality perspective, namely QAGait. Specifically, we propose a series of cost-effective quality assessment strategies, including Maxmial Connect Area and Template Match to eliminate background noises and unidentifiable silhouettes, Alignment strategy to handle non-standard postures. We also propose two quality-aware loss functions to integrate silhouette quality into optimization within the embedding space. Extensive experiments demonstrate our QAGait can guarantee both gait reliability and performance enhancement. Furthermore, our quality assessment strategies can seamlessly integrate with existing gait datasets, showcasing our superiority. Code is available at https://github.com/wzb-bupt/QAGait.
FastPoseGait: A Toolbox and Benchmark for Efficient Pose-based Gait Recognition
Sep 02, 2023We present FastPoseGait, an open-source toolbox for pose-based gait recognition based on PyTorch. Our toolbox supports a set of cutting-edge pose-based gait recognition algorithms and a variety of related benchmarks. Unlike other pose-based projects that focus on a single algorithm, FastPoseGait integrates several state-of-the-art (SOTA) algorithms under a unified framework, incorporating both the latest advancements and best practices to ease the comparison of effectiveness and efficiency. In addition, to promote future research on pose-based gait recognition, we provide numerous pre-trained models and detailed benchmark results, which offer valuable insights and serve as a reference for further investigations. By leveraging the highly modular structure and diverse methods offered by FastPoseGait, researchers can quickly delve into pose-based gait recognition and promote development in the field. In this paper, we outline various features of this toolbox, aiming that our toolbox and benchmarks can further foster collaboration, facilitate reproducibility, and encourage the development of innovative algorithms for pose-based gait recognition. FastPoseGait is available at https://github.com//BNU-IVC/FastPoseGait and is actively maintained. We will continue updating this report as we add new features.
Free Lunch for Gait Recognition: A Novel Relation Descriptor
Aug 28, 2023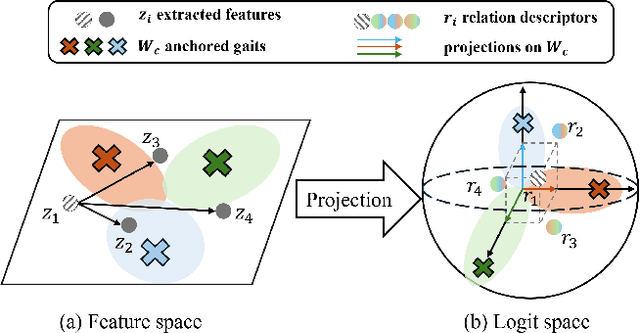
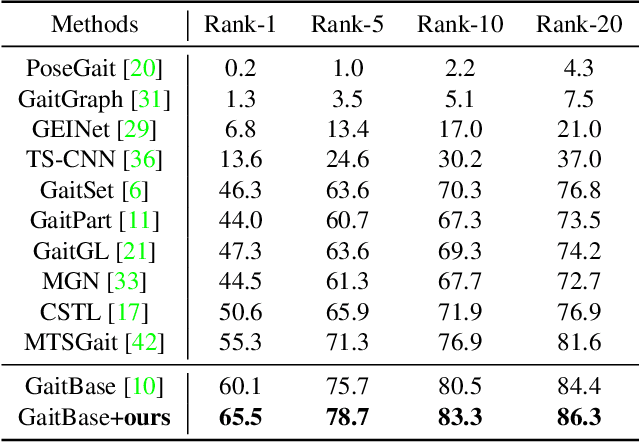
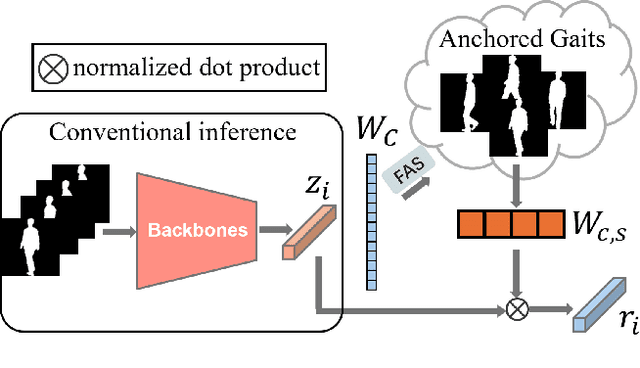
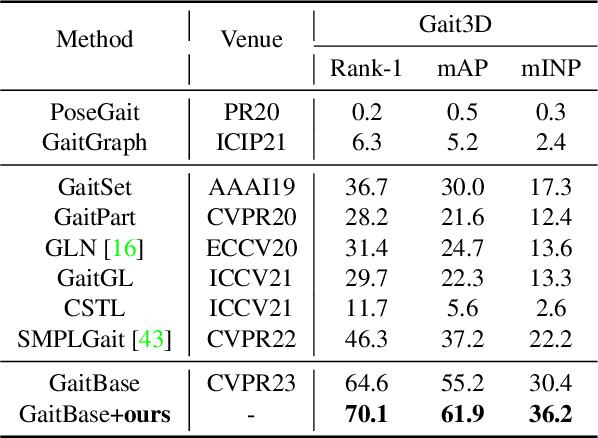
