 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Self-Evolving Agentic Framework for Metasurface Inverse Design
Apr 01, 2026Metasurface inverse design has become central to realizing complex optical functionality, yet translating target responses into executable, solver-compatible workflows still demands specialized expertise in computational electromagnetics and solver-specific software engineering. Recent large language models (LLMs) offer a complementary route to reducing this workflow-construction burden, but existing language-driven systems remain largely session-bounded and do not preserve reusable workflow knowledge across inverse-design tasks. We present an agentic framework for metasurface inverse design that addresses this limitation through context-level skill evolution. The framework couples a coding agent, evolving skill artifacts, and a deterministic evaluator grounded in physical simulation so that solver-specific strategies can be iteratively refined across tasks without modifying model weights or the underlying physics solver. We evaluate the framework on a benchmark spanning multiple metasurface inverse-design task types, with separate training-aligned and held-out task families. Evolved skills raise in-distribution task success from 38% to 74%, increase criteria pass fraction from 0.510 to 0.870, and reduce average attempts from 4.10 to 2.30. On held-out task families, binary success changes only marginally, but improvements in best margin together with shifts in error composition and agent behavior indicate partial transfer of workflow knowledge. These results suggest that the main value of skill evolution lies in accumulating reusable solver-specific expertise around reliable computational engines, thereby offering a practical path toward more autonomous and accessible metasurface inverse-design workflows.
Anatomical Prior-Driven Framework for Autonomous Robotic Cardiac Ultrasound Standard View Acquisition
Mar 22, 2026Cardiac ultrasound diagnosis is critical for cardiovascular disease assessment, but acquiring standard views remains highly operator-dependent. Existing medical segmentation models often yield anatomically inconsistent results in images with poor textural differentiation between distinct feature classes, while autonomous probe adjustment methods either rely on simplistic heuristic rules or black-box learning. To address these issues, our study proposed an anatomical prior (AP)-driven framework integrating cardiac structure segmentation and autonomous probe adjustment for standard view acquisition. A YOLO-based multi-class segmentation model augmented by a spatial-relation graph (SRG) module is designed to embed AP into the feature pyramid. Quantifiable anatomical features of standard views are extracted. Their priors are fitted to Gaussian distributions to construct probabilistic APs. The probe adjustment process of robotic ultrasound scanning is formalized as a reinforcement learning (RL) problem, with the RL state built from real-time anatomical features and the reward reflecting the AP matching. Experiments validate the efficacy of the framework. The SRG-YOLOv11s improves mAP50 by 11.3% and mIoU by 6.8% on the Special Case dataset, while the RL agent achieves a 92.5% success rate in simulation and 86.7% in phantom experiments.
PTalker: Personalized Speech-Driven 3D Talking Head Animation via Style Disentanglement and Modality Alignment
Dec 27, 2025Speech-driven 3D talking head generation aims to produce lifelike facial animations precisely synchronized with speech. While considerable progress has been made in achieving high lip-synchronization accuracy, existing methods largely overlook the intricate nuances of individual speaking styles, which limits personalization and realism. In this work, we present a novel framework for personalized 3D talking head animation, namely "PTalker". This framework preserves speaking style through style disentanglement from audio and facial motion sequences and enhances lip-synchronization accuracy through a three-level alignment mechanism between audio and mesh modalities. Specifically, to effectively disentangle style and content, we design disentanglement constraints that encode driven audio and motion sequences into distinct style and content spaces to enhance speaking style representation. To improve lip-synchronization accuracy, we adopt a modality alignment mechanism incorporating three aspects: spatial alignment using Graph Attention Networks to capture vertex connectivity in the 3D mesh structure, temporal alignment using cross-attention to capture and synchronize temporal dependencies, and feature alignment by top-k bidirectional contrastive losses and KL divergence constraints to ensure consistency between speech and mesh modalities. Extensive qualitative and quantitative experiments on public datasets demonstrate that PTalker effectively generates realistic, stylized 3D talking heads that accurately match identity-specific speaking styles, outperforming state-of-the-art methods. The source code and supplementary videos are available at: PTalker.
Foundation Model-based Evaluation of Neuropsychiatric Disorders: A Lifespan-Inclusive, Multi-Modal, and Multi-Lingual Study
Dec 24, 2025Neuropsychiatric disorders, such as Alzheimer's disease (AD), depression, and autism spectrum disorder (ASD), are characterized by linguistic and acoustic abnormalities, offering potential biomarkers for early detection. Despite the promise of multi-modal approaches, challenges like multi-lingual generalization and the absence of a unified evaluation framework persist. To address these gaps, we propose FEND (Foundation model-based Evaluation of Neuropsychiatric Disorders), a comprehensive multi-modal framework integrating speech and text modalities for detecting AD, depression, and ASD across the lifespan. Leveraging 13 multi-lingual datasets spanning English, Chinese, Greek, French, and Dutch, we systematically evaluate multi-modal fusion performance. Our results show that multi-modal fusion excels in AD and depression detection but underperforms in ASD due to dataset heterogeneity. We also identify modality imbalance as a prevalent issue, where multi-modal fusion fails to surpass the best mono-modal models. Cross-corpus experiments reveal robust performance in task- and language-consistent scenarios but noticeable degradation in multi-lingual and task-heterogeneous settings. By providing extensive benchmarks and a detailed analysis of performance-influencing factors, FEND advances the field of automated, lifespan-inclusive, and multi-lingual neuropsychiatric disorder assessment. We encourage researchers to adopt the FEND framework for fair comparisons and reproducible research.
Robotic Grinding Skills Learning Based on Geodesic Length Dynamic Motion Primitives
Apr 24, 2025



