 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnityVideo: Unified Multi-Modal Multi-Task Learning for Enhancing World-Aware Video Generation
Dec 08, 2025Recent video generation models demonstrate impressive synthesis capabilities but remain limited by single-modality conditioning, constraining their holistic world understanding. This stems from insufficient cross-modal interaction and limited modal diversity for comprehensive world knowledge representation. To address these limitations, we introduce UnityVideo, a unified framework for world-aware video generation that jointly learns across multiple modalities (segmentation masks, human skeletons, DensePose, optical flow, and depth maps) and training paradigms. Our approach features two core components: (1) dynamic noising to unify heterogeneous training paradigms, and (2) a modality switcher with an in-context learner that enables unified processing via modular parameters and contextual learning. We contribute a large-scale unified dataset with 1.3M samples. Through joint optimization, UnityVideo accelerates convergence and significantly enhances zero-shot generalization to unseen data. We demonstrate that UnityVideo achieves superior video quality, consistency, and improved alignment with physical world constraints. Code and data can be found at: https://github.com/dvlab-research/UnityVideo
StreamingTalker: Audio-driven 3D Facial Animation with Autoregressive Diffusion Model
Nov 19, 2025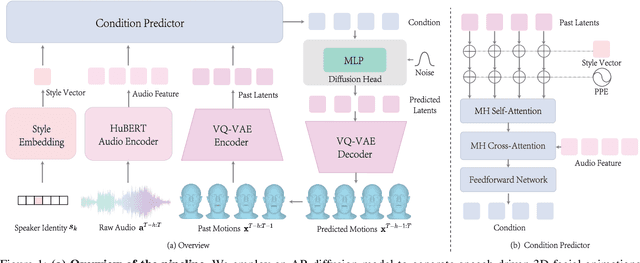
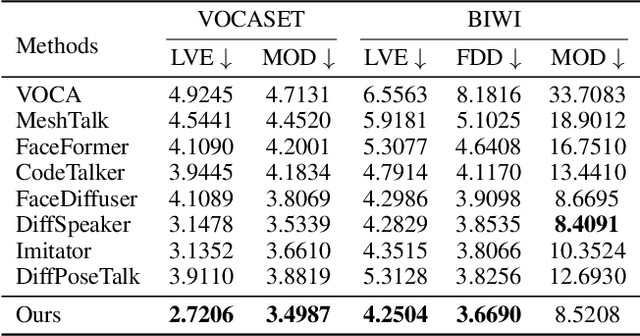
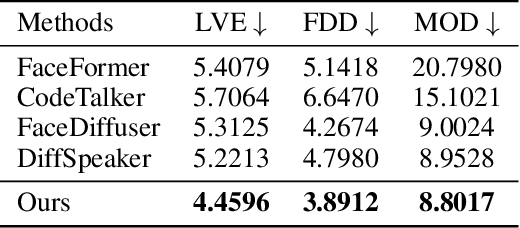
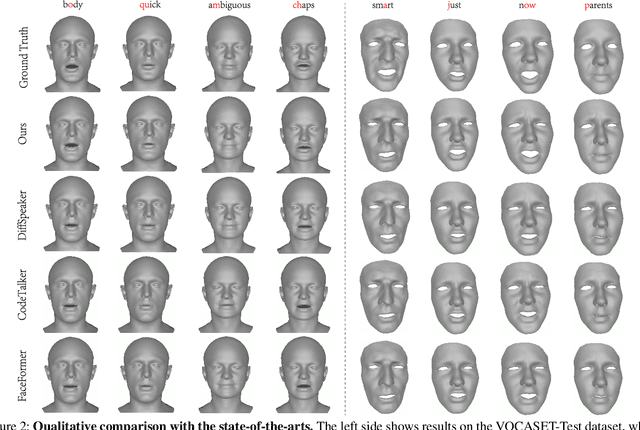
This paper focuses on the task of speech-driven 3D facial animation, which aims to generate realistic and synchronized facial motions driven by speech inputs. Recent methods have employed audio-conditioned diffusion models for 3D facial animation, achieving impressive results in generating expressive and natural animations. However, these methods process the whole audio sequences in a single pass, which poses two major challenges: they tend to perform poorly when handling audio sequences that exceed the training horizon and will suffer from significant latency when processing long audio inputs. To address these limitations, we propose a novel autoregressive diffusion model that processes input audio in a streaming manner. This design ensures flexibility with varying audio lengths and achieves low latency independent of audio duration. Specifically, we select a limited number of past frames as historical motion context and combine them with the audio input to create a dynamic condition. This condition guides the diffusion process to iteratively generate facial motion frames, enabling real-time synthesis with high-quality results. Additionally, we implemented a real-time interactive demo, highlighting the effectiveness and efficiency of our approach. We will release the code at https://zju3dv.github.io/StreamingTalker/.
