 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGBGC: Efficient and Adaptive Graph Coarsening via Granular-ball Computing
Jun 24, 2025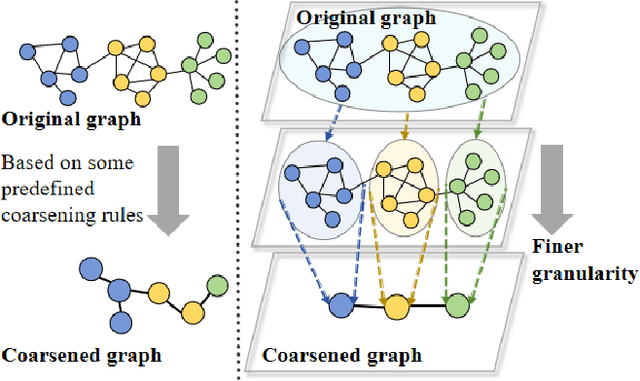
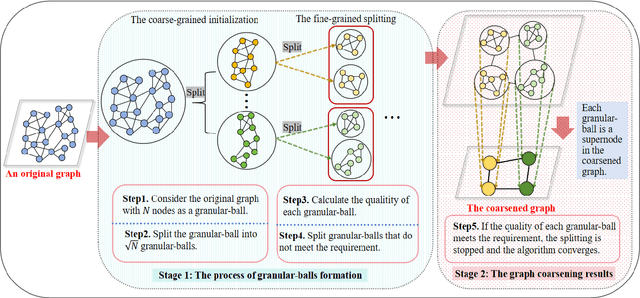

The objective of graph coarsening is to generate smaller, more manageable graphs while preserving key information of the original graph. Previous work were mainly based on the perspective of spectrum-preserving, using some predefined coarsening rules to make the eigenvalues of the Laplacian matrix of the original graph and the coarsened graph match as much as possible. However, they largely overlooked the fact that the original graph is composed of subregions at different levels of granularity, where highly connected and similar nodes should be more inclined to be aggregated together as nodes in the coarsened graph. By combining the multi-granularity characteristics of the graph structure, we can generate coarsened graph at the optimal granularity. To this end, inspired by the application of granular-ball computing in multi-granularity, we propose a new multi-granularity, efficient, and adaptive coarsening method via granular-ball (GBGC), which significantly improves the coarsening results and efficiency. Specifically, GBGC introduces an adaptive granular-ball graph refinement mechanism, which adaptively splits the original graph from coarse to fine into granular-balls of different sizes and optimal granularity, and constructs the coarsened graph using these granular-balls as supernodes. In addition, compared with other state-of-the-art graph coarsening methods, the processing speed of this method can be increased by tens to hundreds of times and has lower time complexity. The accuracy of GBGC is almost always higher than that of the original graph due to the good robustness and generalization of the granular-ball computing, so it has the potential to become a standard graph data preprocessing method.
Multi-Granularity Open Intent Classification via Adaptive Granular-Ball Decision Boundary
Dec 18, 2024



Open intent classification is critical for the development of dialogue systems, aiming to accurately classify known intents into their corresponding classes while identifying unknown intents. Prior boundary-based methods assumed known intents fit within compact spherical regions, focusing on coarse-grained representation and precise spherical decision boundaries. However, these assumptions are often violated in practical scenarios, making it difficult to distinguish known intent classes from unknowns using a single spherical boundary. To tackle these issues, we propose a Multi-granularity Open intent classification method via adaptive Granular-Ball decision boundary (MOGB). Our MOGB method consists of two modules: representation learning and decision boundary acquiring. To effectively represent the intent distribution, we design a hierarchical representation learning method. This involves iteratively alternating between adaptive granular-ball clustering and nearest sub-centroid classification to capture fine-grained semantic structures within known intent classes. Furthermore, multi-granularity decision boundaries are constructed for open intent classification by employing granular-balls with varying centroids and radii. Extensive experiments conducted on three public datasets demonstrate the effectiveness of our proposed method.
