 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchX: Benchmarking AI Models for Cancer Detection and Localization with Demographic and Protocol Biases
Jun 23, 2026Artificial intelligence (AI) has achieved remarkable success in medical imaging, but it is widely recognized that these models often perform inconsistently across real-world clinical settings. Such inconsistencies occur when patient demographics and imaging protocols vary, for example, in detecting small tumors, analyzing scans from different contrast phases, or evaluating patients of different ages or sexes. To quantify these inconsistencies, we develop a large-scale, open benchmark of 85,355 CT scans that systematically evaluates 12 tumor-detection AI models across tumor size, location, patient subgroup, and imaging protocol. We leverage large language models (LLMs) to extract and organize subgroup information from clinical data, which makes the analysis both scalable and reproducible. Our benchmark reveals that current state-of-the-art AI models, optimized for average accuracy, perform poorly in rare or underrepresented subgroups, such as young, female African Americans. However, collecting sufficient annotated data for these rare cases is often impractical. The benchmark provides a foundation for building more reliable and robust AI models for tumor detection and highlighting the need for rigorous, subgroup-level evaluation in medical imaging and computer vision. Datasets, code
DuMate-DeepResearch: An Auditable Multi-Agent System with Recursive Search and Rubric-Grounded Reasoning
Jun 05, 2026Deep Research (DR) has emerged as a new agentic paradigm to tackle complex, open-ended research tasks, demanding systems that can iteratively frame problems, acquire evidence, verify sources, and synthesize long-form reports. In practice, however, current DR systems are constrained by four interrelated limitations: long-horizon planning over an underspecified scope, the bottleneck of decomposing and scheduling such tasks within a single agent, hallucination risk in long-form synthesis, and limited process auditability. This technical report presents DuMate-DeepResearch, a multi-agent DR framework built on the Qianfan Agent Foundry. The framework decouples the Agent Core, which handles task understanding, planning, and scheduling, from an extensible Tool Ecosystem for retrieval, evidence acquisition, and report rendering, making every intermediate decision and tool invocation explicitly traceable. Building on this infrastructure, DuMate-DeepResearch further introduces three mechanisms: (i) a graph-based dynamic planning strategy expands the research roadmap coarse-to-fine and continuously revises it through reflection, re-planning, backtracking, and parallel branching; (ii) a recursive two-level execution design delegates each complex search sub-task to an inner Search Agent that runs its own planning loop, isolating noisy retrieval and stabilizing long-horizon execution; (iii) a rubric-based test-time optimization mechanism dynamically generates task-specific quality criteria and uses them as live reasoning scaffolds for evidence-grounded synthesis and adaptive stopping. Across two deep research benchmarks, DuMate-DeepResearch establishes new state-of-the-art results: the best overall score (58.03%) on DeepResearch Bench, and the best overall score (61.95%) on DeepResearch Bench II while ranking first in information recall and analysis.
Co-Fusion4D: Spatio-temporal Collaborative Fusion for Robust 3D Object Detection
May 19, 2026In autonomous driving, 3D object detection is essential for accurate perception and reliable decision-making. However, object motion and ego-motion often induce cross-frame spatiotemporal inconsistencies in BEV-based detectors, leading to temporal BEV feature misalignment and degraded spatiotemporal consistency. To address these challenges, we propose Co-Fusion4D, a unified framework that explicitly preserves cross-frame spatiotemporal consistency and suppresses temporal feature drift. Co-Fusion4D adopts a current-frame-centric strategy, treating the current frame as the primary source of information while selectively incorporating historical frames after spatiotemporal filtering and alignment. This dominant-complementary mechanism effectively mitigates cumulative alignment errors, suppresses noisy feature propagation, and exploits reliable temporal cues for a more consistent BEV representation. In addition, Co-Fusion4D integrates a Dual Attention Fusion (DAF) module to further enhance spatiotemporal feature interaction. DAF jointly leverages intra-frame spatial attention and inter-frame temporal attention to adaptively align and fuse multi-frame features, emphasizing motion-consistent regions while suppressing spurious correlations. By departing from conventional uniform fusion paradigms, this design substantially improves the temporal stability and discriminative capability of BEV representations. Extensive experiments on the nuScenes benchmark demonstrate that Co-Fusion4D achieves state-of-the-art performance, with 74.9% mAP and 75.6% NDS, without relying on test-time augmentation or external data.