Learning grinding skills from human craftsmen via imitation learning has become a key research topic in robotic machining. Due to their strong generalization and robustness to external disturbances, Dynamical Movement Primitives (DMPs) offer a promising approach for robotic grinding skill learning. However, directly applying DMPs to grinding tasks faces challenges, such as low orientation accuracy, unsynchronized position-orientation-force, and limited generalization for surface trajectories. To address these issues, this paper proposes a robotic grinding skill learning method based on geodesic length DMPs (Geo-DMPs). First, a normalized 2D weighted Gaussian kernel and intrinsic mean clustering algorithm are developed to extract geometric features from multiple demonstrations. Then, an orientation manifold distance metric removes the time dependency in traditional orientation DMPs, enabling accurate orientation learning via Geo-DMPs. A synchronization encoding framework is further proposed to jointly model position, orientation, and force using a geodesic length-based phase function. This framework enables robotic grinding actions to be generated between any two surface points. Experiments on robotic chamfer grinding and free-form surface grinding validate that the proposed method achieves high geometric accuracy and generalization in skill encoding and generation. To our knowledge, this is the first attempt to use DMPs for jointly learning and generating grinding skills in position, orientation, and force on model-free surfaces, offering a novel path for robotic grinding.
Coordinated Power Smoothing Control for Wind Storage Integrated System with Physics-informed Deep Reinforcement Learning
Dec 17, 2024



The Wind Storage Integrated System with Power Smoothing Control (PSC) has emerged as a promising solution to ensure both efficient and reliable wind energy generation. However, existing PSC strategies overlook the intricate interplay and distinct control frequencies between batteries and wind turbines, and lack consideration of wake effect and battery degradation cost. In this paper, a novel coordinated control framework with hierarchical levels is devised to address these challenges effectively, which integrates the wake model and battery degradation model. In addition, after reformulating the problem as a Markov decision process, the multi-agent reinforcement learning method is introduced to overcome the bi-level characteristic of the problem. Moreover, a Physics-informed Neural Network-assisted Multi-agent Deep Deterministic Policy Gradient (PAMA-DDPG) algorithm is proposed to incorporate the power fluctuation differential equation and expedite the learning process. The effectiveness of the proposed methodology is evaluated through simulations conducted in four distinct scenarios using WindFarmSimulator (WFSim). The results demonstrate that the proposed algorithm facilitates approximately an 11% increase in total profit and a 19% decrease in power fluctuation compared to the traditional methods, thereby addressing the dual objectives of economic efficiency and grid-connected energy reliability.
Hard-Synth: Synthesizing Diverse Hard Samples for ASR using Zero-Shot TTS and LLM
Nov 20, 2024



Text-to-speech (TTS) models have been widely adopted to enhance automatic speech recognition (ASR) systems using text-only corpora, thereby reducing the cost of labeling real speech data. Existing research primarily utilizes additional text data and predefined speech styles supported by TTS models. In this paper, we propose Hard-Synth, a novel ASR data augmentation method that leverages large language models (LLMs) and advanced zero-shot TTS. Our approach employs LLMs to generate diverse in-domain text through rewriting, without relying on additional text data. Rather than using predefined speech styles, we introduce a hard prompt selection method with zero-shot TTS to clone speech styles that the ASR model finds challenging to recognize. Experiments demonstrate that Hard-Synth significantly enhances the Conformer model, achieving relative word error rate (WER) reductions of 6.5\%/4.4\% on LibriSpeech dev/test-other subsets. Additionally, we show that Hard-Synth is data-efficient and capable of reducing bias in ASR.
Legal Evalutions and Challenges of Large Language Models
Nov 15, 2024



