 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgents of Chaos
Feb 23, 2026We report an exploratory red-teaming study of autonomous language-model-powered agents deployed in a live laboratory environment with persistent memory, email accounts, Discord access, file systems, and shell execution. Over a two-week period, twenty AI researchers interacted with the agents under benign and adversarial conditions. Focusing on failures emerging from the integration of language models with autonomy, tool use, and multi-party communication, we document eleven representative case studies. Observed behaviors include unauthorized compliance with non-owners, disclosure of sensitive information, execution of destructive system-level actions, denial-of-service conditions, uncontrolled resource consumption, identity spoofing vulnerabilities, cross-agent propagation of unsafe practices, and partial system takeover. In several cases, agents reported task completion while the underlying system state contradicted those reports. We also report on some of the failed attempts. Our findings establish the existence of security-, privacy-, and governance-relevant vulnerabilities in realistic deployment settings. These behaviors raise unresolved questions regarding accountability, delegated authority, and responsibility for downstream harms, and warrant urgent attention from legal scholars, policymakers, and researchers across disciplines. This report serves as an initial empirical contribution to that broader conversation.
Mechanisms of AI Protein Folding in ESMFold
Feb 05, 2026How do protein structure prediction models fold proteins? We investigate this question by tracing how ESMFold folds a beta hairpin, a prevalent structural motif. Through counterfactual interventions on model latents, we identify two computational stages in the folding trunk. In the first stage, early blocks initialize pairwise biochemical signals: residue identities and associated biochemical features such as charge flow from sequence representations into pairwise representations. In the second stage, late blocks develop pairwise spatial features: distance and contact information accumulate in the pairwise representation. We demonstrate that the mechanisms underlying structural decisions of ESMFold can be localized, traced through interpretable representations, and manipulated with strong causal effects.
In-Context Learning Without Copying
Nov 07, 2025Induction heads are attention heads that perform inductive copying by matching patterns from earlier context and copying their continuations verbatim. As models develop induction heads, they often experience a sharp drop in training loss, a phenomenon cited as evidence that induction heads may serve as a prerequisite for more complex in-context learning (ICL) capabilities. In this work, we ask whether transformers can still acquire ICL capabilities when inductive copying is suppressed. We propose Hapax, a setting where we omit the loss contribution of any token that can be correctly predicted by induction heads. Despite a significant reduction in inductive copying, performance on abstractive ICL tasks (i.e., tasks where the answer is not contained in the input context) remains comparable and surpasses the vanilla model on 13 of 21 tasks, even though 31.7\% of tokens are omitted from the loss. Furthermore, our model achieves lower loss values on token positions that cannot be predicted correctly by induction heads. Mechanistic analysis further shows that models trained with Hapax develop fewer and weaker induction heads but still preserve ICL capabilities. Taken together, our findings indicate that inductive copying is not essential for learning abstractive ICL mechanisms.
Discovering Forbidden Topics in Language Models
May 26, 2025Refusal discovery is the task of identifying the full set of topics that a language model refuses to discuss. We introduce this new problem setting and develop a refusal discovery method, LLM-crawler, that uses token prefilling to find forbidden topics. We benchmark the LLM-crawler on Tulu-3-8B, an open-source model with public safety tuning data. Our crawler manages to retrieve 31 out of 36 topics within a budget of 1000 prompts. Next, we scale the crawl to a frontier model using the prefilling option of Claude-Haiku. Finally, we crawl three widely used open-weight models: Llama-3.3-70B and two of its variants finetuned for reasoning: DeepSeek-R1-70B and Perplexity-R1-1776-70B. DeepSeek-R1-70B reveals patterns consistent with censorship tuning: The model exhibits "thought suppression" behavior that indicates memorization of CCP-aligned responses. Although Perplexity-R1-1776-70B is robust to censorship, LLM-crawler elicits CCP-aligned refusals answers in the quantized model. Our findings highlight the critical need for refusal discovery methods to detect biases, boundaries, and alignment failures of AI systems.
