 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating Numerical Translation with Large Language Models
Jan 09, 2025


The inaccurate translation of numbers can lead to significant security issues, ranging from financial setbacks to medical inaccuracies. While large language models (LLMs) have made significant advancements in machine translation, their capacity for translating numbers has not been thoroughly explored. This study focuses on evaluating the reliability of LLM-based machine translation systems when handling numerical data. In order to systematically test the numerical translation capabilities of currently open source LLMs, we have constructed a numerical translation dataset between Chinese and English based on real business data, encompassing ten types of numerical translation. Experiments on the dataset indicate that errors in numerical translation are a common issue, with most open-source LLMs faltering when faced with our test scenarios. Especially when it comes to numerical types involving large units like ``million", ``billion", and "yi", even the latest llama3.1 8b model can have error rates as high as 20%. Finally, we introduce three potential strategies to mitigate the numerical mistranslations for large units.
Why Not Transform Chat Large Language Models to Non-English?
May 22, 2024
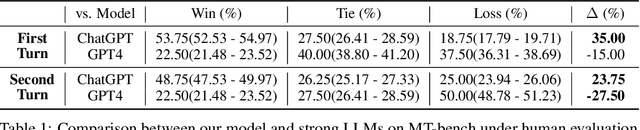


The scarcity of non-English data limits the development of non-English large language models (LLMs). Transforming English-centric LLMs to non-English has been identified as an effective and resource-efficient method. Previous works start from base LLMs and perform knowledge distillation (KD) with data generated by stronger LLMs, e.g. GPT-4. Compared to base LLMs, chat LLMs are further optimized for advanced abilities, e.g. multi-turn conversation and human preference alignment, and thus more powerful in both helpfulness and safety. However, transforming a chat LLM involves two critical issues: (1) How can we effectively transfer advanced abilities without their supervised data? (2) How can we prevent the original knowledge from catastrophic forgetting during transformation? We target these issues by introducing a simple framework called TransLLM. For the first issue, TransLLM divides the transfer problem into some common sub-tasks with the translation chain-of-thought, which uses the translation as the bridge between English and non-English step-by-step. We further enhance the performance of sub-tasks with publicly available data. For the second issue, we propose a method comprising two synergistic components: low-rank adaptation for training to maintain the original LLM parameters, and recovery KD, which utilizes data generated by the chat LLM itself to recover the original knowledge from the frozen parameters. In the experiments, we transform the LLaMA-2-chat-7B to the Thai language. Our method, using only single-turn data, outperforms strong baselines and ChatGPT on multi-turn benchmark MT-bench. Furthermore, our method, without safety data, rejects more harmful queries of safety benchmark AdvBench than both ChatGPT and GPT-4.
DeMPT: Decoding-enhanced Multi-phase Prompt Tuning for Making LLMs Be Better Context-aware Translators
Feb 23, 2024