* This paper has been Accepted on AAAI2025
Graph Coarsening via Supervised Granular-Ball for Scalable Graph Neural Network Training
Dec 18, 2024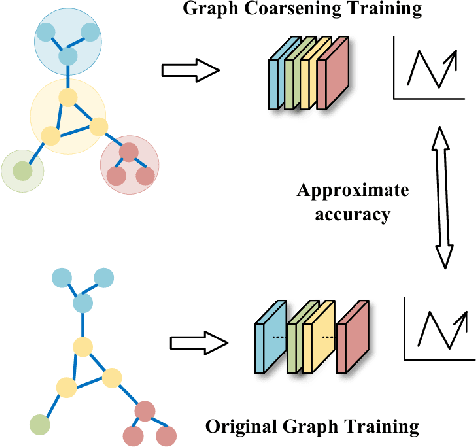
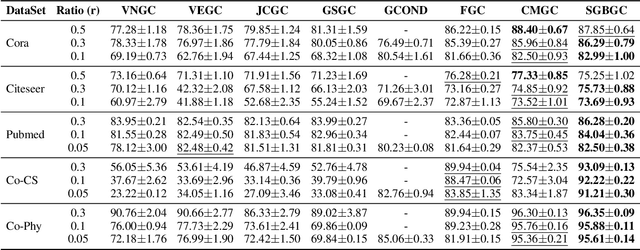
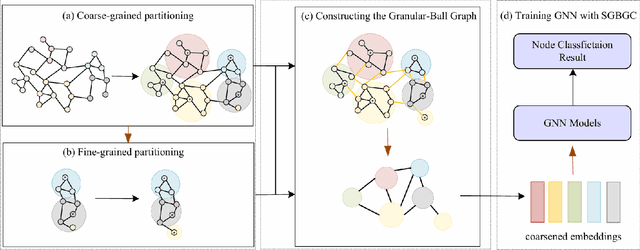
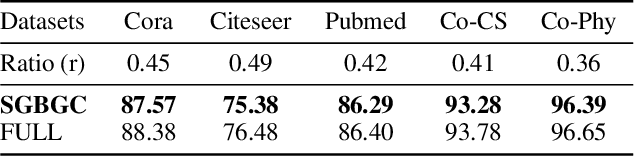
Graph Neural Networks (GNNs) have demonstrated significant achievements in processing graph data, yet scalability remains a substantial challenge. To address this, numerous graph coarsening methods have been developed. However, most existing coarsening methods are training-dependent, leading to lower efficiency, and they all require a predefined coarsening rate, lacking an adaptive approach. In this paper, we employ granular-ball computing to effectively compress graph data. We construct a coarsened graph network by iteratively splitting the graph into granular-balls based on a purity threshold and using these granular-balls as super vertices. This granulation process significantly reduces the size of the original graph, thereby greatly enhancing the training efficiency and scalability of GNNs. Additionally, our algorithm can adaptively perform splitting without requiring a predefined coarsening rate. Experimental results demonstrate that our method achieves accuracy comparable to training on the original graph. Noise injection experiments further indicate that our method exhibits robust performance. Moreover, our approach can reduce the graph size by up to 20 times without compromising test accuracy, substantially enhancing the scalability of GNNs.
Multi-view Hypergraph Contrastive Policy Learning for Conversational Recommendation
Jul 26, 2023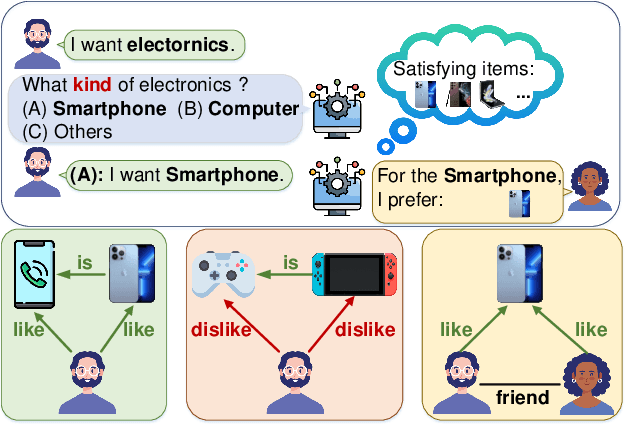

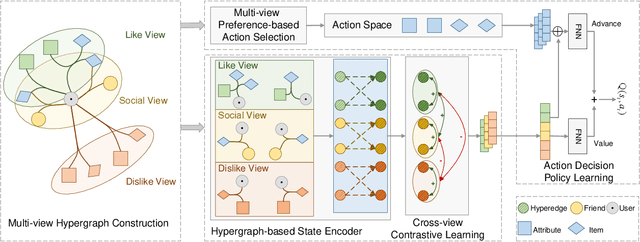

Conversational recommendation systems (CRS) aim to interactively acquire user preferences and accordingly recommend items to users. Accurately learning the dynamic user preferences is of crucial importance for CRS. Previous works learn the user preferences with pairwise relations from the interactive conversation and item knowledge, while largely ignoring the fact that factors for a relationship in CRS are multiplex. Specifically, the user likes/dislikes the items that satisfy some attributes (Like/Dislike view). Moreover social influence is another important factor that affects user preference towards the item (Social view), while is largely ignored by previous works in CRS. The user preferences from these three views are