 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDouble Helix Diffusion for Cross-Domain Anomaly Image Generation
Sep 16, 2025Visual anomaly inspection is critical in manufacturing, yet hampered by the scarcity of real anomaly samples for training robust detectors. Synthetic data generation presents a viable strategy for data augmentation; however, current methods remain constrained by two principal limitations: 1) the generation of anomalies that are structurally inconsistent with the normal background, and 2) the presence of undesirable feature entanglement between synthesized images and their corresponding annotation masks, which undermines the perceptual realism of the output. This paper introduces Double Helix Diffusion (DH-Diff), a novel cross-domain generative framework designed to simultaneously synthesize high-fidelity anomaly images and their pixel-level annotation masks, explicitly addressing these challenges. DH-Diff employs a unique architecture inspired by a double helix, cycling through distinct modules for feature separation, connection, and merging. Specifically, a domain-decoupled attention mechanism mitigates feature entanglement by enhancing image and annotation features independently, and meanwhile a semantic score map alignment module ensures structural authenticity by coherently integrating anomaly foregrounds. DH-Diff offers flexible control via text prompts and optional graphical guidance. Extensive experiments demonstrate that DH-Diff significantly outperforms state-of-the-art methods in diversity and authenticity, leading to significant improvements in downstream anomaly detection performance.
StereoCarla: A High-Fidelity Driving Dataset for Generalizable Stereo
Sep 16, 2025Stereo matching plays a crucial role in enabling depth perception for autonomous driving and robotics. While recent years have witnessed remarkable progress in stereo matching algorithms, largely driven by learning-based methods and synthetic datasets, the generalization performance of these models remains constrained by the limited diversity of existing training data. To address these challenges, we present StereoCarla, a high-fidelity synthetic stereo dataset specifically designed for autonomous driving scenarios. Built on the CARLA simulator, StereoCarla incorporates a wide range of camera configurations, including diverse baselines, viewpoints, and sensor placements as well as varied environmental conditions such as lighting changes, weather effects, and road geometries. We conduct comprehensive cross-domain experiments across four standard evaluation datasets (KITTI2012, KITTI2015, Middlebury, ETH3D) and demonstrate that models trained on StereoCarla outperform those trained on 11 existing stereo datasets in terms of generalization accuracy across multiple benchmarks. Furthermore, when integrated into multi-dataset training, StereoCarla contributes substantial improvements to generalization accuracy, highlighting its compatibility and scalability. This dataset provides a valuable benchmark for developing and evaluating stereo algorithms under realistic, diverse, and controllable settings, facilitating more robust depth perception systems for autonomous vehicles. Code can be available at https://github.com/XiandaGuo/OpenStereo, and data can be available at https://xiandaguo.net/StereoCarla.
Taming Transformer Without Using Learning Rate Warmup
May 28, 2025Scaling Transformer to a large scale without using some technical tricks such as learning rate warump and using an obviously lower learning rate is an extremely challenging task, and is increasingly gaining more attention. In this paper, we provide a theoretical analysis for the process of training Transformer and reveal the rationale behind the model crash phenomenon in the training process, termed \textit{spectral energy concentration} of ${\bW_q}^{\top} \bW_k$, which is the reason for a malignant entropy collapse, where ${\bW_q}$ and $\bW_k$ are the projection matrices for the query and the key in Transformer, respectively. To remedy this problem, motivated by \textit{Weyl's Inequality}, we present a novel optimization strategy, \ie, making the weight updating in successive steps smooth -- if the ratio $\frac{\sigma_{1}(\nabla \bW_t)}{\sigma_{1}(\bW_{t-1})}$ is larger than a threshold, we will automatically bound the learning rate to a weighted multiple of $\frac{\sigma_{1}(\bW_{t-1})}{\sigma_{1}(\nabla \bW_t)}$, where $\nabla \bW_t$ is the updating quantity in step $t$. Such an optimization strategy can prevent spectral energy concentration to only a few directions, and thus can avoid malignant entropy collapse which will trigger the model crash. We conduct extensive experiments using ViT, Swin-Transformer and GPT, showing that our optimization strategy can effectively and stably train these Transformers without using learning rate warmup.
Exploring Generalized Gait Recognition: Reducing Redundancy and Noise within Indoor and Outdoor Datasets
May 21, 2025Generalized gait recognition, which aims to achieve robust performance across diverse domains, remains a challenging problem due to severe domain shifts in viewpoints, appearances, and environments. While mixed-dataset training is widely used to enhance generalization, it introduces new obstacles including inter-dataset optimization conflicts and redundant or noisy samples, both of which hinder effective representation learning. To address these challenges, we propose a unified framework that systematically improves cross-domain gait recognition. First, we design a disentangled triplet loss that isolates supervision signals across datasets, mitigating gradient conflicts during optimization. Second, we introduce a targeted dataset distillation strategy that filters out the least informative 20\% of training samples based on feature redundancy and prediction uncertainty, enhancing data efficiency. Extensive experiments on CASIA-B, OU-MVLP, Gait3D, and GREW demonstrate that our method significantly improves cross-dataset recognition for both GaitBase and DeepGaitV2 backbones, without sacrificing source-domain accuracy. Code will be released at https://github.com/li1er3/Generalized_Gait.
