 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVenusBench-GD: A Comprehensive Multi-Platform GUI Benchmark for Diverse Grounding Tasks
Dec 18, 2025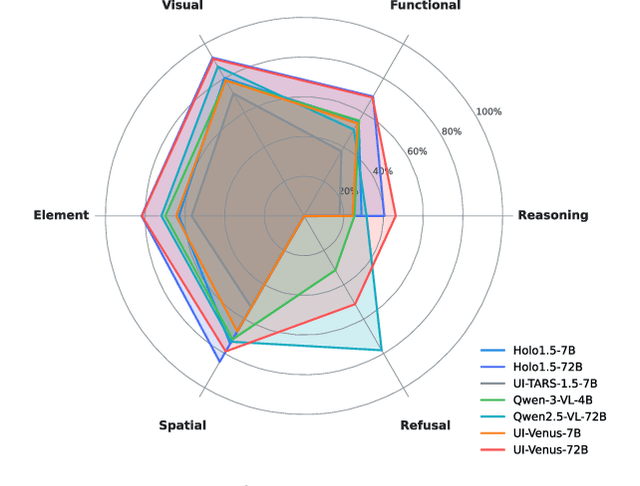
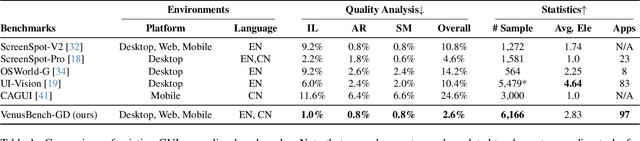
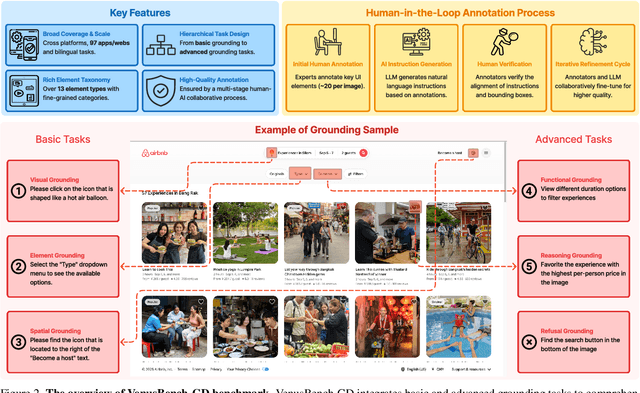
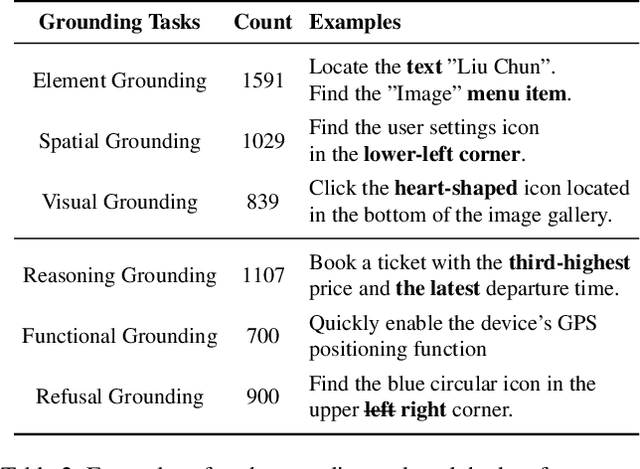
GUI grounding is a critical component in building capable GUI agents. However, existing grounding benchmarks suffer from significant limitations: they either provide insufficient data volume and narrow domain coverage, or focus excessively on a single platform and require highly specialized domain knowledge. In this work, we present VenusBench-GD, a comprehensive, bilingual benchmark for GUI grounding that spans multiple platforms, enabling hierarchical evaluation for real-word applications. VenusBench-GD contributes as follows: (i) we introduce a large-scale, cross-platform benchmark with extensive coverage of applications, diverse UI elements, and rich annotated data, (ii) we establish a high-quality data construction pipeline for grounding tasks, achieving higher annotation accuracy than existing benchmarks, and (iii) we extend the scope of element grounding by proposing a hierarchical task taxonomy that divides grounding into basic and advanced categories, encompassing six distinct subtasks designed to evaluate models from complementary perspectives. Our experimental findings reveal critical insights: general-purpose multimodal models now match or even surpass specialized GUI models on basic grounding tasks. In contrast, advanced tasks, still favor GUI-specialized models, though they exhibit significant overfitting and poor robustness. These results underscore the necessity of comprehensive, multi-tiered evaluation frameworks.