inherently different but also correlated as a whole. The user preferences from the same views should be more similar than that from different views. The user preferences from Like View should be similar to Social View while different from Dislike View. To this end, we propose a novel model, namely Multi-view Hypergraph Contrastive Policy Learning (MHCPL). Specifically, MHCPL timely chooses useful social information according to the interactive history and builds a dynamic hypergraph with three types of multiplex relations from different views. The multiplex relations in each view are successively connected according to their generation order.
Multi-view Intent Disentangle Graph Networks for Bundle Recommendation
Feb 23, 2022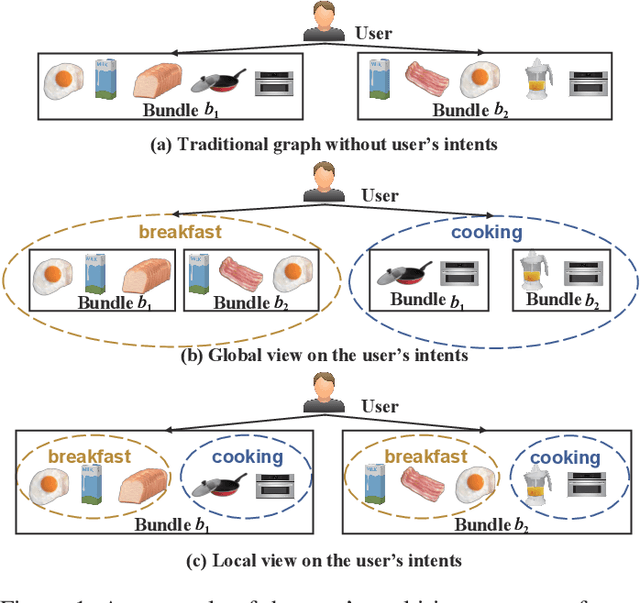
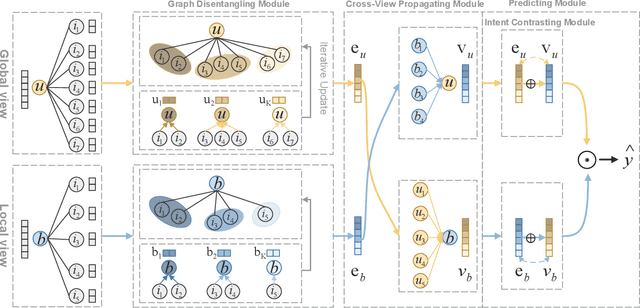
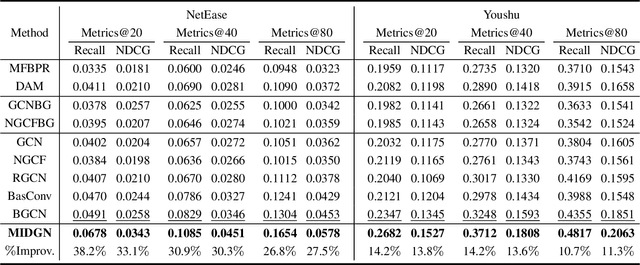
Bundle recommendation aims to recommend the user a bundle of items as a whole. Nevertheless, they usually neglect the diversity of the user's intents on adopting items and fail to disentangle the user's intents in representations. In the real scenario of bundle recommendation, a user's intent may be naturally distributed in the different bundles of that user (Global view), while a bundle may contain multiple intents of a user (Local view). Each view has its advantages for intent disentangling: 1) From the global view, more items are involved to present each intent, which can demonstrate the user's preference under each intent more clearly. 2) From the local view, it can reveal the association among items under each intent since items within the same bundle are highly correlated to each other. To this end, we propose a novel model named Multi-view Intent Disentangle Graph Networks (MIDGN), which is capable of precisely and comprehensively capturing the diversity of the user's intent and items' associations at the finer granularity. Specifically, MIDGN disentangles the user's intents from two different perspectives, respectively: 1) In the global level, MIDGN disentangles the user's intent coupled with inter-bundle items; 2) In the Local level, MIDGN disentangles the user's intent coupled with items within each bundle. Meanwhile, we compare the user's intents disentangled from different views under the contrast learning framework to improve the learned intents. Extensive experiments conducted on two benchmark datasets demonstrate that MIDGN outperforms the state-of-the-art methods by over 10.7% and 26.8%, respectively.
