 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollision-Free Humanoid Traversal in Cluttered Indoor Scenes
Jan 23, 2026We study the problem of collision-free humanoid traversal in cluttered indoor scenes, such as hurdling over objects scattered on the floor, crouching under low-hanging obstacles, or squeezing through narrow passages. To achieve this goal, the humanoid needs to map its perception of surrounding obstacles with diverse spatial layouts and geometries to the corresponding traversal skills. However, the lack of an effective representation that captures humanoid-obstacle relationships during collision avoidance makes directly learning such mappings difficult. We therefore propose Humanoid Potential Field (HumanoidPF), which encodes these relationships as collision-free motion directions, significantly facilitating RL-based traversal skill learning. We also find that HumanoidPF exhibits a surprisingly negligible sim-to-real gap as a perceptual representation. To further enable generalizable traversal skills through diverse and challenging cluttered indoor scenes, we further propose a hybrid scene generation method, incorporating crops of realistic 3D indoor scenes and procedurally synthesized obstacles. We successfully transfer our policy to the real world and develop a teleoperation system where users could command the humanoid to traverse in cluttered indoor scenes with just a single click. Extensive experiments are conducted in both simulation and the real world to validate the effectiveness of our method. Demos and code can be found in our website: https://axian12138.github.io/CAT/.
Track Any Motions under Any Disturbances
Sep 17, 2025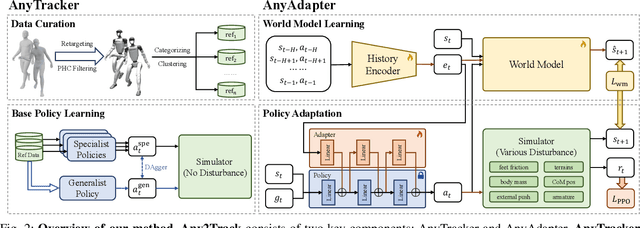

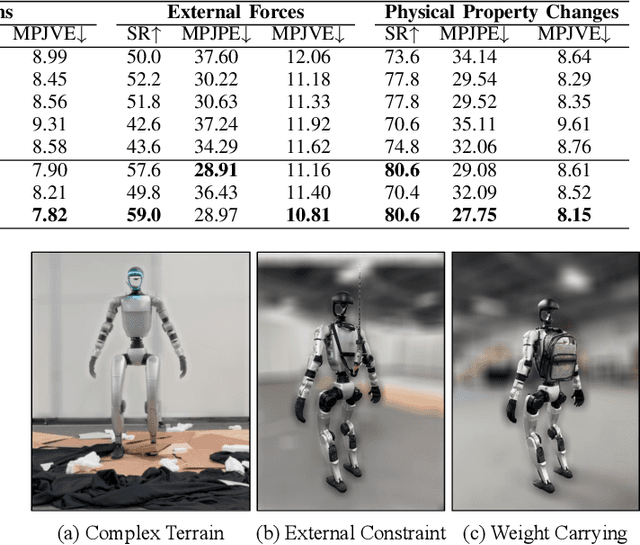

A foundational humanoid motion tracker is expected to be able to track diverse, highly dynamic, and contact-rich motions. More importantly, it needs to operate stably in real-world scenarios against various dynamics disturbances, including terrains, external forces, and physical property changes for general practical use. To achieve this goal, we propose Any2Track (Track Any motions under Any disturbances), a two-stage RL framework to track various motions under multiple disturbances in the real world. Any2Track reformulates dynamics adaptability as an additional capability on top of basic action execution and consists of two key components: AnyTracker and AnyAdapter. AnyTracker is a general motion tracker with a series of careful designs to track various motions within a single policy. AnyAdapter is a history-informed adaptation module that endows the tracker with online dynamics adaptability to overcome the sim2real gap and multiple real-world disturbances. We deploy Any2Track on Unitree G1 hardware and achieve a successful sim2real transfer in a zero-shot manner. Any2Track performs exceptionally well in tracking various motions under multiple real-world disturbances.