Gait recognition is to seek correct matches for query individuals by their unique walking patterns. However, current methods focus solely on extracting individual-specific features, overlooking inter-personal relationships. In this paper, we propose a novel $\textbf{Relation Descriptor}$ that captures not only individual features but also relations between test gaits and pre-selected anchored gaits. Specifically, we reinterpret classifier weights as anchored gaits and compute similarity scores between test features and these anchors, which re-expresses individual gait features into a similarity relation distribution. In essence, the relation descriptor offers a holistic perspective that leverages the collective knowledge stored within the classifier's weights, emphasizing meaningful patterns and enhancing robustness. Despite its potential, relation descriptor poses dimensionality challenges since its dimension depends on the training set's identity count. To address this, we propose the Farthest Anchored-gait Selection to identify the most discriminative anchored gaits and an Orthogonal Regularization to increase diversity within anchored gaits. Compared to individual-specific features extracted from the backbone, our relation descriptor can boost the performances nearly without any extra costs. We evaluate the effectiveness of our method on the popular GREW, Gait3D, CASIA-B, and OU-MVLP, showing that our method consistently outperforms the baselines and achieves state-of-the-art performances.
Learning-to-Rank Meets Language: Boosting Language-Driven Ordering Alignment for Ordinal Classification
Jun 24, 2023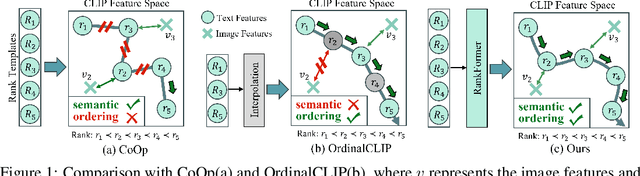
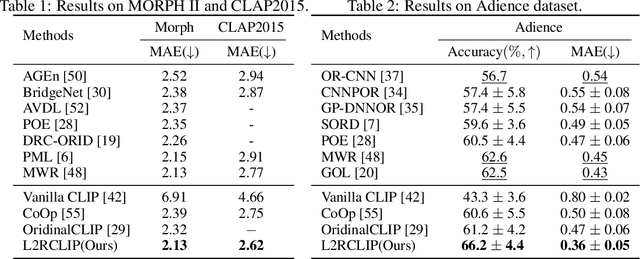

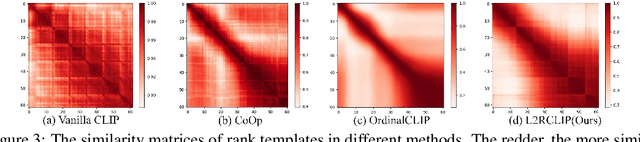
We present a novel language-driven ordering alignment method for ordinal classification. The labels in ordinal classification contain additional ordering relations, making them prone to overfitting when relying solely on training data. Recent developments in pre-trained vision-language models inspire us to leverage the rich ordinal priors in human language by converting the original task into a vision-language alignment task. Consequently, we propose L2RCLIP, which fully utilizes the language priors from two perspectives. First, we introduce a complementary prompt tuning technique called RankFormer, designed to enhance the ordering relation of original rank prompts. It employs token-level attention with residual-style prompt blending in the word embedding space. Second, to further incorporate language priors, we revisit the approximate bound optimization of vanilla cross-entropy loss and restructure it within the cross-modal embedding space. Consequently, we propose a cross-modal ordinal pairwise loss to refine the CLIP feature space, where texts and images maintain both semantic alignment and ordering alignment. Extensive experiments on three ordinal classification tasks, including facial age estimation, historical color image (HCI) classification, and aesthetic assessment demonstrate its promising performance.