The Geometry of Self-Verification in a Task-Specific Reasoning Model
Apr 19, 2025

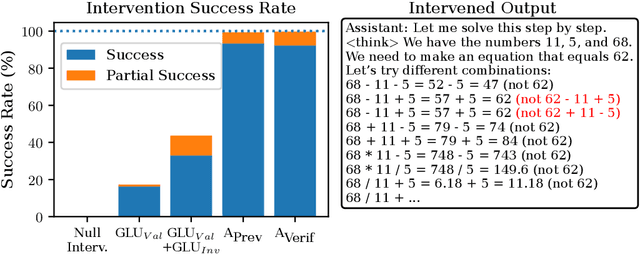

How do reasoning models verify their own answers? We study this question by training a model using DeepSeek R1's recipe on the CountDown task. We leverage the fact that preference tuning leads to mode collapse, resulting in a model that always produces highly structured and easily parse-able chain-of-thought sequences. With this setup, we do a top-down and bottom-up analysis to reverse-engineer how the model verifies its outputs. Our top-down analysis reveals Gated Linear Unit (GLU) weights encoding verification-related tokens, such as ``success'' or ``incorrect'', which activate according to the correctness of the model's reasoning steps. Our bottom-up analysis reveals that ``previous-token heads'' are mainly responsible for model verification. Our analyses meet in the middle: drawing inspiration from inter-layer communication channels, we use the identified GLU vectors to localize as few as three attention heads that can disable model verification, pointing to a necessary component of a potentially larger verification circuit.
Localized Cultural Knowledge is Conserved and Controllable in Large Language Models
Apr 14, 2025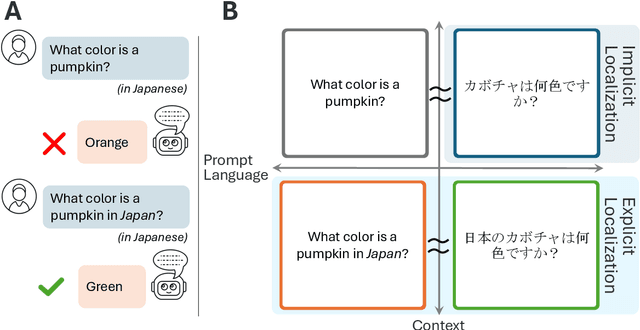

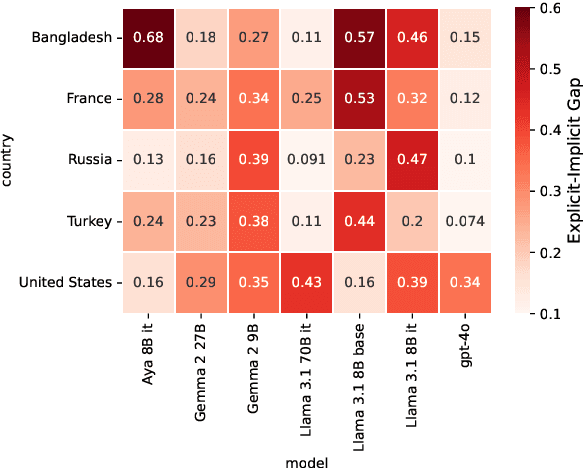
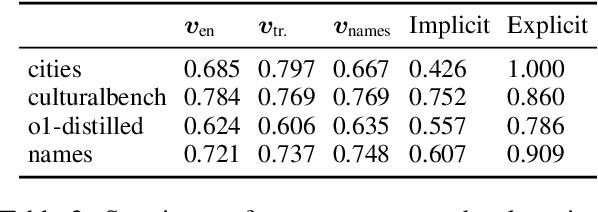
Just as humans display language patterns influenced by their native tongue when speaking new languages, LLMs often default to English-centric responses even when generating in other languages. Nevertheless, we observe that local cultural information persists within the models and can be readily activated for cultural customization. We first demonstrate that explicitly providing cultural context in prompts significantly improves the models' ability to generate culturally localized responses. We term the disparity in model performance with versus without explicit cultural context the explicit-implicit localization gap, indicating that while cultural knowledge exists within LLMs, it may not naturally surface in multilingual interactions if cultural context is not explicitly provided. Despite the explicit prompting benefit, however, the answers reduce in diversity and tend toward stereotypes. Second, we identify an explicit cultural customization vector, conserved across all non-English languages we explore, which enables LLMs to be steered from the synthetic English cultural world-model toward each non-English cultural world. Steered responses retain the diversity of implicit prompting and reduce stereotypes to dramatically improve the potential for customization. We discuss the implications of explicit cultural customization for understanding the conservation of alternative cultural world models within LLMs, and their controllable utility for translation, cultural customization, and the possibility of making the explicit implicit through soft control for expanded LLM function and appeal.
