 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfiniDepth: Arbitrary-Resolution and Fine-Grained Depth Estimation with Neural Implicit Fields
Jan 06, 2026Existing depth estimation methods are fundamentally limited to predicting depth on discrete image grids. Such representations restrict their scalability to arbitrary output resolutions and hinder the geometric detail recovery. This paper introduces InfiniDepth, which represents depth as neural implicit fields. Through a simple yet effective local implicit decoder, we can query depth at continuous 2D coordinates, enabling arbitrary-resolution and fine-grained depth estimation. To better assess our method's capabilities, we curate a high-quality 4K synthetic benchmark from five different games, spanning diverse scenes with rich geometric and appearance details. Extensive experiments demonstrate that InfiniDepth achieves state-of-the-art performance on both synthetic and real-world benchmarks across relative and metric depth estimation tasks, particularly excelling in fine-detail regions. It also benefits the task of novel view synthesis under large viewpoint shifts, producing high-quality results with fewer holes and artifacts.
ZeroDexGrasp: Zero-Shot Task-Oriented Dexterous Grasp Synthesis with Prompt-Based Multi-Stage Semantic Reasoning
Nov 17, 2025Task-oriented dexterous grasping holds broad application prospects in robotic manipulation and human-object interaction. However, most existing methods still struggle to generalize across diverse objects and task instructions, as they heavily rely on costly labeled data to ensure task-specific semantic alignment. In this study, we propose \textbf{ZeroDexGrasp}, a zero-shot task-oriented dexterous grasp synthesis framework integrating Multimodal Large Language Models with grasp refinement to generate human-like grasp poses that are well aligned with specific task objectives and object affordances. Specifically, ZeroDexGrasp employs prompt-based multi-stage semantic reasoning to infer initial grasp configurations and object contact information from task and object semantics, then exploits contact-guided grasp optimization to refine these poses for physical feasibility and task alignment. Experimental results demonstrate that ZeroDexGrasp enables high-quality zero-shot dexterous grasping on diverse unseen object categories and complex task requirements, advancing toward more generalizable and intelligent robotic grasping.
Towards Depth Foundation Model: Recent Trends in Vision-Based Depth Estimation
Jul 15, 2025Depth estimation is a fundamental task in 3D computer vision, crucial for applications such as 3D reconstruction, free-viewpoint rendering, robotics, autonomous driving, and AR/VR technologies. Traditional methods relying on hardware sensors like LiDAR are often limited by high costs, low resolution, and environmental sensitivity, limiting their applicability in real-world scenarios. Recent advances in vision-based methods offer a promising alternative, yet they face challenges in generalization and stability due to either the low-capacity model architectures or the reliance on domain-specific and small-scale datasets. The emergence of scaling laws and foundation models in other domains has inspired the development of "depth foundation models": deep neural networks trained on large datasets with strong zero-shot generalization capabilities. This paper surveys the evolution of deep learning architectures and paradigms for depth estimation across the monocular, stereo, multi-view, and monocular video settings. We explore the potential of these models to address existing challenges and provide a comprehensive overview of large-scale datasets that can facilitate their development. By identifying key architectures and training strategies, we aim to highlight the path towards robust depth foundation models, offering insights into their future research and applications.
LaDi-WM: A Latent Diffusion-based World Model for Predictive Manipulation
May 13, 2025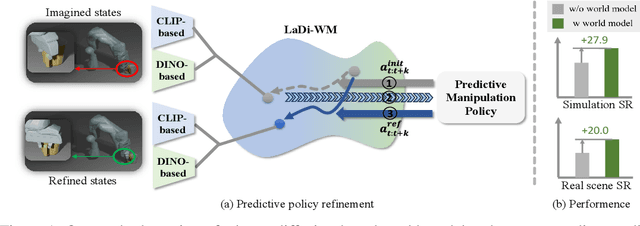
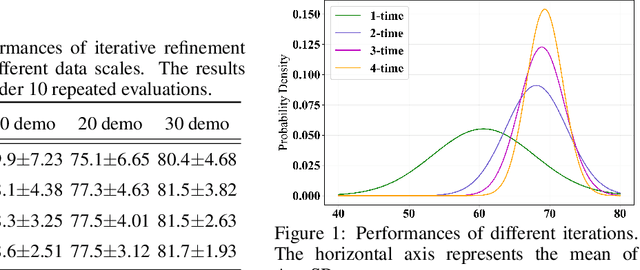

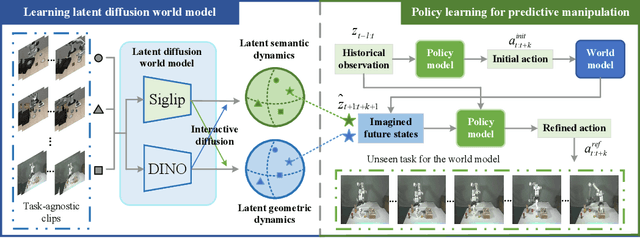
Predictive manipulation has recently gained considerable attention in the Embodied AI community due to its potential to improve robot policy performance by leveraging predicted states. However, generating accurate future visual states of robot-object interactions from world models remains a well-known challenge, particularly in achieving high-quality pixel-level representations. To this end, we propose LaDi-WM, a world model that predicts the latent space of future states using diffusion modeling. Specifically, LaDi-WM leverages the well-established latent space aligned with pre-trained Visual Foundation Models (VFMs), which comprises both geometric features (DINO-based) and semantic features (CLIP-based). We find that predicting the evolution of the latent space is easier to learn and more generalizable than directly predicting pixel-level images. Building on LaDi-WM, we design a diffusion policy that iteratively refines output actions by incorporating forecasted states, thereby generating more consistent and accurate results. Extensive experiments on both synthetic and real-world benchmarks demonstrate that LaDi-WM significantly enhances policy performance by 27.9\% on the LIBERO-LONG benchmark and 20\% on the real-world scenario. Furthermore, our world model and policies achieve impressive generalizability in real-world experiments.