Predicting on the Edge: Identifying Where a Larger Model Does Better
Feb 15, 2022Much effort has been devoted to making large and more accurate models, but relatively little has been put into understanding which examples are benefiting from the added complexity. In this paper, we demonstrate and analyze the surprisingly tight link between a model's predictive uncertainty on individual examples and the likelihood that larger models will improve prediction on them. Through extensive numerical studies on the T5 encoder-decoder architecture, we show that large models have the largest improvement on examples where the small model is most uncertain. On more certain examples, even those where the small model is not particularly accurate, large models are often unable to improve at all, and can even perform worse than the smaller model. Based on these findings, we show that a switcher model which defers examples to a larger model when a small model is uncertain can achieve striking improvements in performance and resource usage. We also explore committee-based uncertainty metrics that can be more effective but less practical.
Distribution Embedding Networks for Meta-Learning with Heterogeneous Covariate Spaces
Feb 04, 2022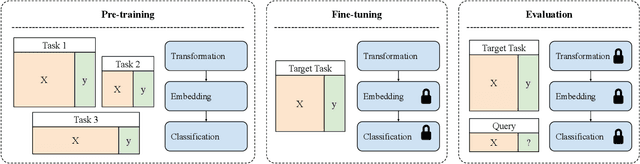

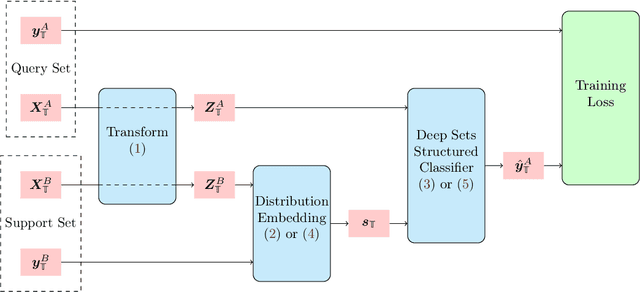
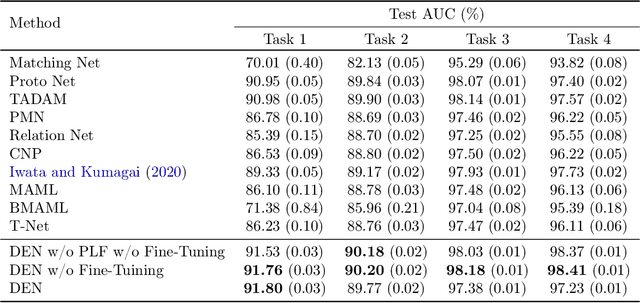
We propose Distribution Embedding Networks (DEN) for classification with small data using meta-learning techniques. Unlike existing meta-learning approaches that focus on image recognition tasks and require the training and target tasks to be similar, DEN is specifically designed to be trained on a diverse set of training tasks and applied on tasks whose number and distribution of covariates differ vastly from its training tasks. Such property of DEN is enabled by its three-block architecture: a covariate transformation block followed by a distribution embedding block and then a classification block. We provide theoretical insights to show that this architecture allows the embedding and classification blocks to be fixed after pre-training on a diverse set of tasks; only the covariate transformation block with relatively few parameters needs to be updated for each new task. To facilitate the training of DEN, we also propose an approach to synthesize binary classification training tasks, and demonstrate that DEN outperforms existing methods in a number of synthetic and real tasks in numerical studies.