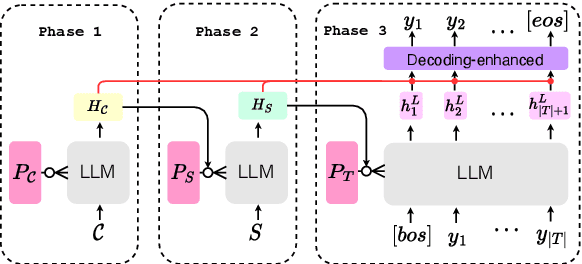

Generally, the decoder-only large language models (LLMs) are adapted to context-aware neural machine translation (NMT) in a concatenating way, where LLMs take the concatenation of the source sentence (i.e., intra-sentence context) and the inter-sentence context as the input, and then to generate the target tokens sequentially. This adaptation strategy, i.e., concatenation mode, considers intra-sentence and inter-sentence contexts with the same priority, despite an apparent difference between the two kinds of contexts. In this paper, we propose an alternative adaptation approach, named Decoding-enhanced Multi-phase Prompt Tuning (DeMPT), to make LLMs discriminately model and utilize the inter- and intra-sentence context and more effectively adapt LLMs to context-aware NMT. First, DeMPT divides the context-aware NMT process into three separate phases. During each phase, different continuous prompts are introduced to make LLMs discriminately model various information. Second, DeMPT employs a heuristic way to further discriminately enhance the utilization of the source-side inter- and intra-sentence information at the final decoding phase. Experiments show that our approach significantly outperforms the concatenation method, and further improves the performance of LLMs in discourse modeling.
Using Large Language Model for End-to-End Chinese ASR and NER
Jan 21, 2024Mapping speech tokens to the same feature space as text tokens has become the paradigm for the integration of speech modality into decoder-only large language models (LLMs). An alternative approach is to use an encoder-decoder architecture that incorporates speech features through cross-attention. This approach, however, has received less attention in the literature. In this work, we connect the Whisper encoder with ChatGLM3 and provide in-depth comparisons of these two approaches using Chinese automatic speech recognition (ASR) and name entity recognition (NER) tasks. We evaluate them not only by conventional metrics like the F1 score but also by a novel fine-grained taxonomy of ASR-NER errors. Our experiments reveal that encoder-decoder architecture outperforms decoder-only architecture with a short context, while decoder-only architecture benefits from a long context as it fully exploits all layers of the LLM. By using LLM, we significantly reduced the entity omission errors and improved the entity ASR accuracy compared to the Conformer baseline. Additionally, we obtained a state-of-the-art (SOTA) F1 score of 0.805 on the AISHELL-NER test set by using chain-of-thought (CoT) NER which first infers long-form ASR transcriptions and then predicts NER labels.
CB-Whisper: Contextual Biasing Whisper using TTS-based Keyword Spotting
Sep 18, 2023



End-to-end automatic speech recognition (ASR) systems often struggle to recognize rare name entities, such as personal names, organizations, or technical terms that are not frequently encountered in the training data. This paper presents Contextual Biasing Whisper (CB-Whisper), a novel ASR system based on OpenAI's Whisper model that performs keyword-spotting (KWS) before the decoder. The KWS module leverages text-to-speech (TTS) techniques and a convolutional neural network (CNN) classifier to match the features between the entities and the utterances. Experiments demonstrate that by incorporating predicted entities into a carefully designed spoken form prompt, the mixed-error-rate (MER) and entity recall of the Whisper model is significantly improved on three internal datasets and two open-sourced datasets that cover English-only, Chinese-only, and code-switching scenarios.
LogPrompt: Prompt Engineering Towards Zero-Shot and Interpretable Log Analysis
Aug 15, 2023



Automated log analysis is crucial in modern software-intensive systems for ensuring reliability and resilience throughout software maintenance and engineering life cycles. Existing methods perform tasks such as log parsing and log anomaly detection by providing a single prediction value without interpretation. However, given the increasing volume of system events, the limited interpretability of analysis results hinders analysts' trust and their ability to take appropriate actions. Moreover, these methods require substantial in-domain training data, and their performance declines sharply (by up to 62.5%) in online scenarios involving unseen logs from new domains, a common occurrence due to rapid software updates. In this paper, we propose LogPrompt, a novel zero-shot and interpretable log analysis approach. LogPrompt employs large language models (LLMs) to perform zero-shot log analysis tasks via a suite of advanced prompt strategies tailored for log tasks, which enhances LLMs' performance by up to 107.5% compared with simple prompts. Experiments on nine publicly available evaluation datasets across two tasks demonstrate that LogPrompt, despite using no training data, outperforms existing approaches trained on thousands of logs by up to around 50%. We also conduct a human evaluation of LogPrompt's interpretability, with six practitioners possessing over 10 years of experience, who highly rated the generated content in terms of usefulness and readability (averagely 4.42/5). LogPrompt also exhibits remarkable compatibility with open-source and smaller-scale LLMs, making it flexible for practical deployment.