 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSODA: Semantic-Oriented Distributional Alignment for Generative Recommendation
Feb 28, 2026Generative recommendation has emerged as a scalable alternative to traditional retrieve-and-rank pipelines by operating in a compact token space. However, existing methods mainly rely on discrete code-level supervision, which leads to information loss and limits the joint optimization between the tokenizer and the generative recommender. In this work, we propose a distribution-level supervision paradigm that leverages probability distributions over multi-layer codebooks as soft and information-rich representations. Building on this idea, we introduce Semantic-Oriented Distributional Alignment (SODA), a plug-and-play contrastive supervision framework based on Bayesian Personalized Ranking, which aligns semantically rich distributions via negative KL divergence while enabling end-to-end differentiable training. Extensive experiments on multiple real-world datasets demonstrate that SODA consistently improves the performance of various generative recommender backbones, validating its effectiveness and generality. Codes will be available upon acceptance.
UniGRec: Unified Generative Recommendation with Soft Identifiers for End-to-End Optimization
Jan 24, 2026Generative recommendation has recently emerged as a transformative paradigm that directly generates target items, surpassing traditional cascaded approaches. It typically involves two components: a tokenizer that learns item identifiers and a recommender trained on them. Existing methods often decouple tokenization from recommendation or rely on asynchronous alternating optimization, limiting full end-to-end alignment. To address this, we unify the tokenizer and recommender under the ultimate recommendation objective via differentiable soft item identifiers, enabling joint end-to-end training. However, this introduces three challenges: training-inference discrepancy due to soft-to-hard mismatch, item identifier collapse from codeword usage imbalance, and collaborative signal deficiency due to an overemphasis on fine-grained token-level semantics. To tackle these challenges, we propose UniGRec, a unified generative recommendation framework that addresses them from three perspectives. UniGRec employs Annealed Inference Alignment during tokenization to smoothly bridge soft training and hard inference, a Codeword Uniformity Regularization to prevent identifier collapse and encourage codebook diversity, and a Dual Collaborative Distillation mechanism that distills collaborative priors from a lightweight teacher model to jointly guide both the tokenizer and the recommender. Extensive experiments on real-world datasets demonstrate that UniGRec consistently outperforms state-of-the-art baseline methods. Our codes are available at https://github.com/Jialei-03/UniGRec.
MOBIUS: Towards the Next Generation of Query-Ad Matching in Baidu's Sponsored Search
Sep 05, 2024


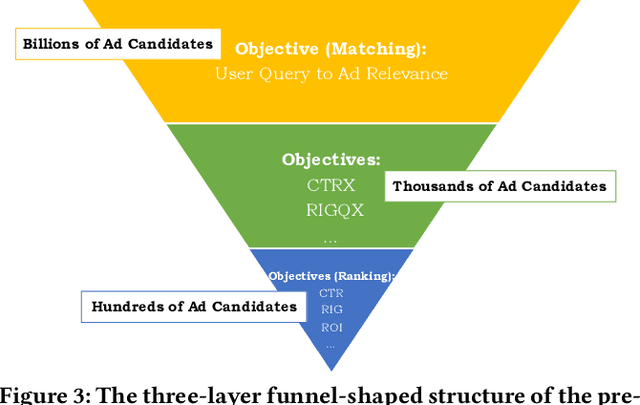
Baidu runs the largest commercial web search engine in China, serving hundreds of millions of online users every day in response to a great variety of queries. In order to build a high-efficiency sponsored search engine, we used to adopt a three-layer funnel-shaped structure to screen and sort hundreds of ads from billions of ad candidates subject to the requirement of low response latency and the restraints of computing resources. Given a user query, the top matching layer is responsible for providing semantically relevant ad candidates to the next layer, while the ranking layer at the bottom concerns more about business indicators (e.g., CPM, ROI, etc.) of those ads. The clear separation between the matching and ranking objectives results in a lower commercial return. The Mobius project has been established to address this serious issue. It is our first attempt to train the matching layer to consider CPM as an additional optimization objective besides the query-ad relevance, via directly predicting CTR (click-through rate) from billions of query-ad pairs. Specifically, this paper will elaborate on how we adopt active learning to overcome the insufficiency of click history at the matching layer when training our neural click networks offline, and how we use the SOTA ANN search technique for retrieving ads more efficiently (Here ``ANN'' stands for approximate nearest neighbor search). We contribute the solutions to Mobius-V1 as the first version of our next generation query-ad matching system.