Global Optimization Networks
Feb 02, 2022


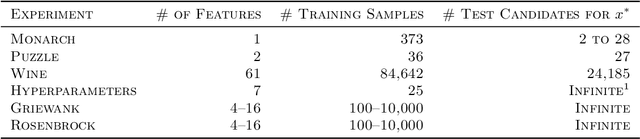
We consider the problem of estimating a good maximizer of a black-box function given noisy examples. To solve such problems, we propose to fit a new type of function which we call a global optimization network (GON), defined as any composition of an invertible function and a unimodal function, whose unique global maximizer can be inferred in $\mathcal{O}(D)$ time. In this paper, we show how to construct invertible and unimodal functions by using linear inequality constraints on lattice models. We also extend to \emph{conditional} GONs that find a global maximizer conditioned on specified inputs of other dimensions. Experiments show the GON maximizers are statistically significantly better predictions than those produced by convex fits, GPR, or DNNs, and are more reasonable predictions for real-world problems.
A recurrent neural network approach for remaining useful life prediction utilizing a novel trend features construction method
Dec 10, 2021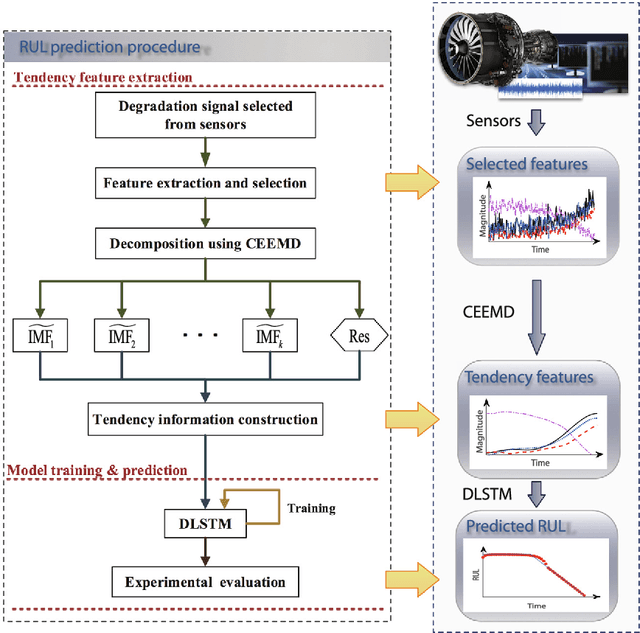
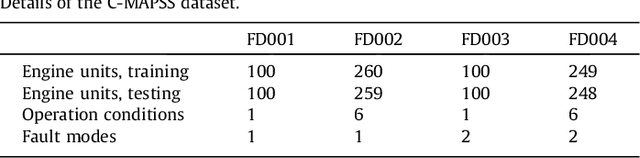
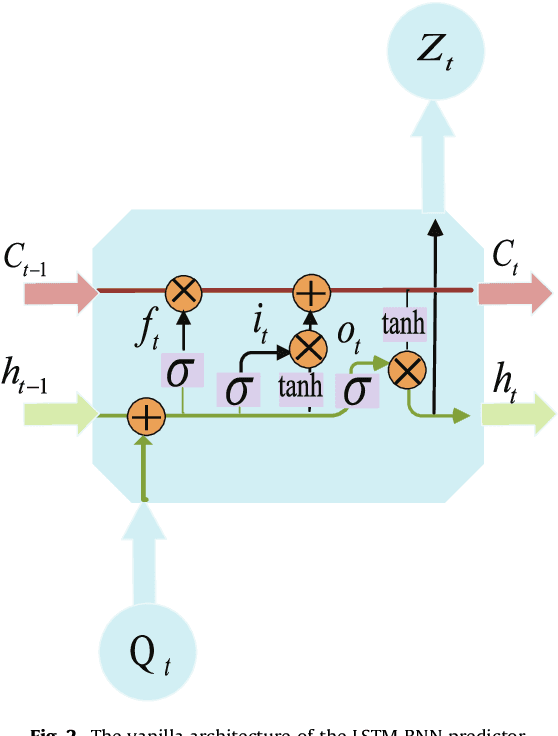

Data-driven methods for remaining useful life (RUL) prediction normally learn features from a fixed window size of a priori of degradation, which may lead to less accurate prediction results on different datasets because of the variance of local features. This paper proposes a method for RUL prediction which depends on a trend feature representing the overall time sequence of degradation. Complete ensemble empirical mode decomposition, followed by a reconstruction procedure, is created to build the trend features. The probability distribution of sensors' measurement learned by conditional neural processes is used to evaluate the trend features. With the best trend feature, a data-driven model using long short-term memory is developed to predict the RUL. To prove the effectiveness of the proposed method, experiments on a benchmark C-MAPSS dataset are carried out and compared with other state-of-the-art methods. Comparison results show that the proposed method achieves the smallest root mean square values in prediction of all RUL.