Exploring Generalized Gait Recognition: Reducing Redundancy and Noise within Indoor and Outdoor Datasets
May 21, 2025Generalized gait recognition, which aims to achieve robust performance across diverse domains, remains a challenging problem due to severe domain shifts in viewpoints, appearances, and environments. While mixed-dataset training is widely used to enhance generalization, it introduces new obstacles including inter-dataset optimization conflicts and redundant or noisy samples, both of which hinder effective representation learning. To address these challenges, we propose a unified framework that systematically improves cross-domain gait recognition. First, we design a disentangled triplet loss that isolates supervision signals across datasets, mitigating gradient conflicts during optimization. Second, we introduce a targeted dataset distillation strategy that filters out the least informative 20\% of training samples based on feature redundancy and prediction uncertainty, enhancing data efficiency. Extensive experiments on CASIA-B, OU-MVLP, Gait3D, and GREW demonstrate that our method significantly improves cross-dataset recognition for both GaitBase and DeepGaitV2 backbones, without sacrificing source-domain accuracy. Code will be released at https://github.com/li1er3/Generalized_Gait.
Unleashing Humanoid Reaching Potential via Real-world-Ready Skill Space
May 16, 2025Humans possess a large reachable space in the 3D world, enabling interaction with objects at varying heights and distances. However, realizing such large-space reaching on humanoids is a complex whole-body control problem and requires the robot to master diverse skills simultaneously-including base positioning and reorientation, height and body posture adjustments, and end-effector pose control. Learning from scratch often leads to optimization difficulty and poor sim2real transferability. To address this challenge, we propose Real-world-Ready Skill Space (R2S2). Our approach begins with a carefully designed skill library consisting of real-world-ready primitive skills. We ensure optimal performance and robust sim2real transfer through individual skill tuning and sim2real evaluation. These skills are then ensembled into a unified latent space, serving as a structured prior that helps task execution in an efficient and sim2real transferable manner. A high-level planner, trained to sample skills from this space, enables the robot to accomplish real-world goal-reaching tasks. We demonstrate zero-shot sim2real transfer and validate R2S2 in multiple challenging goal-reaching scenarios.
FetchBot: Object Fetching in Cluttered Shelves via Zero-Shot Sim2Real
Feb 25, 2025

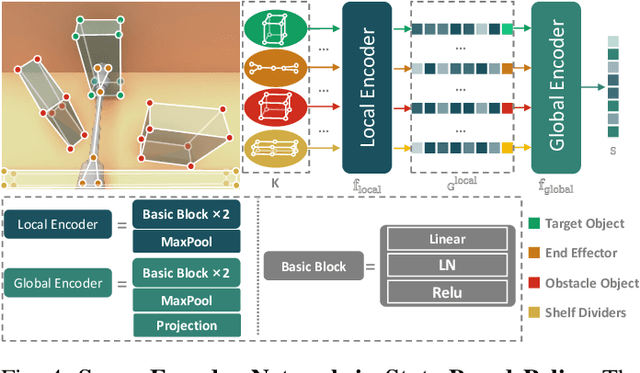
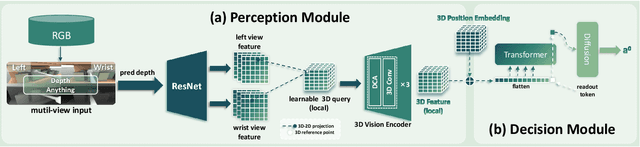
Object fetching from cluttered shelves is an important capability for robots to assist humans in real-world scenarios. Achieving this task demands robotic behaviors that prioritize safety by minimizing disturbances to surrounding objects, an essential but highly challenging requirement due to restricted motion space, limited fields of view, and complex object dynamics. In this paper, we introduce FetchBot, a sim-to-real framework designed to enable zero-shot generalizable and safety-aware object fetching from cluttered shelves in real-world settings. To address data scarcity, we propose an efficient voxel-based method for generating diverse simulated cluttered shelf scenes at scale and train a dynamics-aware reinforcement learning (RL) policy to generate object fetching trajectories within these scenes. This RL policy, which leverages oracle information, is subsequently distilled into a vision-based policy for real-world deployment. Considering that sim-to-real discrepancies stem from texture variations mostly while from geometric dimensions rarely, we propose to adopt depth information estimated by full-fledged depth foundation models as the input for the vision-based policy to mitigate sim-to-real gap. To tackle the challenge of limited views, we design a novel architecture for learning multi-view representations, allowing for comprehensive encoding of cluttered shelf scenes. This enables FetchBot to effectively minimize collisions while fetching objects from varying positions and depths, ensuring robust and safety-aware operation. Both simulation and real-robot experiments demonstrate FetchBot's superior generalization ability, particularly in handling a broad range of real-world scenarios, includ
Watch Less, Feel More: Sim-to-Real RL for Generalizable Articulated Object Manipulation via Motion Adaptation and Impedance Control
