 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDuPO: Enabling Reliable LLM Self-Verification via Dual Preference Optimization
Aug 20, 2025We present DuPO, a dual learning-based preference optimization framework that generates annotation-free feedback via a generalized duality. DuPO addresses two key limitations: Reinforcement Learning with Verifiable Rewards (RLVR)'s reliance on costly labels and applicability restricted to verifiable tasks, and traditional dual learning's restriction to strictly dual task pairs (e.g., translation and back-translation). Specifically, DuPO decomposes a primal task's input into known and unknown components, then constructs its dual task to reconstruct the unknown part using the primal output and known information (e.g., reversing math solutions to recover hidden variables), broadening applicability to non-invertible tasks. The quality of this reconstruction serves as a self-supervised reward to optimize the primal task, synergizing with LLMs' ability to instantiate both tasks via a single model. Empirically, DuPO achieves substantial gains across diverse tasks: it enhances the average translation quality by 2.13 COMET over 756 directions, boosts the mathematical reasoning accuracy by an average of 6.4 points on three challenge benchmarks, and enhances performance by 9.3 points as an inference-time reranker (trading computation for accuracy). These results position DuPO as a scalable, general, and annotation-free paradigm for LLM optimization.
How does Alignment Enhance LLMs' Multilingual Capabilities? A Language Neurons Perspective
May 27, 2025Multilingual Alignment is an effective and representative paradigm to enhance LLMs' multilingual capabilities, which transfers the capabilities from the high-resource languages to the low-resource languages. Meanwhile, some researches on language-specific neurons reveal that there are language-specific neurons that are selectively activated in LLMs when processing different languages. This provides a new perspective to analyze and understand LLMs' mechanisms more specifically in multilingual scenarios. In this work, we propose a new finer-grained neuron identification algorithm, which detects language neurons~(including language-specific neurons and language-related neurons) and language-agnostic neurons. Furthermore, based on the distributional characteristics of different types of neurons, we divide the LLMs' internal process for multilingual inference into four parts: (1) multilingual understanding, (2) shared semantic space reasoning, (3) multilingual output space transformation, and (4) vocabulary space outputting. Additionally, we systematically analyze the models before and after alignment with a focus on different types of neurons. We also analyze the phenomenon of ''Spontaneous Multilingual Alignment''. Overall, our work conducts a comprehensive investigation based on different types of neurons, providing empirical results and valuable insights for better understanding multilingual alignment and multilingual capabilities of LLMs.
R-PRM: Reasoning-Driven Process Reward Modeling
Mar 27, 2025



Large language models (LLMs) inevitably make mistakes when performing step-by-step mathematical reasoning. Process Reward Models (PRMs) have emerged as a promising solution by evaluating each reasoning step. However, existing PRMs typically output evaluation scores directly, limiting both learning efficiency and evaluation accuracy, which is further exacerbated by the scarcity of annotated data. To address these issues, we propose Reasoning-Driven Process Reward Modeling (R-PRM). First, we leverage stronger LLMs to generate seed data from limited annotations, effectively bootstrapping our model's reasoning capabilities and enabling comprehensive step-by-step evaluation. Second, we further enhance performance through preference optimization, without requiring additional annotated data. Third, we introduce inference-time scaling to fully harness the model's reasoning potential. Extensive experiments demonstrate R-PRM's effectiveness: on ProcessBench and PRMBench, it surpasses strong baselines by 11.9 and 8.5 points in F1 scores, respectively. When applied to guide mathematical reasoning, R-PRM achieves consistent accuracy improvements of over 8.5 points across six challenging datasets. Further analysis reveals that R-PRM exhibits more comprehensive evaluation and stronger generalization capabilities, thereby highlighting its significant potential.