RadThinking: A Dataset for Longitudinal Clinical Reasoning in Radiology
May 11, 2026Cancer screening is a reasoning task. A radiologist observes findings, compares them to prior scans, integrates clinical context, and reaches a diagnostic conclusion confirmed by pathology. We present RadThinking, a Visual Question Answering (VQA) dataset that makes this reasoning explicit and trainable. RadThinking releases VQA pairs at three difficulty tiers. Foundation VQAs are atomic perception questions. Single-step reasoning VQAs apply one clinical rule. Compositional VQAs require multi-step chain-of-thought to reach a guideline category such as LI-RADS-5. For every compositional VQA, we release the chain of foundation VQAs that solves it. The chain follows the rules of the governing clinical reporting standard. The dataset spans 20,362 CT scans from 9,131 patients across 43 cancer groups, plus 2,077 verified healthy controls with >1-year follow-up. To our knowledge, RadThinking is the first cancer-screening VQA corpus that stratifies questions by reasoning depth and grounds compositions in clinical reporting standards. The foundation tier supplies atomic perception supervision. The compositional tier supplies chain-of-thought data and verifiable rewards for reinforcement-learning recipes such as DeepSeek-R1 and OpenAI o1. RadThinking enables systematic training and evaluation of whether AI systems can reason about cancer, not merely detect it.
From Anchors to Supervision: Memory-Graph Guided Corpus-Free Unlearning for Large Language Models
Apr 15, 2026Large language models (LLMs) may memorize sensitive or copyrighted content, raising significant privacy and legal concerns. While machine unlearning has emerged as a potential remedy, prevailing paradigms rely on user-provided forget sets, making unlearning requests difficult to audit and exposing systems to secondary leakage and malicious abuse. We propose MAGE, a Memory-grAph Guided Erasure framework for user-minimized, corpus-free unlearning. Given only a lightweight user anchor that identifies a target entity, MAGE probes the target LLM to recover target-related memorization, organizes it into a weighted local memory graph, and synthesizes scoped supervision for unlearning. MAGE is model-agnostic, can be plugged into standard unlearning methods, and requires no access to the original training corpus. Experiments on two benchmarks, TOFU and RWKU, demonstrate that MAGE's self-generated supervision achieves effective unlearning performance comparable to supervision generated with external reference, while preserving overall utility. These results support a practical and auditable unlearning workflow driven by minimal anchors rather than user-supplied forget corpora.
CLASP: Closed-loop Asynchronous Spatial Perception for Open-vocabulary Desktop Object Grasping
Apr 13, 2026Robot grasping of desktop object is widely used in intelligent manufacturing, logistics, and agriculture.Although vision-language models (VLMs) show strong potential for robotic manipulation, their deployment in low-level grasping faces key challenges: scarce high-quality multimodal demonstrations, spatial hallucination caused by weak geometric grounding, and the fragility of open-loop execution in dynamic environments. To address these challenges, we propose Closed-Loop Asynchronous Spatial Perception(CLASP), a novel asynchronous closed-loop framework that integrates multimodal perception, logical reasoning, and state-reflective feedback. First, we design a Dual-Pathway Hierarchical Perception module that decouples high-level semantic intent from geometric grounding. The design guides the output of the inference model and the definite action tuples, reducing spatial illusions. Second, an Asynchronous Closed-Loop Evaluator is implemented to compare pre- and post-execution states, providing text-based diagnostic feedback to establish a robust error-correction loop and improving the vulnerability of traditional open-loop execution in dynamic environments. Finally, we design a scalable multi-modal data engine that automatically synthesizes high-quality spatial annotations and reasoning templates from real and synthetic scenes without human teleoperation. Extensive experiments demonstrate that our approach significantly outperforms existing baselines, achieving an 87.0% overall success rate. Notably, the proposed framework exhibits remarkable generalization across diverse objects, bridging the sim-to-real gap and providing exceptional robustness in geometrically challenging categories and cluttered scenarios.