Unsupervised Gait Recognition with Selective Fusion
Mar 19, 2023Previous gait recognition methods primarily trained on labeled datasets, which require painful labeling effort. However, using a pre-trained model on a new dataset without fine-tuning can lead to significant performance degradation. So to make the pre-trained gait recognition model able to be fine-tuned on unlabeled datasets, we propose a new task: Unsupervised Gait Recognition (UGR). We introduce a new cluster-based baseline to solve UGR with cluster-level contrastive learning. But we further find more challenges this task meets. First, sequences of the same person in different clothes tend to cluster separately due to the significant appearance changes. Second, sequences taken from 0 and 180 views lack walking postures and do not cluster with sequences taken from other views. To address these challenges, we propose a Selective Fusion method, which includes Selective Cluster Fusion (SCF) and Selective Sample Fusion (SSF). With SCF, we merge matched clusters of the same person wearing different clothes by updating the cluster-level memory bank with a multi-cluster update strategy. And in SSF, we merge sequences taken from front/back views gradually with curriculum learning. Extensive experiments show the effectiveness of our method in improving the rank-1 accuracy in walking with different coats condition and front/back views conditions.
CNTN: Cyclic Noise-tolerant Network for Gait Recognition
Oct 13, 2022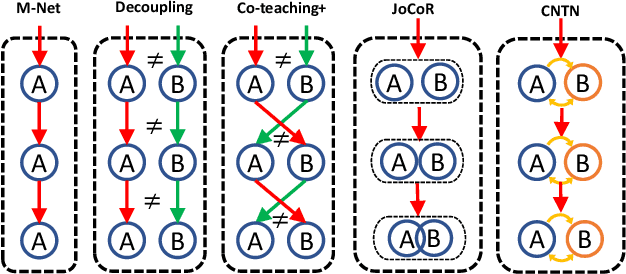
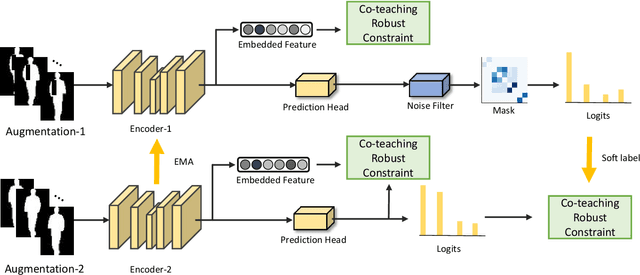
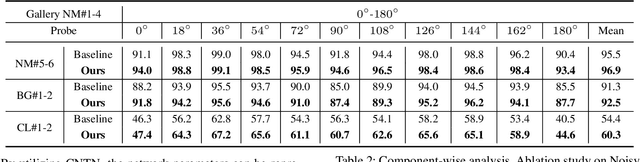
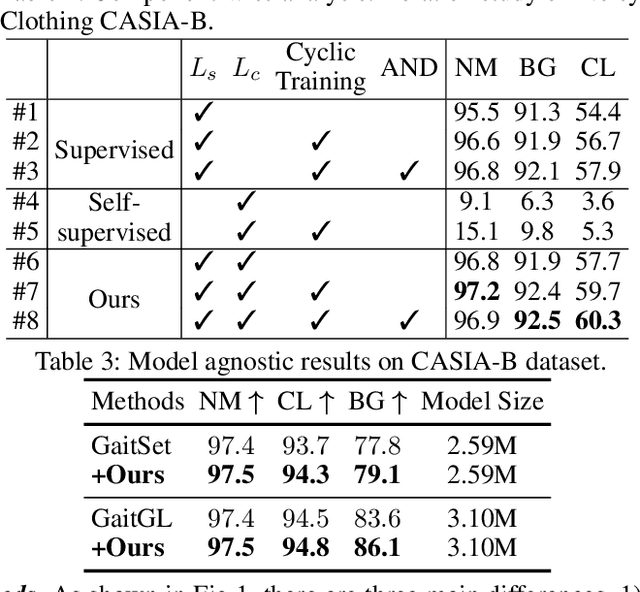
Gait recognition aims to identify individuals by recognizing their walking patterns. However, an observation is made that most of the previous gait recognition methods degenerate significantly due to two memorization effects, namely appearance memorization and label noise memorization. To address the problem, for the first time noisy gait recognition is studied, and a cyclic noise-tolerant network (CNTN) is proposed with a cyclic training algorithm, which equips the two parallel networks with explicitly different abilities, namely one forgetting network and one memorizing network. The overall model will not memorize the pattern unless the two different networks both memorize it. Further, a more refined co-teaching constraint is imposed to help the model learn intrinsic patterns which are less influenced by memorization. Also, to address label noise memorization, an adaptive noise detection module is proposed to rule out the samples with high possibility to be noisy from updating the model. Experiments are conducted on the three most popular benchmarks and CNTN achieves state-of-the-art performances. We also reconstruct two noisy gait recognition datasets, and CNTN gains significant improvements (especially 6% improvements on CL setting). CNTN is also compatible with any off-the-shelf backbones and improves them consistently.