Controlling Latent Diffusion Using Latent CLIP
Mar 11, 2025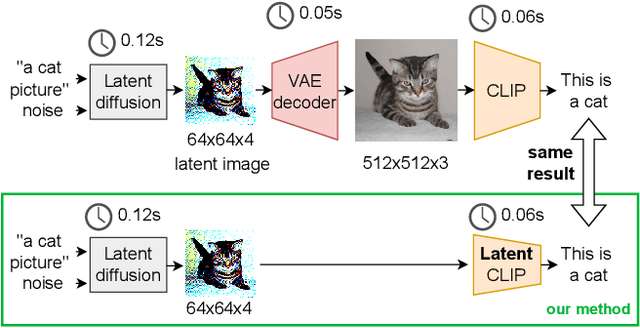
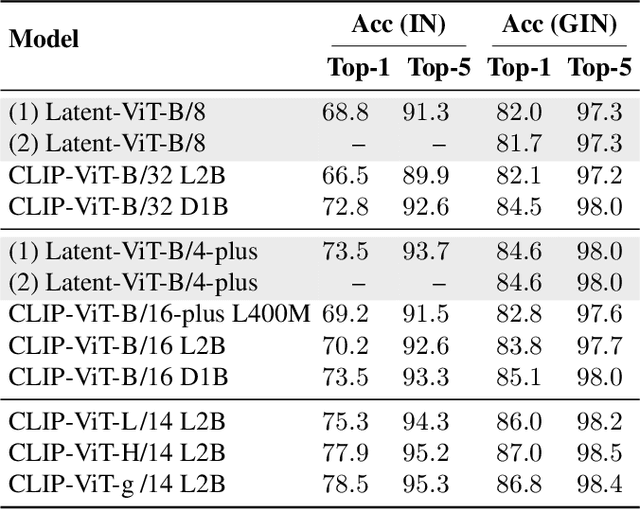
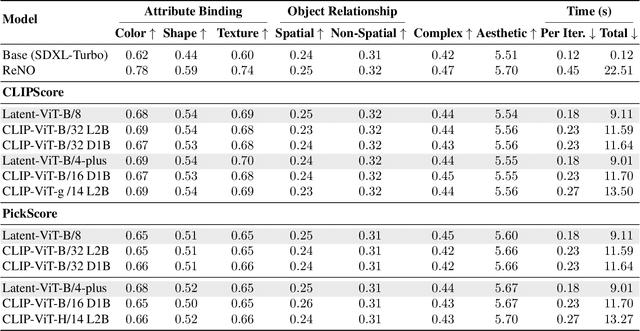

Instead of performing text-conditioned denoising in the image domain, latent diffusion models (LDMs) operate in latent space of a variational autoencoder (VAE), enabling more efficient processing at reduced computational costs. However, while the diffusion process has moved to the latent space, the contrastive language-image pre-training (CLIP) models, as used in many image processing tasks, still operate in pixel space. Doing so requires costly VAE-decoding of latent images before they can be processed. In this paper, we introduce Latent-CLIP, a CLIP model that operates directly in the latent space. We train Latent-CLIP on 2.7B pairs of latent images and descriptive texts, and show that it matches zero-shot classification performance of similarly sized CLIP models on both the ImageNet benchmark and a LDM-generated version of it, demonstrating its effectiveness in assessing both real and generated content. Furthermore, we construct Latent-CLIP rewards for reward-based noise optimization (ReNO) and show that they match the performance of their CLIP counterparts on GenEval and T2I-CompBench while cutting the cost of the total pipeline by 21%. Finally, we use Latent-CLIP to guide generation away from harmful content, achieving strong performance on the inappropriate image prompts (I2P) benchmark and a custom evaluation, without ever requiring the costly step of decoding intermediate images.
Large Language Models Share Representations of Latent Grammatical Concepts Across Typologically Diverse Languages
Jan 10, 2025



Human bilinguals often use similar brain regions to process multiple languages, depending on when they learned their second language and their proficiency. In large language models (LLMs), how are multiple languages learned and encoded? In this work, we explore the extent to which LLMs share representations of morphosyntactic concepts such as grammatical number, gender, and tense across languages. We train sparse autoencoders on Llama-3-8B and Aya-23-8B, and demonstrate that abstract grammatical concepts are often encoded in feature directions shared across many languages. We use causal interventions to verify the multilingual nature of these representations; specifically, we show that ablating only multilingual features decreases classifier performance to near-chance across languages. We then use these features to precisely modify model behavior in a machine translation task; this demonstrates both the generality and selectivity of these feature's roles in the network. Our findings suggest that even models trained predominantly on English data can develop robust, cross-lingual abstractions of morphosyntactic concepts.