In this paper, we review legal testing methods based on Large Language Models (LLMs), using the OPENAI o1 model as a case study to evaluate the performance of large models in applying legal provisions. We compare current state-of-the-art LLMs, including open-source, closed-source, and legal-specific models trained specifically for the legal domain. Systematic tests are conducted on English and Chinese legal cases, and the results are analyzed in depth. Through systematic testing of legal cases from common law systems and China, this paper explores the strengths and weaknesses of LLMs in understanding and applying legal texts, reasoning through legal issues, and predicting judgments. The experimental results highlight both the potential and limitations of LLMs in legal applications, particularly in terms of challenges related to the interpretation of legal language and the accuracy of legal reasoning. Finally, the paper provides a comprehensive analysis of the advantages and disadvantages of various types of models, offering valuable insights and references for the future application of AI in the legal field.
Leveraging Surgical Activity Grammar for Primary Intention Prediction in Laparoscopy Procedures
Sep 29, 2024



Surgical procedures are inherently complex and dynamic, with intricate dependencies and various execution paths. Accurate identification of the intentions behind critical actions, referred to as Primary Intentions (PIs), is crucial to understanding and planning the procedure. This paper presents a novel framework that advances PI recognition in instructional videos by combining top-down grammatical structure with bottom-up visual cues. The grammatical structure is based on a rich corpus of surgical procedures, offering a hierarchical perspective on surgical activities. A grammar parser, utilizing the surgical activity grammar, processes visual data obtained from laparoscopic images through surgical action detectors, ensuring a more precise interpretation of the visual information. Experimental results on the benchmark dataset demonstrate that our method outperforms existing surgical activity detectors that rely solely on visual features. Our research provides a promising foundation for developing advanced robotic surgical systems with enhanced planning and automation capabilities.
Evaluation of OpenAI o1: Opportunities and Challenges of AGI
Sep 27, 2024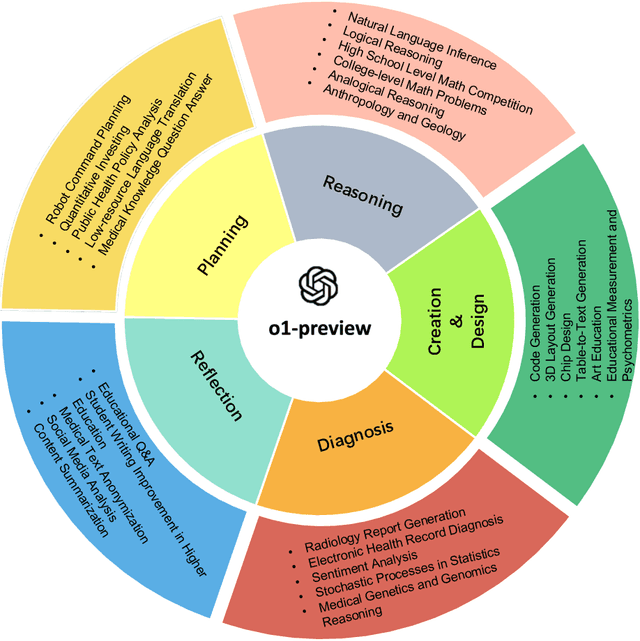


This comprehensive study evaluates the performance of OpenAI's o1-preview large language model across a diverse array of complex reasoning tasks, spanning multiple domains, including computer science, mathematics, natural sciences, medicine, linguistics, and social sciences. Through rigorous testing, o1-preview demonstrated remarkable capabilities, often achieving human-level or superior performance in areas ranging from coding challenges to scientific reasoning and from language processing to creative problem-solving. Key findings include: -83.3% success rate in solving complex competitive programming problems, surpassing many human experts. -Superior ability in generating coherent and accurate radiology reports, outperforming other evaluated models. -100% accuracy in high school-level mathematical reasoning tasks, providing detailed step-by-step solutions. -Advanced natural language inference capabilities across general and specialized domains like medicine. -Impressive performance in chip design tasks, outperforming specialized models in areas such as EDA script generation and bug analysis. -Remarkable proficiency in anthropology and geology, demonstrating deep understanding and reasoning in these specialized fields. -Strong capabilities in quantitative investing. O1 has comprehensive financial knowledge and statistical modeling skills. -Effective performance in social media analysis, including sentiment analysis and emotion recognition. The model excelled particularly in tasks requiring intricate reasoning and knowledge integration across various fields. While some limitations were observed, including occasional errors on simpler problems and challenges with certain highly specialized concepts, the overall results indicate significant progress towards artificial general intelligence.