PLReMix: Combating Noisy Labels with Pseudo-Label Relaxed Contrastive Representation Learning
Feb 27, 2024



Recently, the application of Contrastive Representation Learning (CRL) in learning with noisy labels (LNL) has shown promising advancements due to its remarkable ability to learn well-distributed representations for better distinguishing noisy labels. However, CRL is mainly used as a pre-training technique, leading to a complicated multi-stage training pipeline. We also observed that trivially combining CRL with supervised LNL methods decreases performance. Using different images from the same class as negative pairs in CRL creates optimization conflicts between CRL and the supervised loss. To address these two issues, we propose an end-to-end PLReMix framework that avoids the complicated pipeline by introducing a Pseudo-Label Relaxed (PLR) contrastive loss to alleviate the conflicts between losses. This PLR loss constructs a reliable negative set of each sample by filtering out its inappropriate negative pairs that overlap at the top k indices of prediction probabilities, leading to more compact semantic clusters than vanilla CRL. Furthermore, a two-dimensional Gaussian Mixture Model (GMM) is adopted to distinguish clean and noisy samples by leveraging semantic information and model outputs simultaneously, which is expanded on the previously widely used one-dimensional form. The PLR loss and a semi-supervised loss are simultaneously applied to train on the GMM divided clean and noisy samples. Experiments on multiple benchmark datasets demonstrate the effectiveness of the proposed method. Our proposed PLR loss is scalable, which can be easily integrated into other LNL methods and boost their performance. Codes will be available.
A recurrent neural network approach for remaining useful life prediction utilizing a novel trend features construction method
Dec 10, 2021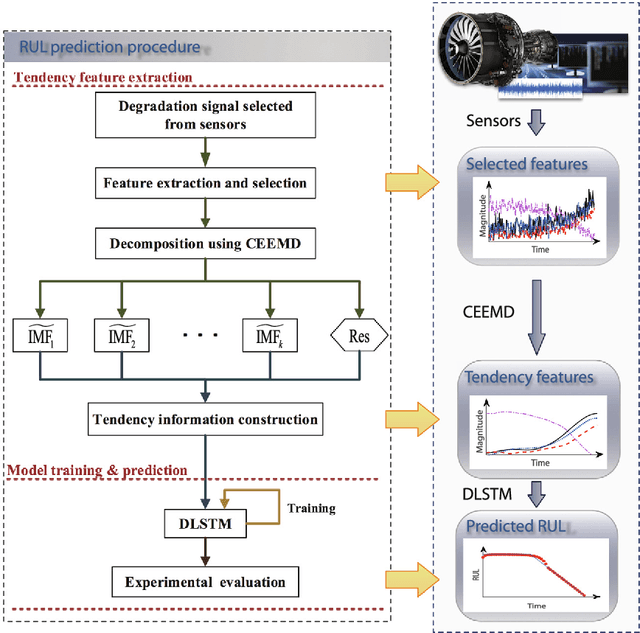
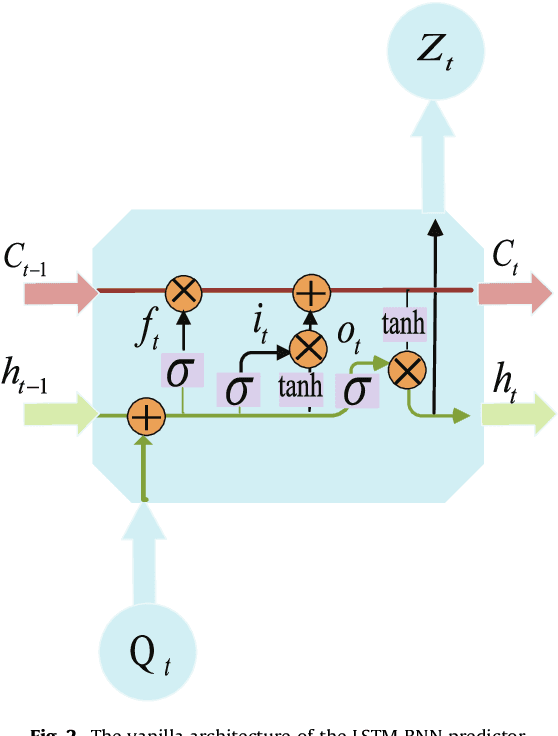

