 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuditing Training Data in Generative Music Models via Black-Box Membership Inference
May 28, 2026Recent advances in text-to-music generation enable high-fidelity synthesis of structured musical audio, raising growing concerns about data provenance, consent, and training transparency. These models are typically trained on large-scale corpora with little disclosure, leaving no practical mechanism to verify whether a particular audio sample was included in training. In this paper, we investigate black-box membership inference for generative music models, aiming to determine whether a candidate music sample was used during training, given only query access to the deployed system. Our key insight is that training membership induces systematically stronger semantic and structural alignment between a candidate sample and the model's generation conditioned on its caption. We query the target model with the associated caption and measure the relationship between the candidate audio and the generated output in a learned feature space. To capture features that separate members from non-members, we construct paired examples consisting of each track and its caption-conditioned generation from shadow models, and train a music auditor to classify membership. The auditor captures alignment patterns characteristic of training membership and generalizes to unseen target models in a fully black-box setting without access to model parameters or training metadata. Across multiple state-of-the-art music generators, our method achieves up to 98.6% accuracy, with false-positive and false-negative rates as low as 1.9% and 1.0%, demonstrating that reliable training-data auditing is feasible in realistic deployment scenarios.
Investigating Numerical Translation with Large Language Models
Jan 09, 2025


The inaccurate translation of numbers can lead to significant security issues, ranging from financial setbacks to medical inaccuracies. While large language models (LLMs) have made significant advancements in machine translation, their capacity for translating numbers has not been thoroughly explored. This study focuses on evaluating the reliability of LLM-based machine translation systems when handling numerical data. In order to systematically test the numerical translation capabilities of currently open source LLMs, we have constructed a numerical translation dataset between Chinese and English based on real business data, encompassing ten types of numerical translation. Experiments on the dataset indicate that errors in numerical translation are a common issue, with most open-source LLMs faltering when faced with our test scenarios. Especially when it comes to numerical types involving large units like ``million", ``billion", and "yi", even the latest llama3.1 8b model can have error rates as high as 20%. Finally, we introduce three potential strategies to mitigate the numerical mistranslations for large units.
"I've Heard of You!": Generate Spoken Named Entity Recognition Data for Unseen Entities
Dec 26, 2024



Spoken named entity recognition (NER) aims to identify named entities from speech, playing an important role in speech processing. New named entities appear every day, however, annotating their Spoken NER data is costly. In this paper, we demonstrate that existing Spoken NER systems perform poorly when dealing with previously unseen named entities. To tackle this challenge, we propose a method for generating Spoken NER data based on a named entity dictionary (NED) to reduce costs. Specifically, we first use a large language model (LLM) to generate sentences from the sampled named entities and then use a text-to-speech (TTS) system to generate the speech. Furthermore, we introduce a noise metric to filter out noisy data. To evaluate our approach, we release a novel Spoken NER benchmark along with a corresponding NED containing 8,853 entities. Experiment results show that our method achieves state-of-the-art (SOTA) performance in the in-domain, zero-shot domain adaptation, and fully zero-shot settings. Our data will be available at https://github.com/DeepLearnXMU/HeardU.
Hard-Synth: Synthesizing Diverse Hard Samples for ASR using Zero-Shot TTS and LLM
Nov 20, 2024



Text-to-speech (TTS) models have been widely adopted to enhance automatic speech recognition (ASR) systems using text-only corpora, thereby reducing the cost of labeling real speech data. Existing research primarily utilizes additional text data and predefined speech styles supported by TTS models. In this paper, we propose Hard-Synth, a novel ASR data augmentation method that leverages large language models (LLMs) and advanced zero-shot TTS. Our approach employs LLMs to generate diverse in-domain text through rewriting, without relying on additional text data. Rather than using predefined speech styles, we introduce a hard prompt selection method with zero-shot TTS to clone speech styles that the ASR model finds challenging to recognize. Experiments demonstrate that Hard-Synth significantly enhances the Conformer model, achieving relative word error rate (WER) reductions of 6.5\%/4.4\% on LibriSpeech dev/test-other subsets. Additionally, we show that Hard-Synth is data-efficient and capable of reducing bias in ASR.