Advances and Open Problems in Federated Learning
Dec 10, 2019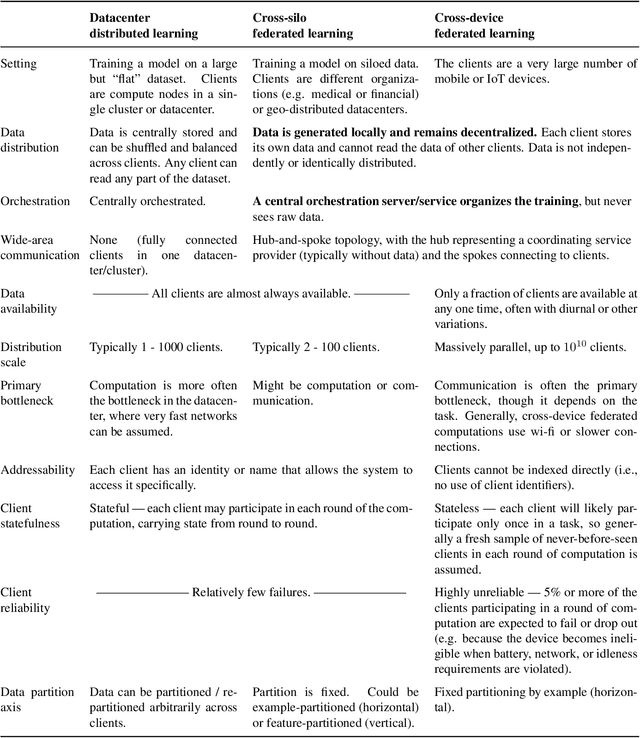
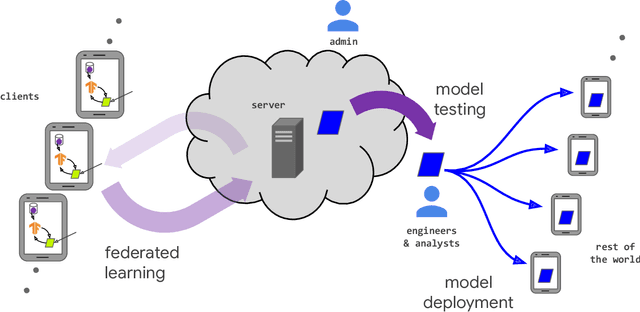
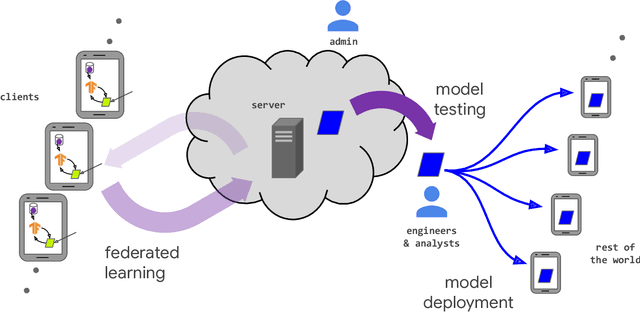

Federated learning (FL) is a machine learning setting where many clients (e.g. mobile devices or whole organizations) collaboratively train a model under the orchestration of a central server (e.g. service provider), while keeping the training data decentralized. FL embodies the principles of focused data collection and minimization, and can mitigate many of the systemic privacy risks and costs resulting from traditional, centralized machine learning and data science approaches. Motivated by the explosive growth in FL research, this paper discusses recent advances and presents an extensive collection of open problems and challenges.