PIN-WM: Learning Physics-INformed World Models for Non-Prehensile Manipulation
Apr 23, 2025While non-prehensile manipulation (e.g., controlled pushing/poking) constitutes a foundational robotic skill, its learning remains challenging due to the high sensitivity to complex physical interactions involving friction and restitution. To achieve robust policy learning and generalization, we opt to learn a world model of the 3D rigid body dynamics involved in non-prehensile manipulations and use it for model-based reinforcement learning. We propose PIN-WM, a Physics-INformed World Model that enables efficient end-to-end identification of a 3D rigid body dynamical system from visual observations. Adopting differentiable physics simulation, PIN-WM can be learned with only few-shot and task-agnostic physical interaction trajectories. Further, PIN-WM is learned with observational loss induced by Gaussian Splatting without needing state estimation. To bridge Sim2Real gaps, we turn the learned PIN-WM into a group of Digital Cousins via physics-aware randomizations which perturb physics and rendering parameters to generate diverse and meaningful variations of the PIN-WM. Extensive evaluations on both simulation and real-world tests demonstrate that PIN-WM, enhanced with physics-aware digital cousins, facilitates learning robust non-prehensile manipulation skills with Sim2Real transfer, surpassing the Real2Sim2Real state-of-the-arts.
MASH: Masked Anchored SpHerical Distances for 3D Shape Representation and Generation
Apr 12, 2025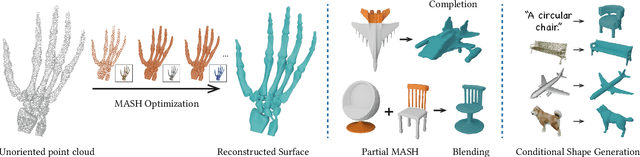
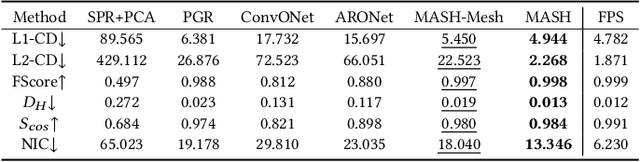
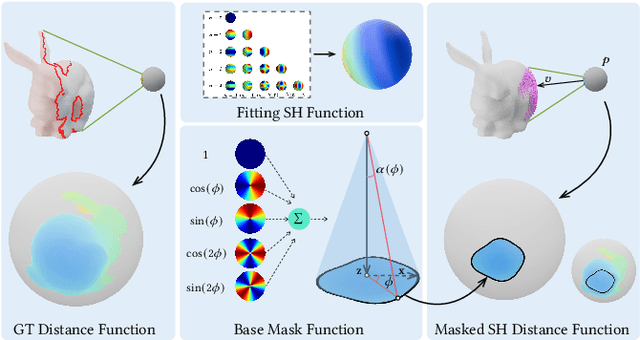

We introduce Masked Anchored SpHerical Distances (MASH), a novel multi-view and parametrized representation of 3D shapes. Inspired by multi-view geometry and motivated by the importance of perceptual shape understanding for learning 3D shapes, MASH represents a 3D shape as a collection of observable local surface patches, each defined by a spherical distance function emanating from an anchor point. We further leverage the compactness of spherical harmonics to encode the MASH functions, combined with a generalized view cone with a parameterized base that masks the spatial extent of the spherical function to attain locality. We develop a differentiable optimization algorithm capable of converting any point cloud into a MASH representation accurately approximating ground-truth surfaces with arbitrary geometry and topology. Extensive experiments demonstrate that MASH is versatile for multiple applications including surface reconstruction, shape generation, completion, and blending, achieving superior performance thanks to its unique representation encompassing both implicit and explicit features.