Generating Human Motion in 3D Scenes from Text Descriptions
May 13, 2024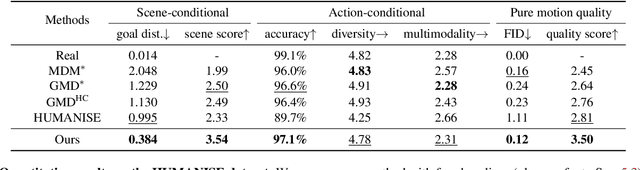
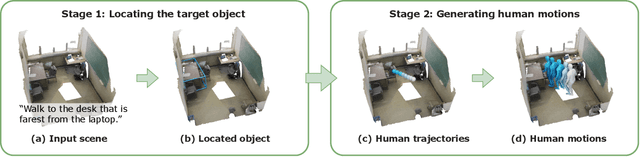
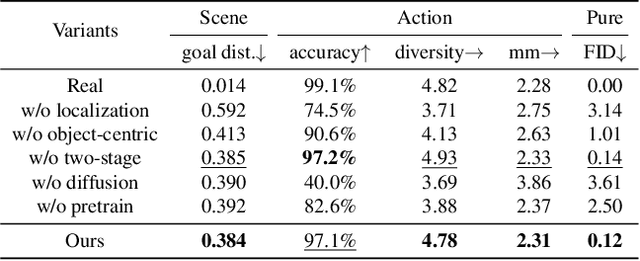
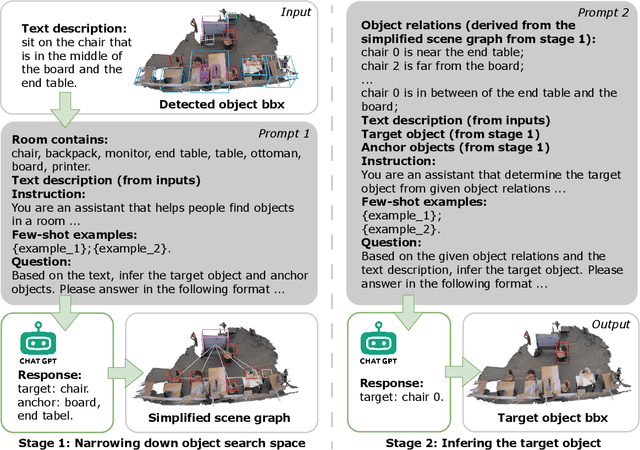
Generating human motions from textual descriptions has gained growing research interest due to its wide range of applications. However, only a few works consider human-scene interactions together with text conditions, which is crucial for visual and physical realism. This paper focuses on the task of generating human motions in 3D indoor scenes given text descriptions of the human-scene interactions. This task presents challenges due to the multi-modality nature of text, scene, and motion, as well as the need for spatial reasoning. To address these challenges, we propose a new approach that decomposes the complex problem into two more manageable sub-problems: (1) language grounding of the target object and (2) object-centric motion generation. For language grounding of the target object, we leverage the power of large language models. For motion generation, we design an object-centric scene representation for the generative model to focus on the target object, thereby reducing the scene complexity and facilitating the modeling of the relationship between human motions and the object. Experiments demonstrate the better motion quality of our approach compared to baselines and validate our design choices.