Multilingual Contrastive Decoding via Language-Agnostic Layers Skipping
Jul 15, 2024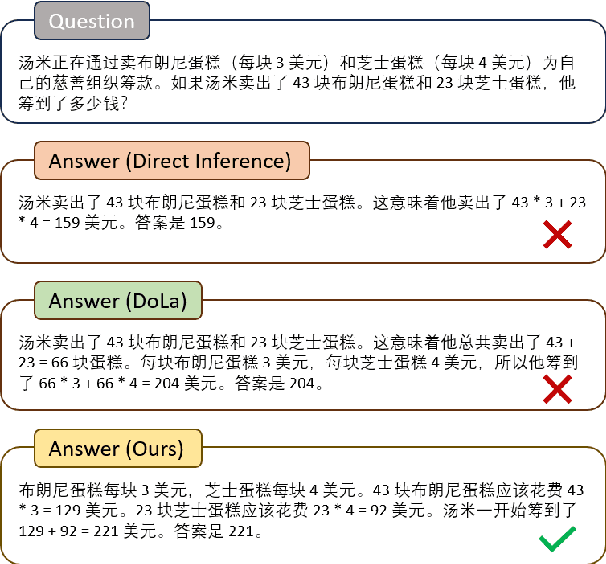
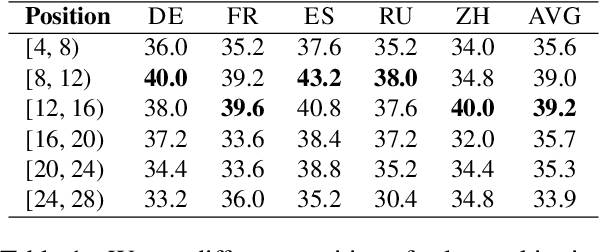
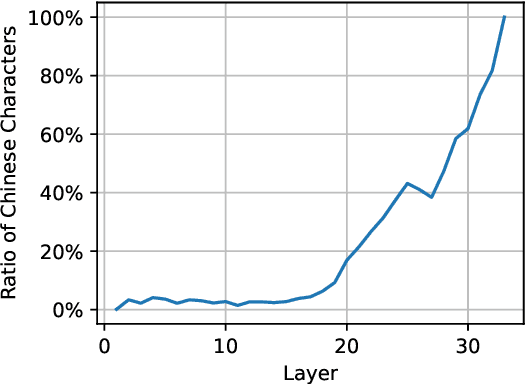
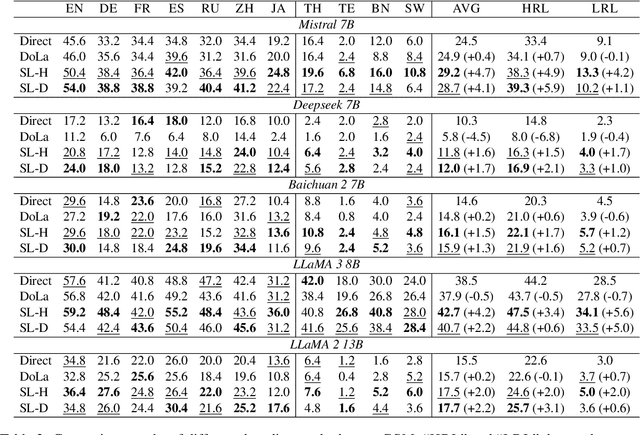
Decoding by contrasting layers (DoLa), is designed to improve the generation quality of large language models (LLMs) by contrasting the prediction probabilities between an early exit output (amateur logits) and the final output (expert logits). However, we find that this approach does not work well on non-English tasks. Inspired by previous interpretability work on language transition during the model's forward pass, we discover that this issue arises from a language mismatch between early exit output and final output. In this work, we propose an improved contrastive decoding algorithm that is effective for diverse languages beyond English. To obtain more helpful amateur logits, we devise two strategies to skip a set of bottom, language-agnostic layers based on our preliminary analysis. Experimental results on multilingual reasoning benchmarks demonstrate that our proposed method outperforms previous contrastive decoding baselines and substantially improves LLM's chain-of-thought reasoning accuracy across 11 languages. The project will be available at: https://github.com/NJUNLP/SkipLayerCD.
Why Not Transform Chat Large Language Models to Non-English?
May 22, 2024
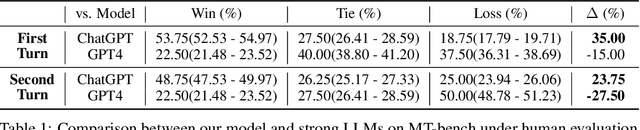


The scarcity of non-English data limits the development of non-English large language models (LLMs). Transforming English-centric LLMs to non-English has been identified as an effective and resource-efficient method. Previous works start from base LLMs and perform knowledge distillation (KD) with data generated by stronger LLMs, e.g. GPT-4. Compared to base LLMs, chat LLMs are further optimized for advanced abilities, e.g. multi-turn conversation and human preference alignment, and thus more powerful in both helpfulness and safety. However, transforming a chat LLM involves two critical issues: (1) How can we effectively transfer advanced abilities without their supervised data? (2) How can we prevent the original knowledge from catastrophic forgetting during transformation? We target these issues by introducing a simple framework called TransLLM. For the first issue, TransLLM divides the transfer problem into some common sub-tasks with the translation chain-of-thought, which uses the translation as the bridge between English and non-English step-by-step. We further enhance the performance of sub-tasks with publicly available data. For the second issue, we propose a method comprising two synergistic components: low-rank adaptation for training to maintain the original LLM parameters, and recovery KD, which utilizes data generated by the chat LLM itself to recover the original knowledge from the frozen parameters. In the experiments, we transform the LLaMA-2-chat-7B to the Thai language. Our method, using only single-turn data, outperforms strong baselines and ChatGPT on multi-turn benchmark MT-bench. Furthermore, our method, without safety data, rejects more harmful queries of safety benchmark AdvBench than both ChatGPT and GPT-4.