Feb 20, 2025Articulated object manipulation poses a unique challenge compared to rigid object manipulation as the object itself represents a dynamic environment. In this work, we present a novel RL-based pipeline equipped with variable impedance control and motion adaptation leveraging observation history for generalizable articulated object manipulation, focusing on smooth and dexterous motion during zero-shot sim-to-real transfer. To mitigate the sim-to-real gap, our pipeline diminishes reliance on vision by not leveraging the vision data feature (RGBD/pointcloud) directly as policy input but rather extracting useful low-dimensional data first via off-the-shelf modules. Additionally, we experience less sim-to-real gap by inferring object motion and its intrinsic properties via observation history as well as utilizing impedance control both in the simulation and in the real world. Furthermore, we develop a well-designed training setting with great randomization and a specialized reward system (task-aware and motion-aware) that enables multi-staged, end-to-end manipulation without heuristic motion planning. To the best of our knowledge, our policy is the first to report 84\% success rate in the real world via extensive experiments with various unseen objects.
MobileH2R: Learning Generalizable Human to Mobile Robot Handover Exclusively from Scalable and Diverse Synthetic Data
Jan 08, 2025



This paper introduces MobileH2R, a framework for learning generalizable vision-based human-to-mobile-robot (H2MR) handover skills. Unlike traditional fixed-base handovers, this task requires a mobile robot to reliably receive objects in a large workspace enabled by its mobility. Our key insight is that generalizable handover skills can be developed in simulators using high-quality synthetic data, without the need for real-world demonstrations. To achieve this, we propose a scalable pipeline for generating diverse synthetic full-body human motion data, an automated method for creating safe and imitation-friendly demonstrations, and an efficient 4D imitation learning method for distilling large-scale demonstrations into closed-loop policies with base-arm coordination. Experimental evaluations in both simulators and the real world show significant improvements (at least +15% success rate) over baseline methods in all cases. Experiments also validate that large-scale and diverse synthetic data greatly enhances robot learning, highlighting our scalable framework.
QuadWBG: Generalizable Quadrupedal Whole-Body Grasping
Nov 11, 2024



Legged robots with advanced manipulation capabilities have the potential to significantly improve household duties and urban maintenance. Despite considerable progress in developing robust locomotion and precise manipulation methods, seamlessly integrating these into cohesive whole-body control for real-world applications remains challenging. In this paper, we present a modular framework for robust and generalizable whole-body loco-manipulation controller based on a single arm-mounted camera. By using reinforcement learning (RL), we enable a robust low-level policy for command execution over 5 dimensions (5D) and a grasp-aware high-level policy guided by a novel metric, Generalized Oriented Reachability Map (GORM). The proposed system achieves state-of-the-art one-time grasping accuracy of 89% in the real world, including challenging tasks such as grasping transparent objects. Through extensive simulations and real-world experiments, we demonstrate that our system can effectively manage a large workspace, from floor level to above body height, and perform diverse whole-body loco-manipulation tasks.
GAMMA: Graspability-Aware Mobile MAnipulation Policy Learning based on Online Grasping Pose Fusion
Sep 27, 2023



Mobile manipulation constitutes a fundamental task for robotic assistants and garners significant attention within the robotics community. A critical challenge inherent in mobile manipulation is the effective observation of the target while approaching it for grasping. In this work, we propose a graspability-aware mobile manipulation approach powered by an online grasping pose fusion framework that enables a temporally consistent grasping observation. Specifically, the predicted grasping poses are online organized to eliminate the redundant, outlier grasping poses, which can be encoded as a grasping pose observation state for reinforcement learning. Moreover, on-the-fly fusing the grasping poses enables a direct assessment of graspability, encompassing both the quantity and quality of grasping poses.