Data-driven methods for remaining useful life (RUL) prediction normally learn features from a fixed window size of a priori of degradation, which may lead to less accurate prediction results on different datasets because of the variance of local features. This paper proposes a method for RUL prediction which depends on a trend feature representing the overall time sequence of degradation. Complete ensemble empirical mode decomposition, followed by a reconstruction procedure, is created to build the trend features. The probability distribution of sensors' measurement learned by conditional neural processes is used to evaluate the trend features. With the best trend feature, a data-driven model using long short-term memory is developed to predict the RUL. To prove the effectiveness of the proposed method, experiments on a benchmark C-MAPSS dataset are carried out and compared with other state-of-the-art methods. Comparison results show that the proposed method achieves the smallest root mean square values in prediction of all RUL.
A Novel GAN-based Fault Diagnosis Approach for Imbalanced Industrial Time Series
Apr 01, 2019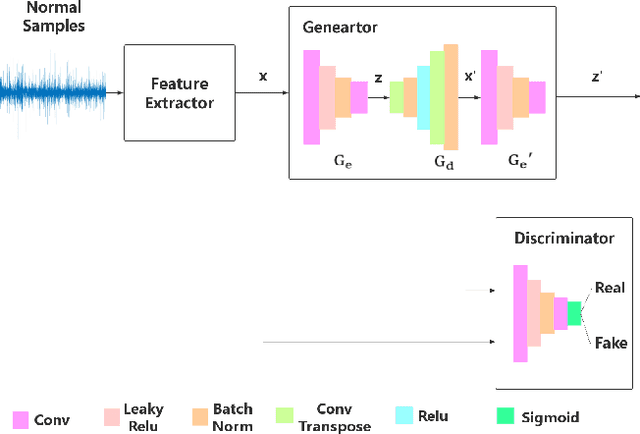
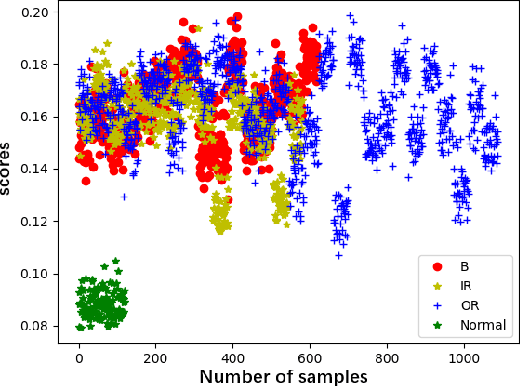

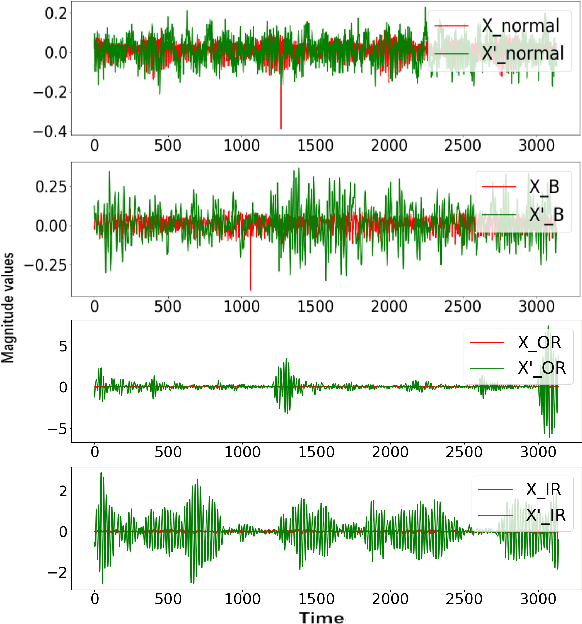
This paper proposes a novel fault diagnosis approach based on generative adversarial networks (GAN) for imbalanced industrial time series where normal samples are much larger than failure cases. We combine a well-designed feature extractor with GAN to help train the whole network. Aimed at obtaining data distribution and hidden pattern in both original distinguishing features and latent space, the encoder-decoder-encoder three-sub-network is employed in GAN, based on Deep Convolution Generative Adversarial Networks (DCGAN) but without Tanh activation layer and only trained on normal samples. In order to verify the validity and feasibility of our approach, we test it on rolling bearing data from Case Western Reserve University and further verify it on data collected from our laboratory. The results show that our proposed approach can achieve excellent performance in detecting faulty by outputting much larger evaluation scores.
