 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTAPO: Translation Augmented Policy Optimization for Multilingual Mathematical Reasoning
Mar 26, 2026Large Language Models (LLMs) have demonstrated remarkable proficiency in English mathematical reasoning, yet a significant performance disparity persists in multilingual contexts, largely attributed to deficiencies in language understanding. To bridge this gap, we introduce Translation-Augmented Policy Optimization (TAPO), a novel reinforcement learning framework built upon GRPO. TAPO enforces an explicit alignment strategy where the model leverages English as a pivot and follows an understand-then-reason paradigm. Crucially, we employ a step-level relative advantage mechanism that decouples understanding from reasoning, allowing the integration of translation quality rewards without introducing optimization conflicts. Extensive experiments reveal that TAPO effectively synergizes language understanding with reasoning capabilities and is compatible with various models. It outperforms baseline methods in both multilingual mathematical reasoning and translation tasks, while generalizing well to unseen languages and out-of-domain tasks.
Self-Improving Multilingual Long Reasoning via Translation-Reasoning Integrated Training
Feb 05, 2026Long reasoning models often struggle in multilingual settings: they tend to reason in English for non-English questions; when constrained to reasoning in the question language, accuracies drop substantially. The struggle is caused by the limited abilities for both multilingual question understanding and multilingual reasoning. To address both problems, we propose TRIT (Translation-Reasoning Integrated Training), a self-improving framework that integrates the training of translation into multilingual reasoning. Without external feedback or additional multilingual data, our method jointly enhances multilingual question understanding and response generation. On MMATH, our method outperforms multiple baselines by an average of 7 percentage points, improving both answer correctness and language consistency. Further analysis reveals that integrating translation training improves cross-lingual question alignment by over 10 percentage points and enhances translation quality for both mathematical questions and general-domain text, with gains up to 8.4 COMET points on FLORES-200.
Making Mathematical Reasoning Adaptive
Oct 06, 2025



Mathematical reasoning is a primary indicator of large language models (LLMs) intelligence. However, existing LLMs exhibit failures of robustness and generalization. This paper attributes these deficiencies to spurious reasoning, i.e., producing answers from superficial features. To address this challenge, we propose the AdaR framework to enable adaptive reasoning, wherein models rely on problem-solving logic to produce answers. AdaR synthesizes logically equivalent queries by varying variable values, and trains models with RLVR on these data to penalize spurious logic while encouraging adaptive logic. To improve data quality, we extract the problem-solving logic from the original query and generate the corresponding answer by code execution, then apply a sanity check. Experimental results demonstrate that AdaR improves robustness and generalization, achieving substantial improvement in mathematical reasoning while maintaining high data efficiency. Analysis indicates that data synthesis and RLVR function in a coordinated manner to enable adaptive reasoning in LLMs. Subsequent analyses derive key design insights into the effect of critical factors and the applicability to instruct LLMs. Our project is available at https://github.com/LaiZhejian/AdaR
How does Alignment Enhance LLMs' Multilingual Capabilities? A Language Neurons Perspective
May 27, 2025Multilingual Alignment is an effective and representative paradigm to enhance LLMs' multilingual capabilities, which transfers the capabilities from the high-resource languages to the low-resource languages. Meanwhile, some researches on language-specific neurons reveal that there are language-specific neurons that are selectively activated in LLMs when processing different languages. This provides a new perspective to analyze and understand LLMs' mechanisms more specifically in multilingual scenarios. In this work, we propose a new finer-grained neuron identification algorithm, which detects language neurons~(including language-specific neurons and language-related neurons) and language-agnostic neurons. Furthermore, based on the distributional characteristics of different types of neurons, we divide the LLMs' internal process for multilingual inference into four parts: (1) multilingual understanding, (2) shared semantic space reasoning, (3) multilingual output space transformation, and (4) vocabulary space outputting. Additionally, we systematically analyze the models before and after alignment with a focus on different types of neurons. We also analyze the phenomenon of ''Spontaneous Multilingual Alignment''. Overall, our work conducts a comprehensive investigation based on different types of neurons, providing empirical results and valuable insights for better understanding multilingual alignment and multilingual capabilities of LLMs.