Deep Learning-based Occluded Person Re-identification: A Survey
Jul 29, 2022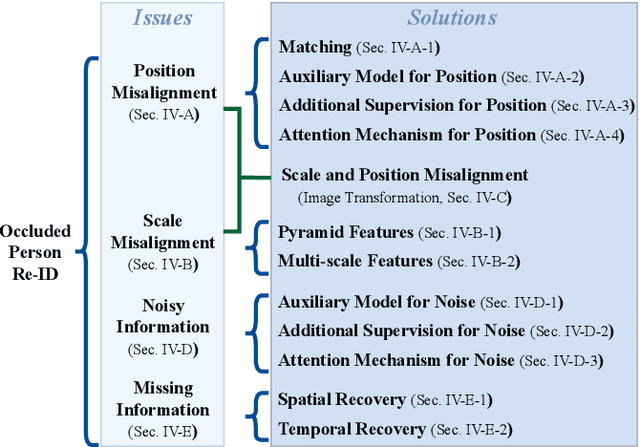
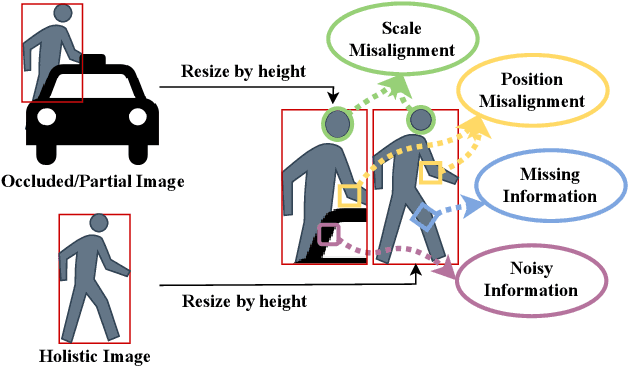

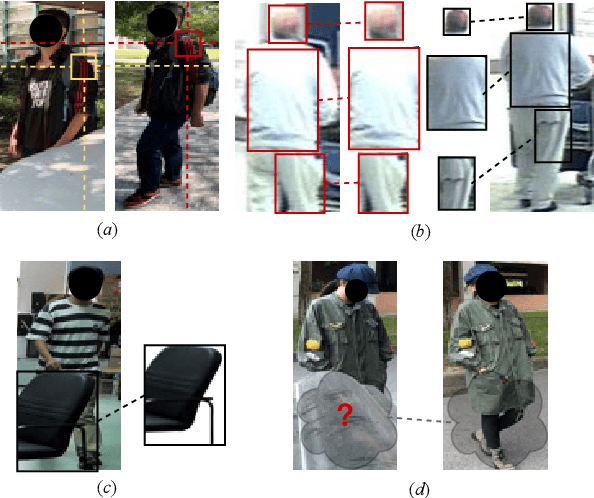
Occluded person re-identification (Re-ID) aims at addressing the occlusion problem when retrieving the person of interest across multiple cameras. With the promotion of deep learning technology and the increasing demand for intelligent video surveillance, the frequent occlusion in real-world applications has made occluded person Re-ID draw considerable interest from researchers. A large number of occluded person Re-ID methods have been proposed while there are few surveys that focus on occlusion. To fill this gap and help boost future research, this paper provides a systematic survey of occluded person Re-ID. Through an in-depth analysis of the occlusion in person Re-ID, most existing methods are found to only consider part of the problems brought by occlusion. Therefore, we review occlusion-related person Re-ID methods from the perspective of issues and solutions. We summarize four issues caused by occlusion in person Re-ID, i.e., position misalignment, scale misalignment, noisy information, and missing information. The occlusion-related methods addressing different issues are then categorized and introduced accordingly. After that, we summarize and compare the performance of recent occluded person Re-ID methods on four popular datasets: Partial-ReID, Partial-iLIDS, Occluded-ReID, and Occluded-DukeMTMC. Finally, we provide insights on promising future research directions.