BoxDreamer: Dreaming Box Corners for Generalizable Object Pose Estimation
Apr 10, 2025This paper presents a generalizable RGB-based approach for object pose estimation, specifically designed to address challenges in sparse-view settings. While existing methods can estimate the poses of unseen objects, their generalization ability remains limited in scenarios involving occlusions and sparse reference views, restricting their real-world applicability. To overcome these limitations, we introduce corner points of the object bounding box as an intermediate representation of the object pose. The 3D object corners can be reliably recovered from sparse input views, while the 2D corner points in the target view are estimated through a novel reference-based point synthesizer, which works well even in scenarios involving occlusions. As object semantic points, object corners naturally establish 2D-3D correspondences for object pose estimation with a PnP algorithm. Extensive experiments on the YCB-Video and Occluded-LINEMOD datasets show that our approach outperforms state-of-the-art methods, highlighting the effectiveness of the proposed representation and significantly enhancing the generalization capabilities of object pose estimation, which is crucial for real-world applications.
Glossy Object Reconstruction with Cost-effective Polarized Acquisition
Apr 09, 2025



The challenge of image-based 3D reconstruction for glossy objects lies in separating diffuse and specular components on glossy surfaces from captured images, a task complicated by the ambiguity in discerning lighting conditions and material properties using RGB data alone. While state-of-the-art methods rely on tailored and/or high-end equipment for data acquisition, which can be cumbersome and time-consuming, this work introduces a scalable polarization-aided approach that employs cost-effective acquisition tools. By attaching a linear polarizer to readily available RGB cameras, multi-view polarization images can be captured without the need for advance calibration or precise measurements of the polarizer angle, substantially reducing system construction costs. The proposed approach represents polarimetric BRDF, Stokes vectors, and polarization states of object surfaces as neural implicit fields. These fields, combined with the polarizer angle, are retrieved by optimizing the rendering loss of input polarized images. By leveraging fundamental physical principles for the implicit representation of polarization rendering, our method demonstrates superiority over existing techniques through experiments in public datasets and real captured images on both reconstruction and novel view synthesis.
Deliberate Planning of 3D Bin Packing on Packing Configuration Trees
Apr 06, 2025Online 3D Bin Packing Problem (3D-BPP) has widespread applications in industrial automation. Existing methods usually solve the problem with limited resolution of spatial discretization, and/or cannot deal with complex practical constraints well. We propose to enhance the practical applicability of online 3D-BPP via learning on a novel hierarchical representation, packing configuration tree (PCT). PCT is a full-fledged description of the state and action space of bin packing which can support packing policy learning based on deep reinforcement learning (DRL). The size of the packing action space is proportional to the number of leaf nodes, making the DRL model easy to train and well-performing even with continuous solution space. We further discover the potential of PCT as tree-based planners in deliberately solving packing problems of industrial significance, including large-scale packing and different variations of BPP setting. A recursive packing method is proposed to decompose large-scale packing into smaller sub-trees while a spatial ensemble mechanism integrates local solutions into global. For different BPP variations with additional decision variables, such as lookahead, buffering, and offline packing, we propose a unified planning framework enabling out-of-the-box problem solving. Extensive evaluations demonstrate that our method outperforms existing online BPP baselines and is versatile in incorporating various practical constraints. The planning process excels across large-scale problems and diverse problem variations. We develop a real-world packing robot for industrial warehousing, with careful designs accounting for constrained placement and transportation stability. Our packing robot operates reliably and efficiently on unprotected pallets at 10 seconds per box. It achieves averagely 19 boxes per pallet with 57.4% space utilization for relatively large-size boxes.
G-DexGrasp: Generalizable Dexterous Grasping Synthesis Via Part-Aware Prior Retrieval and Prior-Assisted Generation
Mar 25, 2025



Recent advances in dexterous grasping synthesis have demonstrated significant progress in producing reasonable and plausible grasps for many task purposes. But it remains challenging to generalize to unseen object categories and diverse task instructions. In this paper, we propose G-DexGrasp, a retrieval-augmented generation approach that can produce high-quality dexterous hand configurations for unseen object categories and language-based task instructions. The key is to retrieve generalizable grasping priors, including the fine-grained contact part and the affordance-related distribution of relevant grasping instances, for the following synthesis pipeline. Specifically, the fine-grained contact part and affordance act as generalizable guidance to infer reasonable grasping configurations for unseen objects with a generative model, while the relevant grasping distribution plays as regularization to guarantee the plausibility of synthesized grasps during the subsequent refinement optimization. Our comparison experiments validate the effectiveness of our key designs for generalization and demonstrate the remarkable performance against the existing approaches. Project page: https://g-dexgrasp.github.io/