CoDA: Coordinated Diffusion Noise Optimization for Whole-Body Manipulation of Articulated Objects
May 27, 2025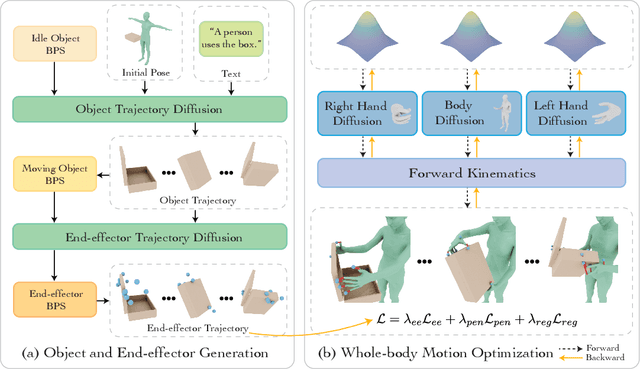
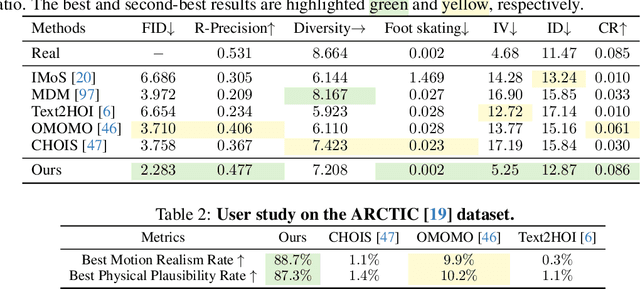
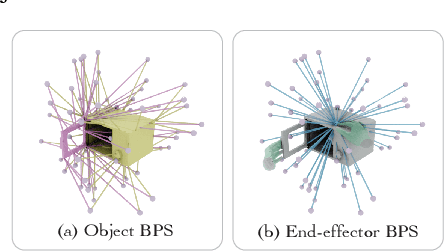
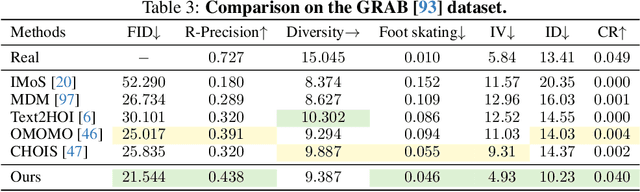
Synthesizing whole-body manipulation of articulated objects, including body motion, hand motion, and object motion, is a critical yet challenging task with broad applications in virtual humans and robotics. The core challenges are twofold. First, achieving realistic whole-body motion requires tight coordination between the hands and the rest of the body, as their movements are interdependent during manipulation. Second, articulated object manipulation typically involves high degrees of freedom and demands higher precision, often requiring the fingers to be placed at specific regions to actuate movable parts. To address these challenges, we propose a novel coordinated diffusion noise optimization framework. Specifically, we perform noise-space optimization over three specialized diffusion models for the body, left hand, and right hand, each trained on its own motion dataset to improve generalization. Coordination naturally emerges through gradient flow along the human kinematic chain, allowing the global body posture to adapt in response to hand motion objectives with high fidelity. To further enhance precision in hand-object interaction, we adopt a unified representation based on basis point sets (BPS), where end-effector positions are encoded as distances to the same BPS used for object geometry. This unified representation captures fine-grained spatial relationships between the hand and articulated object parts, and the resulting trajectories serve as targets to guide the optimization of diffusion noise, producing highly accurate interaction motion. We conduct extensive experiments demonstrating that our method outperforms existing approaches in motion quality and physical plausibility, and enables various capabilities such as object pose control, simultaneous walking and manipulation, and whole-body generation from hand-only data.
Ready-to-React: Online Reaction Policy for Two-Character Interaction Generation
Feb 27, 2025This paper addresses the task of generating two-character online interactions. Previously, two main settings existed for two-character interaction generation: (1) generating one's motions based on the counterpart's complete motion sequence, and (2) jointly generating two-character motions based on specific conditions. We argue that these settings fail to model the process of real-life two-character interactions, where humans will react to their counterparts in real time and act as independent individuals. In contrast, we propose an online reaction policy, called Ready-to-React, to generate the next character pose based on past observed motions. Each character has its own reaction policy as its "brain", enabling them to interact like real humans in a streaming manner. Our policy is implemented by incorporating a diffusion head into an auto-regressive model, which can dynamically respond to the counterpart's motions while effectively mitigating the error accumulation throughout the generation process. We conduct comprehensive experiments using the challenging boxing task. Experimental results demonstrate that our method outperforms existing baselines and can generate extended motion sequences. Additionally, we show that our approach can be controlled by sparse signals, making it well-suited for VR and other online interactive environments.