Free Lunch for Gait Recognition: A Novel Relation Descriptor
Aug 28, 2023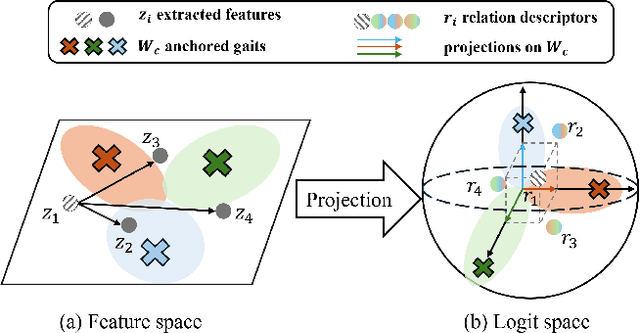
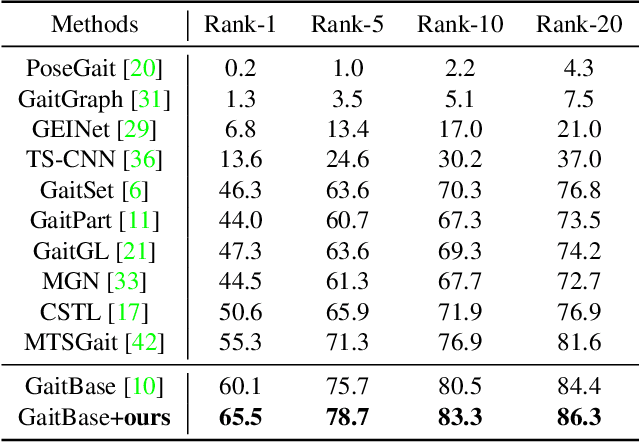
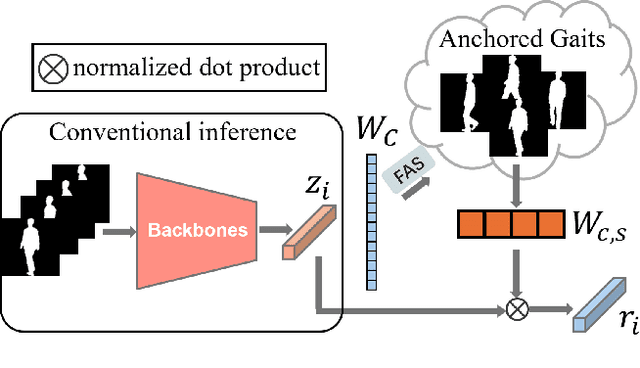
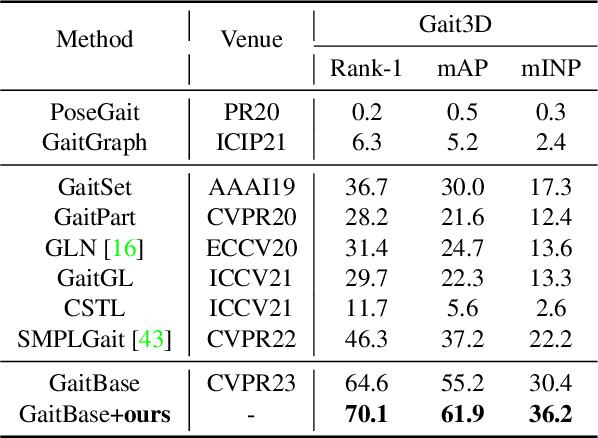
Gait recognition is to seek correct matches for query individuals by their unique walking patterns. However, current methods focus solely on extracting individual-specific features, overlooking inter-personal relationships. In this paper, we propose a novel $\textbf{Relation Descriptor}$ that captures not only individual features but also relations between test gaits and pre-selected anchored gaits. Specifically, we reinterpret classifier weights as anchored gaits and compute similarity scores between test features and these anchors, which re-expresses individual gait features into a similarity relation distribution. In essence, the relation descriptor offers a holistic perspective that leverages the collective knowledge stored within the classifier's weights, emphasizing meaningful patterns and enhancing robustness. Despite its potential, relation descriptor poses dimensionality challenges since its dimension depends on the training set's identity count. To address this, we propose the Farthest Anchored-gait Selection to identify the most discriminative anchored gaits and an Orthogonal Regularization to increase diversity within anchored gaits. Compared to individual-specific features extracted from the backbone, our relation descriptor can boost the performances nearly without any extra costs. We evaluate the effectiveness of our method on the popular GREW, Gait3D, CASIA-B, and OU-MVLP, showing that our method consistently outperforms the baselines and achieves state-of-the-art performances.