Distilling Photon-Counting CT into Routine Chest CT through Clinically Validated Degradation Modeling
Apr 08, 2026Photon-counting CT (PCCT) provides superior image quality with higher spatial resolution and lower noise compared to conventional energy-integrating CT (EICT), but its limited clinical availability restricts large-scale research and clinical deployment. To bridge this gap, we propose SUMI, a simulated degradation-to-enhancement method that learns to reverse realistic acquisition artifacts in low-quality EICT by leveraging high-quality PCCT as reference. Our central insight is to explicitly model realistic acquisition degradations, transforming PCCT into clinically plausible lower-quality counterparts and learning to invert this process. The simulated degradations were validated for clinical realism by board-certified radiologists, enabling faithful supervision without requiring paired acquisitions at scale. As outcomes of this technical contribution, we: (1) train a latent diffusion model on 1,046 PCCTs, using an autoencoder first pre-trained on both these PCCTs and 405,379 EICTs from 145 hospitals to extract general CT latent features that we release for reuse in other generative medical imaging tasks; (2) construct a large-scale dataset of over 17,316 publicly available EICTs enhanced to PCCT-like quality, with radiologist-validated voxel-wise annotations of airway trees, arteries, veins, lungs, and lobes; and (3) demonstrate substantial improvements: across external data, SUMI outperforms state-of-the-art image translation methods by 15% in SSIM and 20% in PSNR, improves radiologist-rated clinical utility in reader studies, and enhances downstream top-ranking lesion detection performance, increasing sensitivity by up to 15% and F1 score by up to 10%. Our results suggest that emerging imaging advances can be systematically distilled into routine EICT using limited high-quality scans as reference.
Early and Prediagnostic Detection of Pancreatic Cancer from Computed Tomography
Jan 29, 2026Pancreatic ductal adenocarcinoma (PDAC), one of the deadliest solid malignancies, is often detected at a late and inoperable stage. Retrospective reviews of prediagnostic CT scans, when conducted by expert radiologists aware that the patient later developed PDAC, frequently reveal lesions that were previously overlooked. To help detecting these lesions earlier, we developed an automated system named ePAI (early Pancreatic cancer detection with Artificial Intelligence). It was trained on data from 1,598 patients from a single medical center. In the internal test involving 1,009 patients, ePAI achieved an area under the receiver operating characteristic curve (AUC) of 0.939-0.999, a sensitivity of 95.3%, and a specificity of 98.7% for detecting small PDAC less than 2 cm in diameter, precisely localizing PDAC as small as 2 mm. In an external test involving 7,158 patients across 6 centers, ePAI achieved an AUC of 0.918-0.945, a sensitivity of 91.5%, and a specificity of 88.0%, precisely localizing PDAC as small as 5 mm. Importantly, ePAI detected PDACs on prediagnostic CT scans obtained 3 to 36 months before clinical diagnosis that had originally been overlooked by radiologists. It successfully detected and localized PDACs in 75 of 159 patients, with a median lead time of 347 days before clinical diagnosis. Our multi-reader study showed that ePAI significantly outperformed 30 board-certified radiologists by 50.3% (P < 0.05) in sensitivity while maintaining a comparable specificity of 95.4% in detecting PDACs early and prediagnostic. These findings suggest its potential of ePAI as an assistive tool to improve early detection of pancreatic cancer.
Large-Scale Label Quality Assessment for Medical Segmentation via a Vision-Language Judge and Synthetic Data
Jan 20, 2026Large-scale medical segmentation datasets often combine manual and pseudo-labels of uneven quality, which can compromise training and evaluation. Low-quality labels may hamper performance and make the model training less robust. To address this issue, we propose SegAE (Segmentation Assessment Engine), a lightweight vision-language model (VLM) that automatically predicts label quality across 142 anatomical structures. Trained on over four million image-label pairs with quality scores, SegAE achieves a high correlation coefficient of 0.902 with ground-truth Dice similarity and evaluates a 3D mask in 0.06s. SegAE shows several practical benefits: (I) Our analysis reveals widespread low-quality labeling across public datasets; (II) SegAE improves data efficiency and training performance in active and semi-supervised learning, reducing dataset annotation cost by one-third and quality-checking time by 70% per label. This tool provides a simple and effective solution for quality control in large-scale medical segmentation datasets. The dataset, model weights, and codes are released at https://github.com/Schuture/SegAE.