Not All Languages are Equal: Insights into Multilingual Retrieval-Augmented Generation
Oct 29, 2024



RALMs (Retrieval-Augmented Language Models) broaden their knowledge scope by incorporating external textual resources. However, the multilingual nature of global knowledge necessitates RALMs to handle diverse languages, a topic that has received limited research focus. In this work, we propose \textit{Futurepedia}, a carefully crafted benchmark containing parallel texts across eight representative languages. We evaluate six multilingual RALMs using our benchmark to explore the challenges of multilingual RALMs. Experimental results reveal linguistic inequalities: 1) high-resource languages stand out in Monolingual Knowledge Extraction; 2) Indo-European languages lead RALMs to provide answers directly from documents, alleviating the challenge of expressing answers across languages; 3) English benefits from RALMs' selection bias and speaks louder in multilingual knowledge selection. Based on these findings, we offer advice for improving multilingual Retrieval Augmented Generation. For monolingual knowledge extraction, careful attention must be paid to cascading errors from translating low-resource languages into high-resource ones. In cross-lingual knowledge transfer, encouraging RALMs to provide answers within documents in different languages can improve transfer performance. For multilingual knowledge selection, incorporating more non-English documents and repositioning English documents can help mitigate RALMs' selection bias. Through comprehensive experiments, we underscore the complexities inherent in multilingual RALMs and offer valuable insights for future research.
ReliOcc: Towards Reliable Semantic Occupancy Prediction via Uncertainty Learning
Sep 26, 2024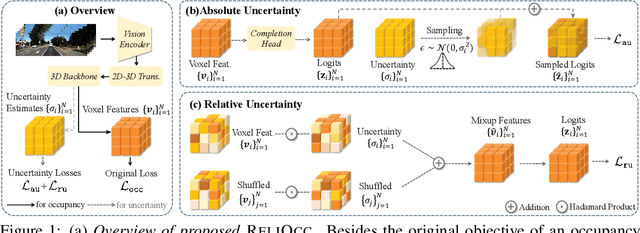
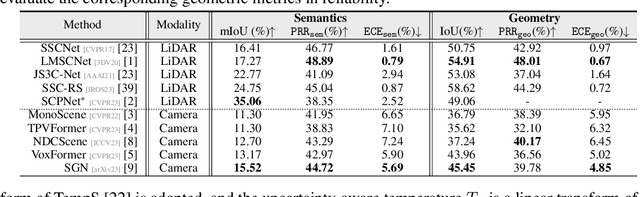
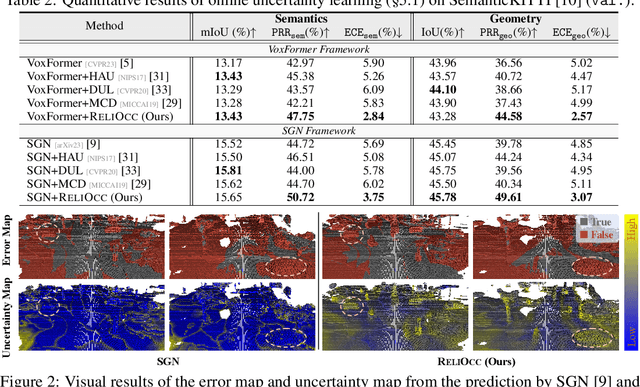
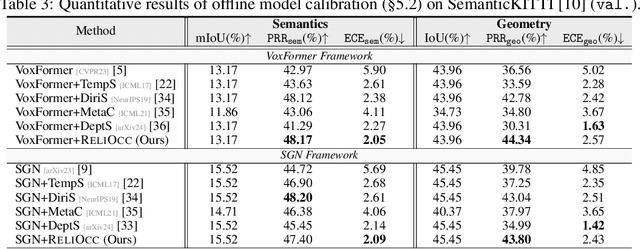
Vision-centric semantic occupancy prediction plays a crucial role in autonomous driving, which requires accurate and reliable predictions from low-cost sensors. Although having notably narrowed the accuracy gap with LiDAR, there is still few research effort to explore the reliability in predicting semantic occupancy from camera. In this paper, we conduct a comprehensive evaluation of existing semantic occupancy prediction models from a reliability perspective for the first time. Despite the gradual alignment of camera-based models with LiDAR in term of accuracy, a significant reliability gap persists. To addresses this concern, we propose ReliOcc, a method designed to enhance the reliability of camera-based occupancy networks. ReliOcc provides a plug-and-play scheme for existing models, which integrates hybrid uncertainty from individual voxels with sampling-based noise and relative voxels through mix-up learning. Besides, an uncertainty-aware calibration strategy is devised to further enhance model reliability in offline mode. Extensive experiments under various settings demonstrate that ReliOcc significantly enhances model reliability while maintaining the accuracy of both geometric and semantic predictions. Importantly, our proposed approach exhibits robustness to sensor failures and out of domain noises during inference.