Alleviating Distribution Shift in Synthetic Data for Machine Translation Quality Estimation
Feb 28, 2025Quality Estimation (QE) models evaluate the quality of machine translations without reference translations, serving as the reward models for the translation task. Due to the data scarcity, synthetic data generation has emerged as a promising solution. However, synthetic QE data often suffers from distribution shift, which can manifest as discrepancies between pseudo and real translations, or in pseudo labels that do not align with human preferences. To tackle this issue, we introduce ADSQE, a novel framework for alleviating distribution shift in synthetic QE data. To reduce the difference between pseudo and real translations, we employ the constrained beam search algorithm and enhance translation diversity through the use of distinct generation models. ADSQE uses references, i.e., translation supervision signals, to guide both the generation and annotation processes, enhancing the quality of word-level labels. ADSE further identifies the shortest phrase covering consecutive error tokens, mimicking human annotation behavior, to assign the final phrase-level labels. Specially, we underscore that the translation model can not annotate translations of itself accurately. Extensive experiments demonstrate that ADSQE outperforms SOTA baselines like COMET in both supervised and unsupervised settings. Further analysis offers insights into synthetic data generation that could benefit reward models for other tasks.
Why Not Transform Chat Large Language Models to Non-English?
May 22, 2024
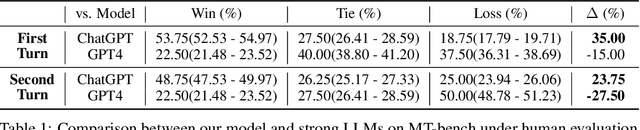


The scarcity of non-English data limits the development of non-English large language models (LLMs). Transforming English-centric LLMs to non-English has been identified as an effective and resource-efficient method. Previous works start from base LLMs and perform knowledge distillation (KD) with data generated by stronger LLMs, e.g. GPT-4. Compared to base LLMs, chat LLMs are further optimized for advanced abilities, e.g. multi-turn conversation and human preference alignment, and thus more powerful in both helpfulness and safety. However, transforming a chat LLM involves two critical issues: (1) How can we effectively transfer advanced abilities without their supervised data? (2) How can we prevent the original knowledge from catastrophic forgetting during transformation? We target these issues by introducing a simple framework called TransLLM. For the first issue, TransLLM divides the transfer problem into some common sub-tasks with the translation chain-of-thought, which uses the translation as the bridge between English and non-English step-by-step. We further enhance the performance of sub-tasks with publicly available data. For the second issue, we propose a method comprising two synergistic components: low-rank adaptation for training to maintain the original LLM parameters, and recovery KD, which utilizes data generated by the chat LLM itself to recover the original knowledge from the frozen parameters. In the experiments, we transform the LLaMA-2-chat-7B to the Thai language. Our method, using only single-turn data, outperforms strong baselines and ChatGPT on multi-turn benchmark MT-bench. Furthermore, our method, without safety data, rejects more harmful queries of safety benchmark AdvBench than both ChatGPT and GPT-4.
NJUNLP's Participation for the WMT2023 Quality Estimation Shared Task
Sep 23, 2023We introduce the submissions of the NJUNLP team to the WMT 2023 Quality Estimation (QE) shared task. Our team submitted predictions for the English-German language pair on all two sub-tasks: (i) sentence- and word-level quality prediction; and (ii) fine-grained error span detection. This year, we further explore pseudo data methods for QE based on NJUQE framework (https://github.com/NJUNLP/njuqe). We generate pseudo MQM data using parallel data from the WMT translation task. We pre-train the XLMR large model on pseudo QE data, then fine-tune it on real QE data. At both stages, we jointly learn sentence-level scores and word-level tags. Empirically, we conduct experiments to find the key hyper-parameters that improve the performance. Technically, we propose a simple method that covert the word-level outputs to fine-grained error span results. Overall, our models achieved the best results in English-German for both word-level and fine-grained error span detection sub-tasks by a considerable margin.