Auditing Significance, Metric Choice, and Demographic Fairness in Medical AI Challenges
Dec 22, 2025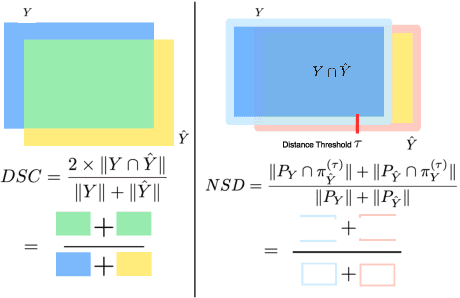
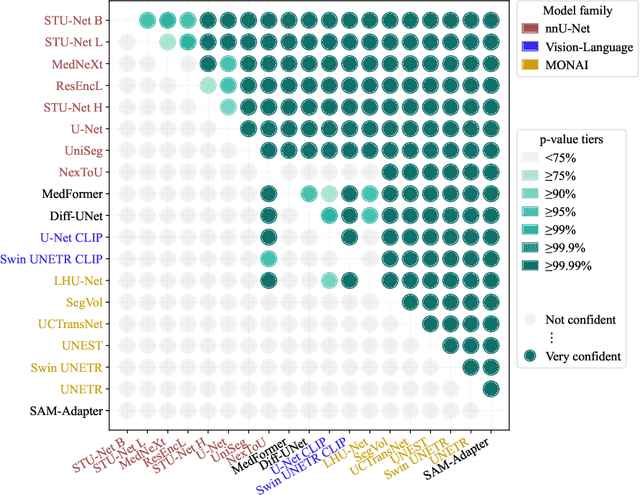
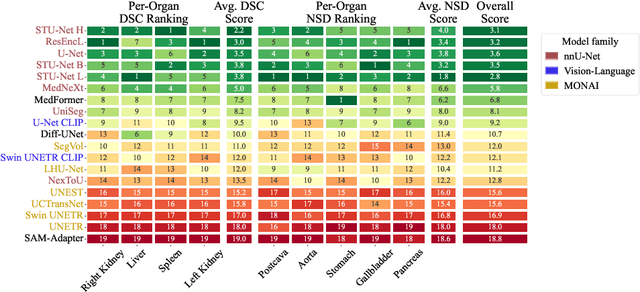
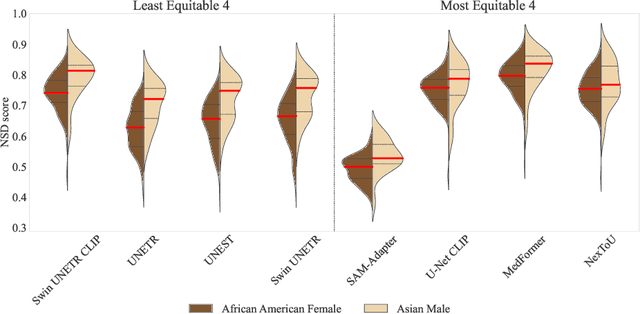
Open challenges have become the de facto standard for comparative ranking of medical AI methods. Despite their importance, medical AI leaderboards exhibit three persistent limitations: (1) score gaps are rarely tested for statistical significance, so rank stability is unknown; (2) single averaged metrics are applied to every organ, hiding clinically important boundary errors; (3) performance across intersecting demographics is seldom reported, masking fairness and equity gaps. We introduce RankInsight, an open-source toolkit that seeks to address these limitations. RankInsight (1) computes pair-wise significance maps that show the nnU-Net family outperforms Vision-Language and MONAI submissions with high statistical certainty; (2) recomputes leaderboards with organ-appropriate metrics, reversing the order of the top four models when Dice is replaced by NSD for tubular structures; and (3) audits intersectional fairness, revealing that more than half of the MONAI-based entries have the largest gender-race discrepancy on our proprietary Johns Hopkins Hospital dataset. The RankInsight toolkit is publicly released and can be directly applied to past, ongoing, and future challenges. It enables organizers and participants to publish rankings that are statistically sound, clinically meaningful, and demographically fair.