PIN-WM: Learning Physics-INformed World Models for Non-Prehensile Manipulation
Apr 23, 2025While non-prehensile manipulation (e.g., controlled pushing/poking) constitutes a foundational robotic skill, its learning remains challenging due to the high sensitivity to complex physical interactions involving friction and restitution. To achieve robust policy learning and generalization, we opt to learn a world model of the 3D rigid body dynamics involved in non-prehensile manipulations and use it for model-based reinforcement learning. We propose PIN-WM, a Physics-INformed World Model that enables efficient end-to-end identification of a 3D rigid body dynamical system from visual observations. Adopting differentiable physics simulation, PIN-WM can be learned with only few-shot and task-agnostic physical interaction trajectories. Further, PIN-WM is learned with observational loss induced by Gaussian Splatting without needing state estimation. To bridge Sim2Real gaps, we turn the learned PIN-WM into a group of Digital Cousins via physics-aware randomizations which perturb physics and rendering parameters to generate diverse and meaningful variations of the PIN-WM. Extensive evaluations on both simulation and real-world tests demonstrate that PIN-WM, enhanced with physics-aware digital cousins, facilitates learning robust non-prehensile manipulation skills with Sim2Real transfer, surpassing the Real2Sim2Real state-of-the-arts.
Visibility-Uncertainty-guided 3D Gaussian Inpainting via Scene Conceptional Learning
Apr 23, 20253D Gaussian Splatting (3DGS) has emerged as a powerful and efficient 3D representation for novel view synthesis. This paper extends 3DGS capabilities to inpainting, where masked objects in a scene are replaced with new contents that blend seamlessly with the surroundings. Unlike 2D image inpainting, 3D Gaussian inpainting (3DGI) is challenging in effectively leveraging complementary visual and semantic cues from multiple input views, as occluded areas in one view may be visible in others. To address this, we propose a method that measures the visibility uncertainties of 3D points across different input views and uses them to guide 3DGI in utilizing complementary visual cues. We also employ uncertainties to learn a semantic concept of scene without the masked object and use a diffusion model to fill masked objects in input images based on the learned concept. Finally, we build a novel 3DGI framework, VISTA, by integrating VISibility-uncerTainty-guided 3DGI with scene conceptuAl learning. VISTA generates high-quality 3DGS models capable of synthesizing artifact-free and naturally inpainted novel views. Furthermore, our approach extends to handling dynamic distractors arising from temporal object changes, enhancing its versatility in diverse scene reconstruction scenarios. We demonstrate the superior performance of our method over state-of-the-art techniques using two challenging datasets: the SPIn-NeRF dataset, featuring 10 diverse static 3D inpainting scenes, and an underwater 3D inpainting dataset derived from UTB180, including fast-moving fish as inpainting targets.
CogNav: Cognitive Process Modeling for Object Goal Navigation with LLMs
Dec 11, 2024



Object goal navigation (ObjectNav) is a fundamental task of embodied AI that requires the agent to find a target object in unseen environments. This task is particularly challenging as it demands both perceptual and cognitive processes for effective perception and decision-making. While perception has gained significant progress powered by the rapidly developed visual foundation models, the progress on the cognitive side remains limited to either implicitly learning from massive navigation demonstrations or explicitly leveraging pre-defined heuristic rules. Inspired by neuroscientific evidence that humans consistently update their cognitive states while searching for objects in unseen environments, we present CogNav, which attempts to model this cognitive process with the help of large language models. Specifically, we model the cognitive process with a finite state machine composed of cognitive states ranging from exploration to identification. The transitions between the states are determined by a large language model based on an online built heterogeneous cognitive map containing spatial and semantic information of the scene being explored. Extensive experiments on both synthetic and real-world environments demonstrate that our cognitive modeling significantly improves ObjectNav efficiency, with human-like navigation behaviors. In an open-vocabulary and zero-shot setting, our method advances the SOTA of the HM3D benchmark from 69.3% to 87.2%. The code and data will be released.
Stacking Brick by Brick: Aligned Feature Isolation for Incremental Face Forgery Detection
Nov 19, 2024



The rapid advancement of face forgery techniques has introduced a growing variety of forgeries. Incremental Face Forgery Detection (IFFD), involving gradually adding new forgery data to fine-tune the previously trained model, has been introduced as a promising strategy to deal with evolving forgery methods. However, a naively trained IFFD model is prone to catastrophic forgetting when new forgeries are integrated, as treating all forgeries as a single ''Fake" class in the Real/Fake classification can cause different forgery types overriding one another, thereby resulting in the forgetting of unique characteristics from earlier tasks and limiting the model's effectiveness in learning forgery specificity and generality. In this paper, we propose to stack the latent feature distributions of previous and new tasks brick by brick, $\textit{i.e.}$, achieving $\textbf{aligned feature isolation}$. In this manner, we aim to preserve learned forgery information and accumulate new knowledge by minimizing distribution overriding, thereby mitigating catastrophic forgetting. To achieve this, we first introduce Sparse Uniform Replay (SUR) to obtain the representative subsets that could be treated as the uniformly sparse versions of the previous global distributions. We then propose a Latent-space Incremental Detector (LID) that leverages SUR data to isolate and align distributions. For evaluation, we construct a more advanced and comprehensive benchmark tailored for IFFD. The leading experimental results validate the superiority of our method.