TrafficGamer: Reliable and Flexible Traffic Simulation for Safety-Critical Scenarios with Game-Theoretic Oracles
Aug 28, 2024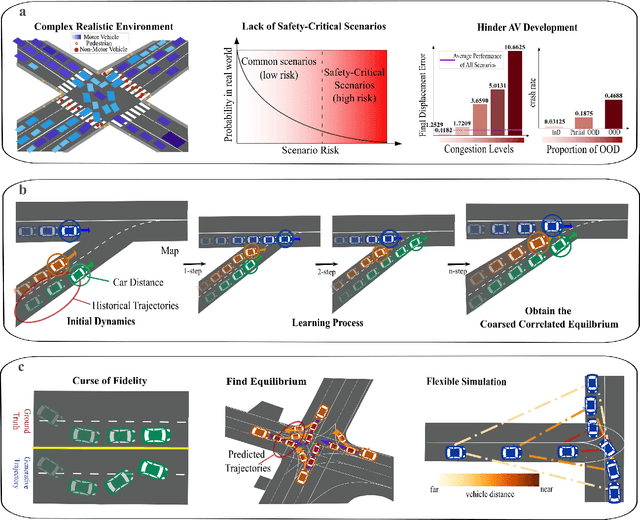
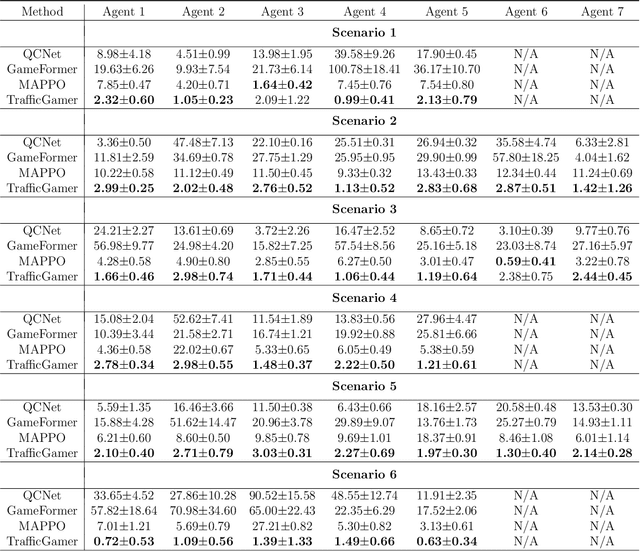
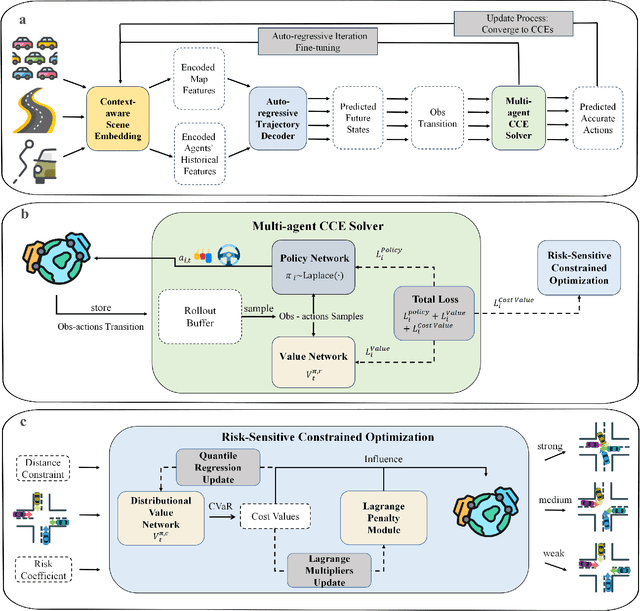
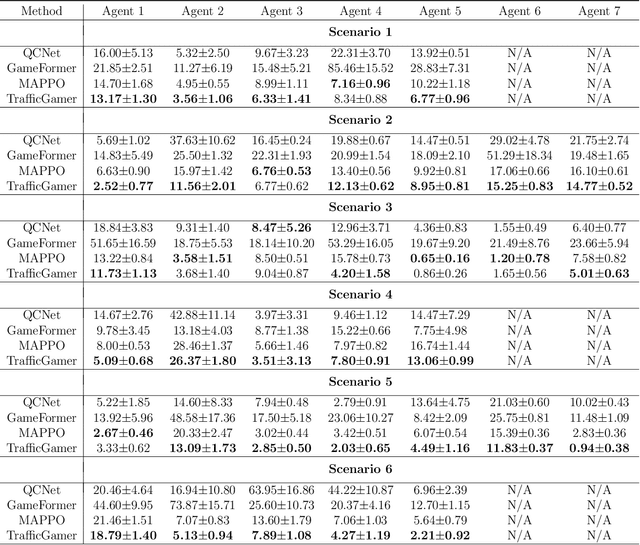
While modern Autonomous Vehicle (AV) systems can develop reliable driving policies under regular traffic conditions, they frequently struggle with safety-critical traffic scenarios. This difficulty primarily arises from the rarity of such scenarios in driving datasets and the complexities associated with predictive modeling among multiple vehicles. To support the testing and refinement of AV policies, simulating safety-critical traffic events is an essential challenge to be addressed. In this work, we introduce TrafficGamer, which facilitates game-theoretic traffic simulation by viewing common road driving as a multi-agent game. In evaluating the empirical performance across various real-world datasets, TrafficGamer ensures both fidelity and exploitability of the simulated scenarios, guaranteeing that they not only statically align with real-world traffic distribution but also efficiently capture equilibriums for representing safety-critical scenarios involving multiple agents. Additionally, the results demonstrate that TrafficGamer exhibits highly flexible simulation across various contexts. Specifically, we demonstrate that the generated scenarios can dynamically adapt to equilibriums of varying tightness by configuring risk-sensitive constraints during optimization. To the best of our knowledge, TrafficGamer is the first simulator capable of generating diverse traffic scenarios involving multiple agents. We have provided a demo webpage for the project at https://qiaoguanren.github.io/trafficgamer-demo/.