Multi-view Hypergraph Contrastive Policy Learning for Conversational Recommendation
Jul 26, 2023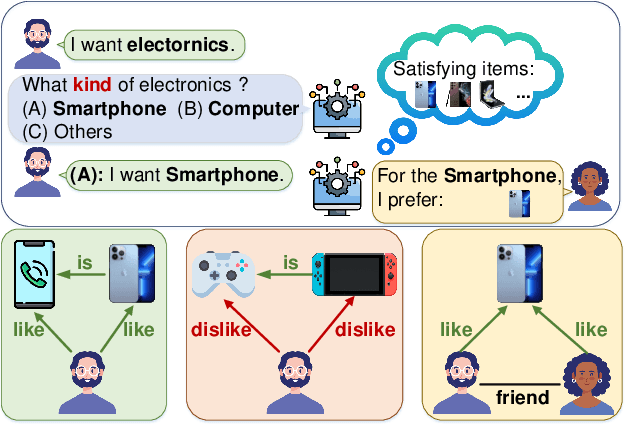

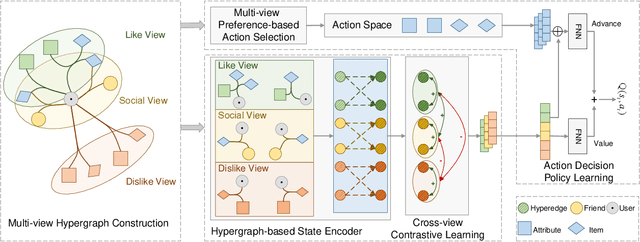

Conversational recommendation systems (CRS) aim to interactively acquire user preferences and accordingly recommend items to users. Accurately learning the dynamic user preferences is of crucial importance for CRS. Previous works learn the user preferences with pairwise relations from the interactive conversation and item knowledge, while largely ignoring the fact that factors for a relationship in CRS are multiplex. Specifically, the user likes/dislikes the items that satisfy some attributes (Like/Dislike view). Moreover social influence is another important factor that affects user preference towards the item (Social view), while is largely ignored by previous works in CRS. The user preferences from these three views are inherently different but also correlated as a whole. The user preferences from the same views should be more similar than that from different views. The user preferences from Like View should be similar to Social View while different from Dislike View. To this end, we propose a novel model, namely Multi-view Hypergraph Contrastive Policy Learning (MHCPL). Specifically, MHCPL timely chooses useful social information according to the interactive history and builds a dynamic hypergraph with three types of multiplex relations from different views. The multiplex relations in each view are successively connected according to their generation order.
Towards Hierarchical Policy Learning for Conversational Recommendation with Hypergraph-based Reinforcement Learning
May 04, 2023

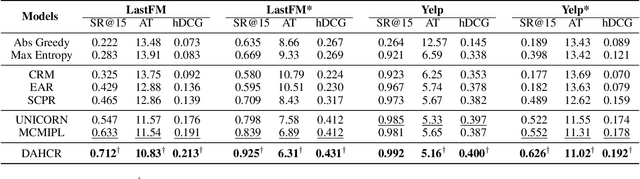
Conversational recommendation systems (CRS) aim to timely and proactively acquire user dynamic preferred attributes through conversations for item recommendation. In each turn of CRS, there naturally have two decision-making processes with different roles that influence each other: 1) director, which is to select the follow-up option (i.e., ask or recommend) that is more effective for reducing the action space and acquiring user preferences; and 2) actor, which is to accordingly choose primitive actions (i.e., asked attribute or recommended item) that satisfy user preferences and give feedback to estimate the effectiveness of the director's option. However, existing methods heavily rely on a unified decision-making module or heuristic rules, while neglecting to distinguish the roles of different decision procedures, as well as the mutual influences between them. To address this, we propose a novel Director-Actor Hierarchical Conversational Recommender (DAHCR), where the director selects the most effective option, followed by the actor accordingly choosing primitive actions that satisfy user preferences. Specifically, we develop a dynamic hypergraph to model user preferences and introduce an intrinsic motivation to train from weak supervision over the director. Finally, to alleviate the bad effect of model bias on the mutual influence between the director and actor, we model the director's option by sampling from a categorical distribution. Extensive experiments demonstrate that DAHCR outperforms state-of-the-art methods.