Co-Fix3D: Enhancing 3D Object Detection with Collaborative Refinement
Aug 15, 2024In the realm of autonomous driving,accurately detecting occluded or distant objects,referred to as weak positive sample ,presents significant challenges. These challenges predominantly arise during query initialization, where an over-reliance on heatmap confidence often results in a high rate of false positives, consequently masking weaker detections and impairing system performance. To alleviate this issue, we propose a novel approach, Co-Fix3D, which employs a collaborative hybrid multi-stage parallel query generation mechanism for BEV representations. Our method incorporates the Local-Global Feature Enhancement (LGE) module, which refines BEV features to more effectively highlight weak positive samples. It uniquely leverages the Discrete Wavelet Transform (DWT) for accurate noise reduction and features refinement in localized areas, and incorporates an attention mechanism to more comprehensively optimize global BEV features. Moreover, our method increases the volume of BEV queries through a multi-stage parallel processing of the LGE, significantly enhancing the probability of selecting weak positive samples. This enhancement not only improves training efficiency within the decoder framework but also boosts overall system performance. Notably, Co-Fix3D achieves superior results on the stringent nuScenes benchmark, outperforming all previous models with a 69.1% mAP and 72.9% NDS on the LiDAR-based benchmark, and 72.3% mAP and 74.1% NDS on the multi-modality benchmark, without relying on test-time augmentation or additional datasets. The source code will be made publicly available upon acceptance.
ED$^4$: Explicit Data-level Debiasing for Deepfake Detection
Aug 13, 2024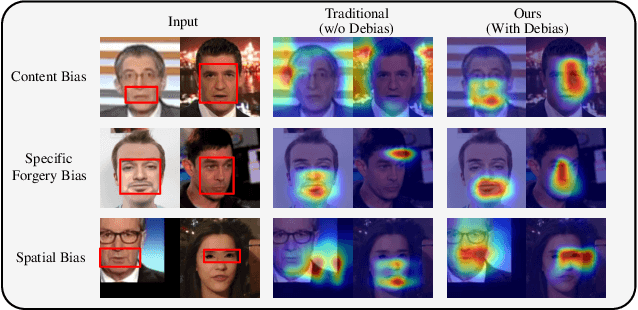
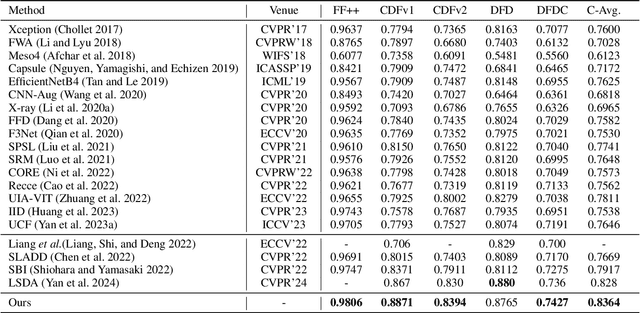
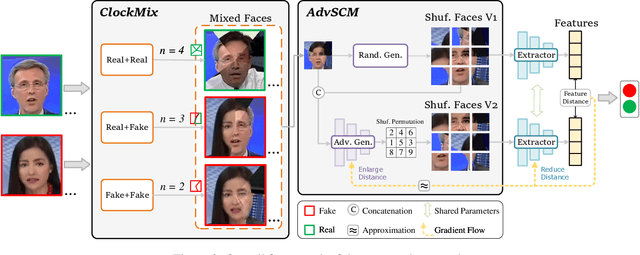

Learning intrinsic bias from limited data has been considered the main reason for the failure of deepfake detection with generalizability. Apart from the discovered content and specific-forgery bias, we reveal a novel spatial bias, where detectors inertly anticipate observing structural forgery clues appearing at the image center, also can lead to the poor generalization of existing methods. We present ED$^4$, a simple and effective strategy, to address aforementioned biases explicitly at the data level in a unified framework rather than implicit disentanglement via network design. In particular, we develop ClockMix to produce facial structure preserved mixtures with arbitrary samples, which allows the detector to learn from an exponentially extended data distribution with much more diverse identities, backgrounds, local manipulation traces, and the co-occurrence of multiple forgery artifacts. We further propose the Adversarial Spatial Consistency Module (AdvSCM) to prevent extracting features with spatial bias, which adversarially generates spatial-inconsistent images and constrains their extracted feature to be consistent. As a model-agnostic debiasing strategy, ED$^4$ is plug-and-play: it can be integrated with various deepfake detectors to obtain significant benefits. We conduct extensive experiments to demonstrate its effectiveness and superiority over existing deepfake detection approaches.