Label-efficient Semantic Scene Completion with Scribble Annotations
May 24, 2024



Semantic scene completion aims to infer the 3D geometric structures with semantic classes from camera or LiDAR, which provide essential occupancy information in autonomous driving. Prior endeavors concentrate on constructing the network or benchmark in a fully supervised manner. While the dense occupancy grids need point-wise semantic annotations, which incur expensive and tedious labeling costs. In this paper, we build a new label-efficient benchmark, named ScribbleSC, where the sparse scribble-based semantic labels are combined with dense geometric labels for semantic scene completion. In particular, we propose a simple yet effective approach called Scribble2Scene, which bridges the gap between the sparse scribble annotations and fully-supervision. Our method consists of geometric-aware auto-labelers construction and online model training with an offline-to-online distillation module to enhance the performance. Experiments on SemanticKITTI demonstrate that Scribble2Scene achieves competitive performance against the fully-supervised counterparts, showing 99% performance of the fully-supervised models with only 13.5% voxels labeled. Both annotations of ScribbleSC and our full implementation are available at https://github.com/songw-zju/Scribble2Scene.
Not All Voxels Are Equal: Hardness-Aware Semantic Scene Completion with Self-Distillation
Apr 18, 2024Semantic scene completion, also known as semantic occupancy prediction, can provide dense geometric and semantic information for autonomous vehicles, which attracts the increasing attention of both academia and industry. Unfortunately, existing methods usually formulate this task as a voxel-wise classification problem and treat each voxel equally in 3D space during training. As the hard voxels have not been paid enough attention, the performance in some challenging regions is limited. The 3D dense space typically contains a large number of empty voxels, which are easy to learn but require amounts of computation due to handling all the voxels uniformly for the existing models. Furthermore, the voxels in the boundary region are more challenging to differentiate than those in the interior. In this paper, we propose HASSC approach to train the semantic scene completion model with hardness-aware design. The global hardness from the network optimization process is defined for dynamical hard voxel selection. Then, the local hardness with geometric anisotropy is adopted for voxel-wise refinement. Besides, self-distillation strategy is introduced to make training process stable and consistent. Extensive experiments show that our HASSC scheme can effectively promote the accuracy of the baseline model without incurring the extra inference cost. Source code is available at: https://github.com/songw-zju/HASSC.
The Ninth NTIRE 2024 Efficient Super-Resolution Challenge Report
Apr 16, 2024



This paper provides a comprehensive review of the NTIRE 2024 challenge, focusing on efficient single-image super-resolution (ESR) solutions and their outcomes. The task of this challenge is to super-resolve an input image with a magnification factor of x4 based on pairs of low and corresponding high-resolution images. The primary objective is to develop networks that optimize various aspects such as runtime, parameters, and FLOPs, while still maintaining a peak signal-to-noise ratio (PSNR) of approximately 26.90 dB on the DIV2K_LSDIR_valid dataset and 26.99 dB on the DIV2K_LSDIR_test dataset. In addition, this challenge has 4 tracks including the main track (overall performance), sub-track 1 (runtime), sub-track 2 (FLOPs), and sub-track 3 (parameters). In the main track, all three metrics (ie runtime, FLOPs, and parameter count) were considered. The ranking of the main track is calculated based on a weighted sum-up of the scores of all other sub-tracks. In sub-track 1, the practical runtime performance of the submissions was evaluated, and the corresponding score was used to determine the ranking. In sub-track 2, the number of FLOPs was considered. The score calculated based on the corresponding FLOPs was used to determine the ranking. In sub-track 3, the number of parameters was considered. The score calculated based on the corresponding parameters was used to determine the ranking. RLFN is set as the baseline for efficiency measurement. The challenge had 262 registered participants, and 34 teams made valid submissions. They gauge the state-of-the-art in efficient single-image super-resolution. To facilitate the reproducibility of the challenge and enable other researchers to build upon these findings, the code and the pre-trained model of validated solutions are made publicly available at https://github.com/Amazingren/NTIRE2024_ESR/.