Wasserstein Distance based Deep Adversarial Transfer Learning for Intelligent Fault Diagnosis
Mar 02, 2019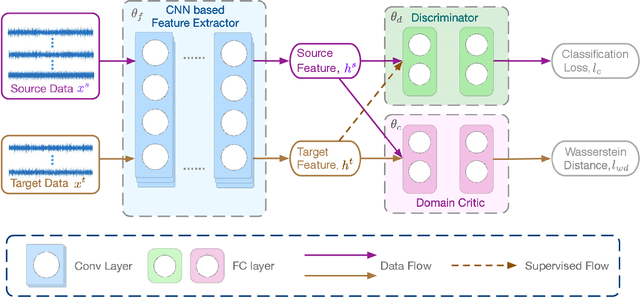

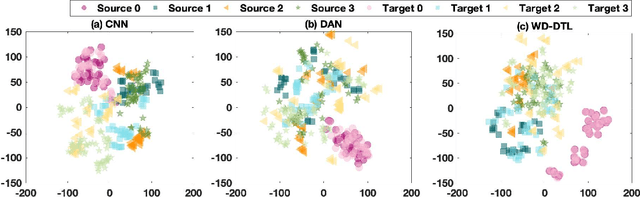
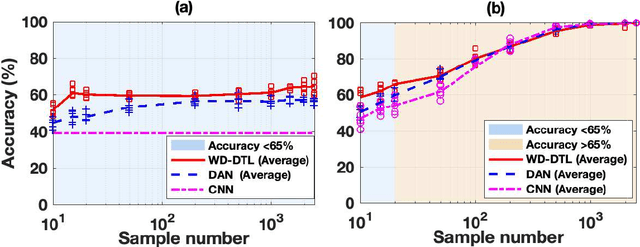
The demand of artificial intelligent adoption for condition-based maintenance strategy is astonishingly increased over the past few years. Intelligent fault diagnosis is one critical topic of maintenance solution for mechanical systems. Deep learning models, such as convolutional neural networks (CNNs), have been successfully applied to fault diagnosis tasks for mechanical systems and achieved promising results. However, for diverse working conditions in the industry, deep learning suffers two difficulties: one is that the well-defined (source domain) and new (target domain) datasets are with different feature distributions; another one is the fact that insufficient or no labelled data in target domain significantly reduce the accuracy of fault diagnosis. As a novel idea, deep transfer learning (DTL) is created to perform learning in the target domain by leveraging information from the relevant source domain. Inspired by Wasserstein distance of optimal transport, in this paper, we propose a novel DTL approach to intelligent fault diagnosis, namely Wasserstein Distance based Deep Transfer Learning (WD-DTL), to learn domain feature representations (generated by a CNN based feature extractor) and to minimize the distributions between the source and target domains through adversarial training. The effectiveness of the proposed WD-DTL is verified through 3 transfer scenarios and 16 transfer fault diagnosis experiments of both unsupervised and supervised (with insufficient labelled data) learning. We also provide a comprehensive analysis of the network visualization of those transfer tasks.