Progressive Feature Learning for Realistic Cloth-Changing Gait Recognition
Jul 24, 2022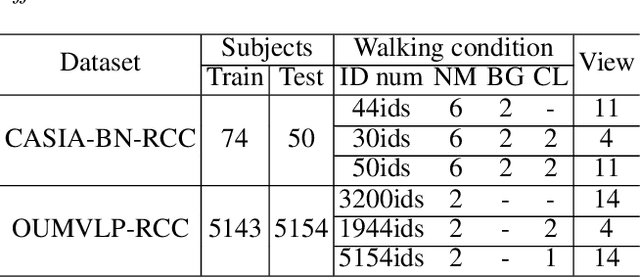
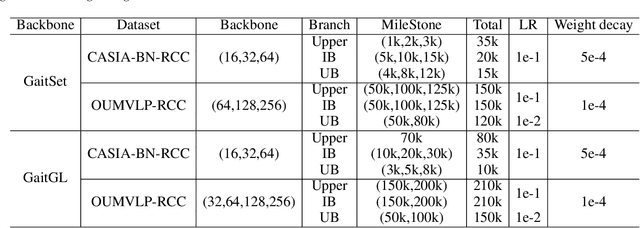
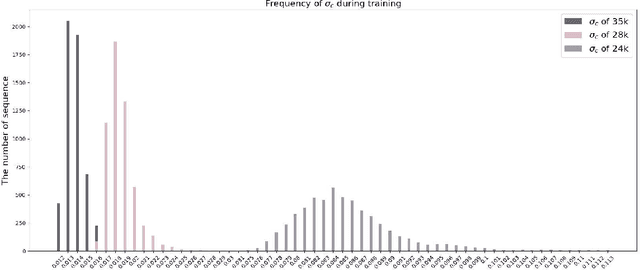
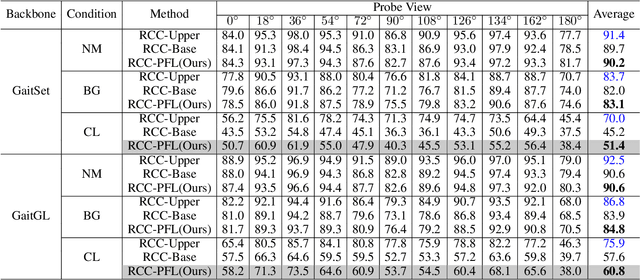
Gait recognition is instrumental in crime prevention and social security, for it can be conducted at a long distance without the cooperation of subjects. However, existing datasets and methods cannot deal with the most challenging problem in realistic gait recognition effectively: walking in different clothes (CL). In order to tackle this problem, we propose two benchmarks: CASIA-BN-RCC and OUMVLP-RCC, to simulate the cloth-changing condition in practice. The two benchmarks can force the algorithm to realize cross-view and cross-cloth with two sub-datasets. Furthermore, we propose a new framework that can be applied with off-the-shelf backbones to improve its performance in the Realistic Cloth-Changing problem with Progressive Feature Learning. Specifically, in our framework, we design Progressive Mapping and Progressive Uncertainty to extract the cross-view features and then extract cross-cloth features on the basis. In this way, the features from the cross-view sub-dataset can first dominate the feature space and relieve the uneven distribution caused by the adverse effect from the cross-cloth sub-dataset. The experiments on our benchmarks show that our framework can effectively improve the recognition performance in CL conditions. Our codes and datasets will be released after accepted.