World-Grounded Human Motion Recovery via Gravity-View Coordinates
Sep 10, 2024



We present a novel method for recovering world-grounded human motion from monocular video. The main challenge lies in the ambiguity of defining the world coordinate system, which varies between sequences. Previous approaches attempt to alleviate this issue by predicting relative motion in an autoregressive manner, but are prone to accumulating errors. Instead, we propose estimating human poses in a novel Gravity-View (GV) coordinate system, which is defined by the world gravity and the camera view direction. The proposed GV system is naturally gravity-aligned and uniquely defined for each video frame, largely reducing the ambiguity of learning image-pose mapping. The estimated poses can be transformed back to the world coordinate system using camera rotations, forming a global motion sequence. Additionally, the per-frame estimation avoids error accumulation in the autoregressive methods. Experiments on in-the-wild benchmarks demonstrate that our method recovers more realistic motion in both the camera space and world-grounded settings, outperforming state-of-the-art methods in both accuracy and speed. The code is available at https://zju3dv.github.io/gvhmr/.
Generating Human Motion in 3D Scenes from Text Descriptions
May 13, 2024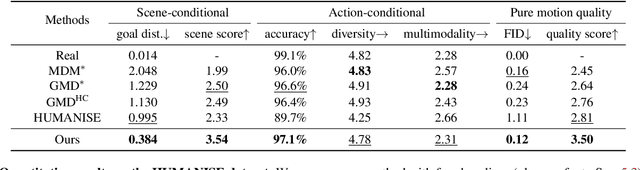
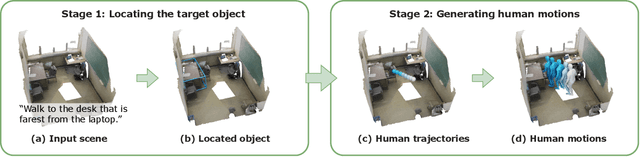
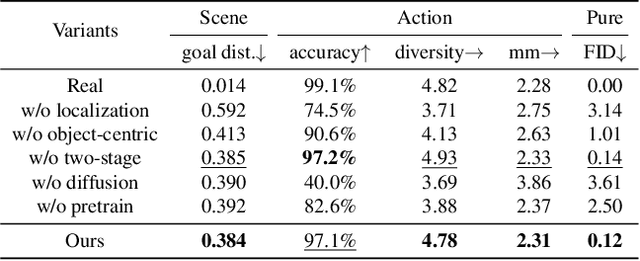
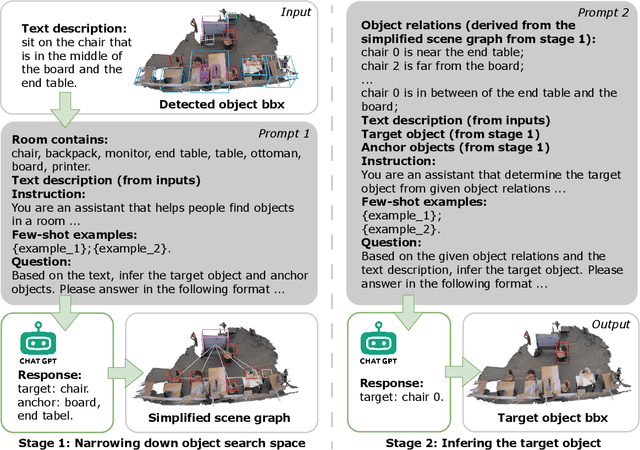
Generating human motions from textual descriptions has gained growing research interest due to its wide range of applications. However, only a few works consider human-scene interactions together with text conditions, which is crucial for visual and physical realism. This paper focuses on the task of generating human motions in 3D indoor scenes given text descriptions of the human-scene interactions. This task presents challenges due to the multi-modality nature of text, scene, and motion, as well as the need for spatial reasoning. To address these challenges, we propose a new approach that decomposes the complex problem into two more manageable sub-problems: (1) language grounding of the target object and (2) object-centric motion generation. For language grounding of the target object, we leverage the power of large language models. For motion generation, we design an object-centric scene representation for the generative model to focus on the target object, thereby reducing the scene complexity and facilitating the modeling of the relationship between human motions and the object. Experiments demonstrate the better motion quality of our approach compared to baselines and validate our design choices.
Learning Human Mesh Recovery in 3D Scenes
Jun 06, 2023We present a novel method for recovering the absolute pose and shape of a human in a pre-scanned scene given a single image. Unlike previous methods that perform sceneaware mesh optimization, we propose to first estimate absolute position and dense scene contacts with a sparse 3D CNN, and later enhance a pretrained human mesh recovery network by cross-attention with the derived 3D scene cues. Joint learning on images and scene geometry enables our method to reduce the ambiguity caused by depth and occlusion, resulting in more reasonable global postures and contacts. Encoding scene-aware cues in the network also allows the proposed method to be optimization-free, and opens up the opportunity for real-time applications. The experiments show that the proposed network is capable of recovering accurate and physically-plausible meshes by a single forward pass and outperforms state-of-the-art methods in terms of both accuracy and speed.