Artificial Intelligent Diagnosis and Monitoring in Manufacturing
Dec 17, 2018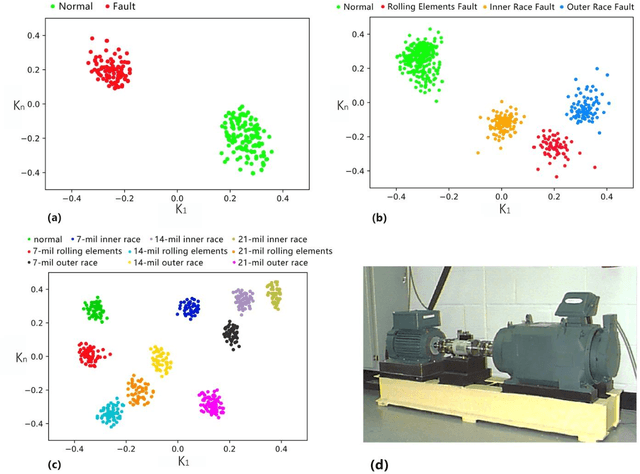
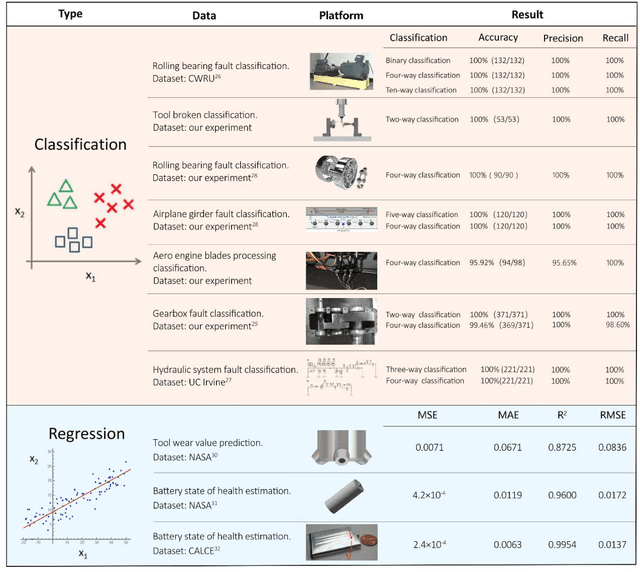
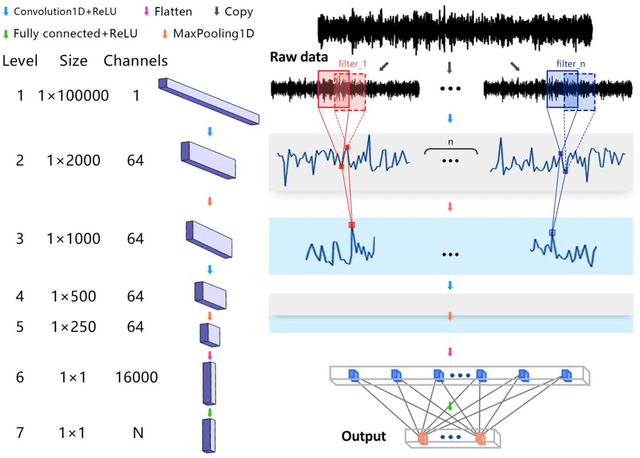
The manufacturing sector is heavily influenced by artificial intelligence-based technologies with the extraordinary increases in computational power and data volumes. It has been reported that 35% of US manufacturers are currently collecting data from sensors for manufacturing processes enhancement. Nevertheless, many are still struggling to achieve the 'Industry 4.0', which aims to achieve nearly 50% reduction in maintenance cost and total machine downtime by proper health management. For increasing productivity and reducing operating costs, a central challenge lies in the detection of faults or wearing parts in machining operations. Here we propose a data-driven, end-to-end framework for monitoring of manufacturing systems. This framework, derived from deep learning techniques, evaluates fused sensory measurements to detect and even predict faults and wearing conditions. This work exploits the predictive power of deep learning to extract hidden degradation features from noisy data. We demonstrate the proposed framework on several representative experimental manufacturing datasets drawn from a wide variety of applications, ranging from mechanical to electrical systems. Results reveal that the framework performs well in all benchmark applications examined and can be applied in diverse contexts, indicating its potential for use as a critical corner stone in smart manufacturing.