Question Translation Training for Better Multilingual Reasoning
Jan 15, 2024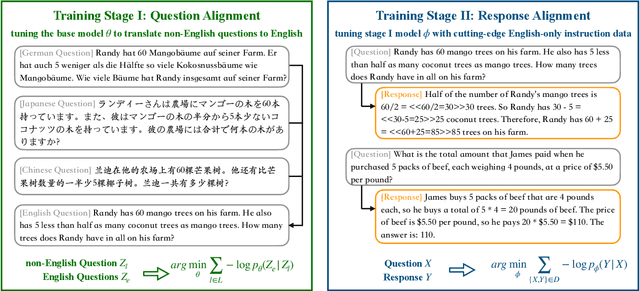
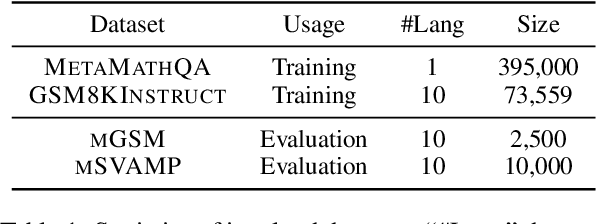


Large language models show compelling performance on reasoning tasks but they tend to perform much worse in languages other than English. This is unsurprising given that their training data largely consists of English text and instructions. A typical solution is to translate instruction data into all languages of interest, and then train on the resulting multilingual data, which is called translate-training. This approach not only incurs high cost, but also results in poorly translated data due to the non-standard formatting of chain-of-thought and mathematical reasoning instructions. In this paper, we explore the benefits of question alignment, where we train the model to translate reasoning questions into English by finetuning on X-English question data. In this way we perform targetted, in-domain language alignment which makes best use of English instruction data to unlock the LLMs' multilingual reasoning abilities. Experimental results on LLaMA2-13B show that question alignment leads to consistent improvements over the translate-training approach: an average improvement of 11.3\% and 16.1\% accuracy across ten languages on the MGSM and MSVAMP maths reasoning benchmarks (The project will be available at: https://github.com/NJUNLP/QAlign).
MAPO: Advancing Multilingual Reasoning through Multilingual Alignment-as-Preference Optimization
Jan 12, 2024Though reasoning abilities are considered language-agnostic, existing LLMs exhibit inconsistent reasoning abilities across different languages, e.g., reasoning in a pivot language is superior to other languages due to the imbalance of multilingual training data.To enhance reasoning abilities in non-pivot languages, we propose an alignment-as-preference optimization framework. Specifically, we adopt an open-source translation model to estimate the consistency between answers in non-pivot and pivot languages. We further adopt the answer consistency as the preference for DPO or PPO thus optimizing the lesser reasoning. Experiments show that our method significantly improves the model's multilingual reasoning, with better reasoning consistency across languages. Our framework achieved a 13.7% accuracy improvement on out-of-domain datasets MSVAMP while preserving the competitive performance on MGSM. Moreover, we find that iterative DPO is helpful for further alignment and improvement of the model's multilingual mathematical reasoning ability, further pushing the improvement to 16.7%
Exploring the Dialogue Comprehension Ability of Large Language Models
Nov 16, 2023



LLMs may interact with users in the form of dialogue and generate responses following their instructions, which naturally require dialogue comprehension abilities. However, dialogue comprehension is a general language ability which is hard to be evaluated directly. In this work, we propose to perform the evaluation with the help of the dialogue summarization task. Beside evaluating and analyzing the dialogue summarization performance (DIAC-Sum) of different LLMs, we also derive factual questions from the generated summaries and use them as a more flexible measurement of dialogue comprehension (DIAC-FactQA). Our evaluation shows that, on average, 27% of the summaries generated by LLMs contain factual inconsistency. Even ChatGPT, the strongest model evaluated, has such errors in 16% of its summaries. For answering the factual questions, which is more challenging, the average error rate of all evaluated LLMs is 37.2%. Both results indicate serious deficiencies. Detailed analysis shows that the understanding of subject/object of the conversation is still the most challenging problem for LLMs. Furthermore, to stimulate and enhance the dialogue comprehension ability of LLMs, we propose a fine-tuning paradigm with auto-constructed multi-task data. The experimental results demonstrate that our method achieved an error rate improvement of 10.9% on DIAC-FactQA.
CoP: Factual Inconsistency Detection by Controlling the Preference
Dec 03, 2022Abstractive summarization is the process of generating a summary given a document as input. Although significant progress has been made, the factual inconsistency between the document and the generated summary still limits its practical applications. Previous work found that the probabilities assigned by the generation model reflect its preferences for the generated summary, including the preference for factual consistency, and the preference for the language or knowledge prior as well. To separate the preference for factual consistency, we propose an unsupervised framework named CoP by controlling the preference of the generation model with the help of prompt. More specifically, the framework performs an extra inference step in which a text prompt is introduced as an additional input. In this way, another preference is described by the generation probability of this extra inference process. The difference between the above two preferences, i.e. the difference between the probabilities, could be used as measurements for detecting factual inconsistencies. Interestingly, we found that with the properly designed prompt, our framework could evaluate specific preferences and serve as measurements for fine-grained categories of inconsistency, such as entity-related inconsistency, coreference-related inconsistency, etc. Moreover, our framework could also be extended to the supervised setting to learn better prompt from the labeled data as well. Experiments show that our framework achieves new SOTA results on three factual inconsistency detection tasks.