Byte BPE Tokenization as an Inverse string Homomorphism
Dec 04, 2024



Tokenization is an important preprocessing step in the training and inference of large language models (LLMs). While there has been extensive research on the expressive power of the neural achitectures used in LLMs, the impact of tokenization has not been well understood. In this work, we demonstrate that tokenization, irrespective of the algorithm used, acts as an inverse homomorphism between strings and tokens. This suggests that the character space of the source language and the token space of the tokenized language are homomorphic, preserving the structural properties of the source language. Additionally, we explore the concept of proper tokenization, which refers to an unambiguous tokenization returned from the tokenizer. Our analysis reveals that the expressiveness of neural architectures in recognizing context-free languages is not affected by tokenization.
Separating Tongue from Thought: Activation Patching Reveals Language-Agnostic Concept Representations in Transformers
Nov 13, 2024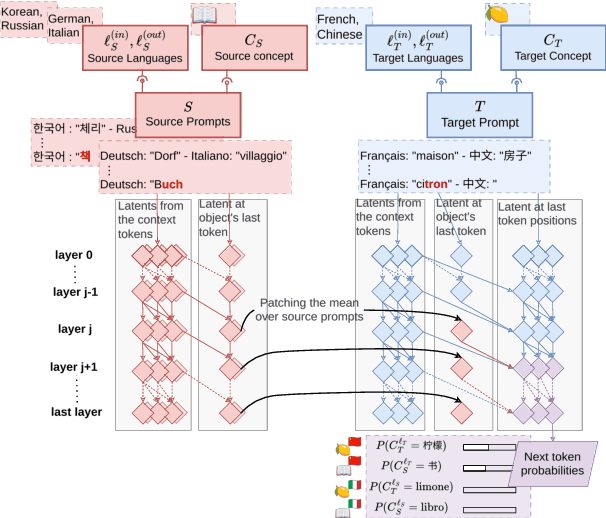
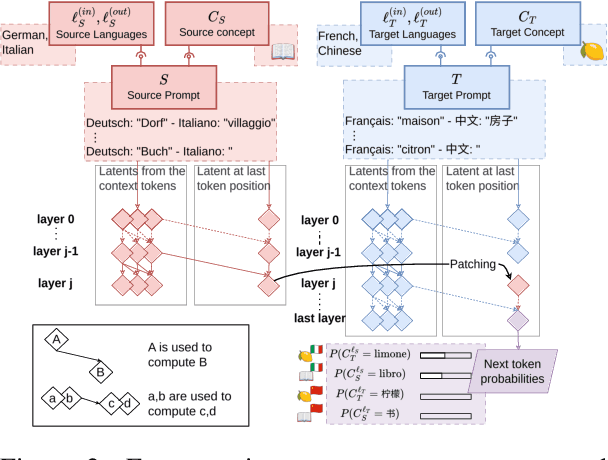
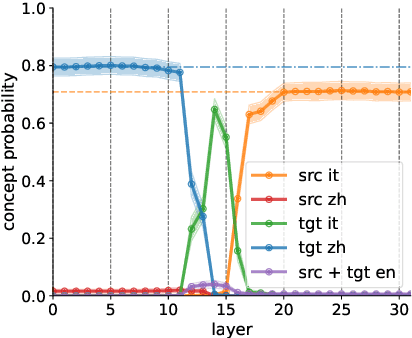
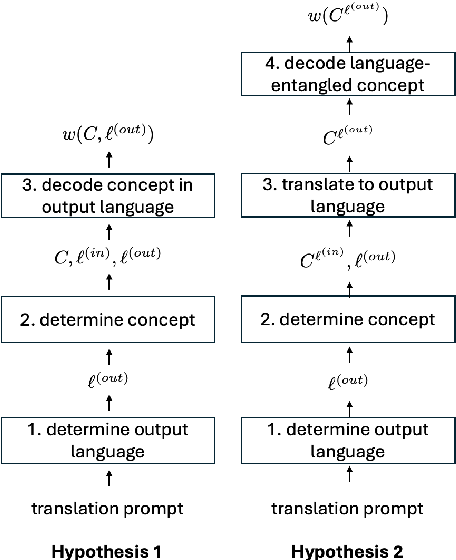
A central question in multilingual language modeling is whether large language models (LLMs) develop a universal concept representation, disentangled from specific languages. In this paper, we address this question by analyzing latent representations (latents) during a word translation task in transformer-based LLMs. We strategically extract latents from a source translation prompt and insert them into the forward pass on a target translation prompt. By doing so, we find that the output language is encoded in the latent at an earlier layer than the concept to be translated. Building on this insight, we conduct two key experiments. First, we demonstrate that we can change the concept without changing the language and vice versa through activation patching alone. Second, we show that patching with the mean over latents across different languages does not impair and instead improves the models' performance in translating the concept. Our results provide evidence for the existence of language-agnostic concept representations within the investigated models.