On-device Training: A First Overview on Existing Systems
Dec 01, 2022
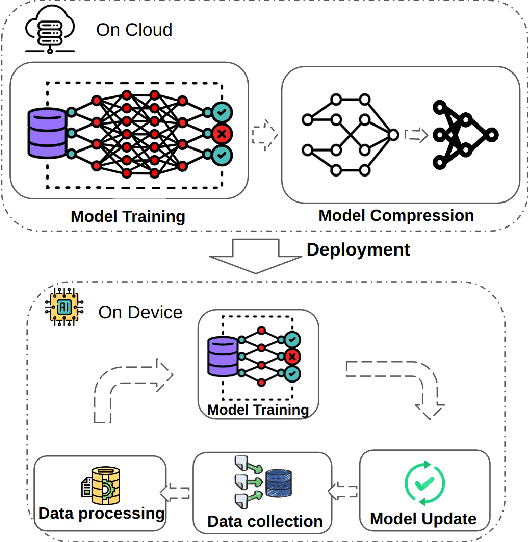
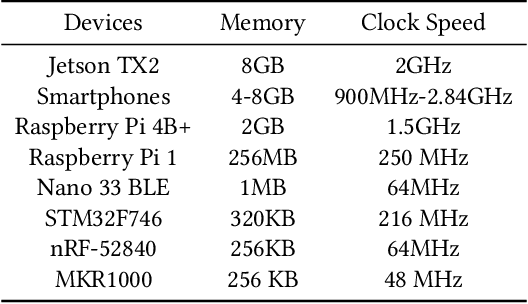

The recent breakthroughs in machine learning (ML) and deep learning (DL) have enabled many new capabilities across plenty of application domains. While most existing machine learning models require large memory and computing power, efforts have been made to deploy some models on resource-constrained devices as well. There are several systems that perform inference on the device, while direct training on the device still remains a challenge. On-device training, however, is attracting more and more interest because: (1) it enables training models on local data without needing to share data over the cloud, thus enabling privacy preserving computation by design; (2) models can be refined on devices to provide personalized services and cope with model drift in order to adapt to the changes of the real-world environment; and (3) it enables the deployment of models in remote, hardly accessible locations or places without stable internet connectivity. We summarize and analyze the-state-of-art systems research to provide the first survey of on-device training from a systems perspective.
AdaCoach: A Virtual Coach for Training Customer Service Agents
Apr 27, 2022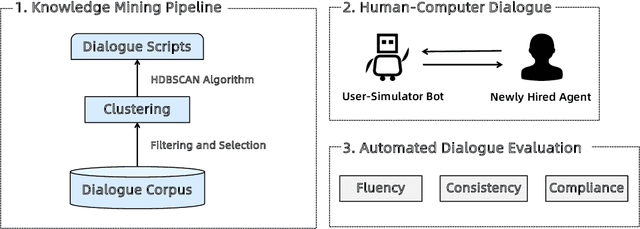
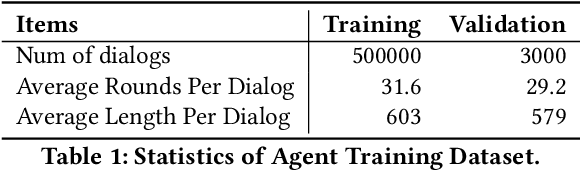
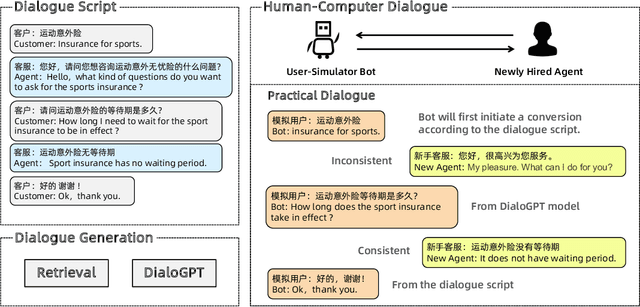

With the development of online business, customer service agents gradually play a crucial role as an interface between the companies and their customers. Most companies spend a lot of time and effort on hiring and training customer service agents. To this end, we propose AdaCoach: A Virtual Coach for Training Customer Service Agents, to promote the ability of newly hired service agents before they get to work. AdaCoach is designed to simulate real customers who seek help and actively initiate the dialogue with the customer service agents. Besides, AdaCoach uses an automated dialogue evaluation model to score the performance of the customer agent in the training process, which can provide necessary assistance when the newly hired customer service agent encounters problems. We apply recent NLP technologies to ensure efficient run-time performance in the deployed system. To the best of our knowledge, this is the first system that trains the customer service agent through human-computer interaction. Until now, the system has already supported more than 500,000 simulation training and cultivated over 1000 qualified customer service agents.