 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond the Rabbit Hole: Mapping the Relational Harms of QAnon Radicalization
Jan 25, 2026The rise of conspiracy theories has created far-reaching societal harm in the public discourse by eroding trust and fueling polarization. Beyond this public impact lies a deeply personal toll on the friends and families of conspiracy believers, a dimension often overlooked in large-scale computational research. This study fills this gap by systematically mapping radicalization journeys and quantifying the associated emotional toll inflicted on loved ones. We use the prominent case of QAnon as a case study, analyzing 12747 narratives from the r/QAnonCasualties support community through a novel mixed-methods approach. First, we use topic modeling (BERTopic) to map the radicalization trajectories, identifying key pre-existing conditions, triggers, and post-radicalization characteristics. From this, we apply an LDA-based graphical model to uncover six recurring archetypes of QAnon adherents, which we term "radicalization personas." Finally, using LLM-assisted emotion detection and regression modeling, we link these personas to the specific emotional toll reported by narrators. Our findings reveal that these personas are not just descriptive; they are powerful predictors of the specific emotional harms experienced by narrators. Radicalization perceived as a deliberate ideological choice is associated with narrator anger and disgust, while those marked by personal and cognitive collapse are linked to fear and sadness. This work provides the first empirical framework for understanding radicalization as a relational phenomenon, offering a vital roadmap for researchers and practitioners to navigate its interpersonal fallout.
Integrating Machine-Generated Short Descriptions into the Wikipedia Android App: A Pilot Deployment of Descartes
Jan 12, 2026Short descriptions are a key part of the Wikipedia user experience, but their coverage remains uneven across languages and topics. In previous work, we introduced Descartes, a multilingual model for generating short descriptions. In this report, we present the results of a pilot deployment of Descartes in the Wikipedia Android app, where editors were offered suggestions based on outputs from Descartes while editing short descriptions. The experiment spanned 12 languages, with over 3,900 articles and 375 editors participating. Overall, 90% of accepted Descartes descriptions were rated at least 3 out of 5 in quality, and their average ratings were comparable to human-written ones. Editors adopted machine suggestions both directly and with modifications, while the rate of reverts and reports remained low. The pilot also revealed practical considerations for deployment, including latency, language-specific gaps, and the need for safeguards around sensitive topics. These results indicate that Descartes's short descriptions can support editors in reducing content gaps, provided that technical, design, and community guardrails are in place.
TiME: Tiny Monolingual Encoders for Efficient NLP Pipelines
Dec 16, 2025Today, a lot of research on language models is focused on large, general-purpose models. However, many NLP pipelines only require models with a well-defined, small set of capabilities. While large models are capable of performing the tasks of those smaller models, they are simply not fast enough to process large amounts of data or offer real-time responses. Furthermore, they often use unnecessarily large amounts of energy, leading to sustainability concerns and problems when deploying them on battery-powered devices. In our work, we show how to train small models for such efficiency-critical applications. As opposed to many off-the-shelf NLP pipelines, our models use modern training techniques such as distillation, and offer support for low-resource languages. We call our models TiME (Tiny Monolingual Encoders) and comprehensively evaluate them on a range of common NLP tasks, observing an improved trade-off between benchmark performance on one hand, and throughput, latency and energy consumption on the other. Along the way, we show that distilling monolingual models from multilingual teachers is possible, and likewise distilling models with absolute positional embeddings from teachers with relative positional embeddings.
Carrot, stick, or both? Price incentives for sustainable food choice in competitive environments
Dec 15, 2025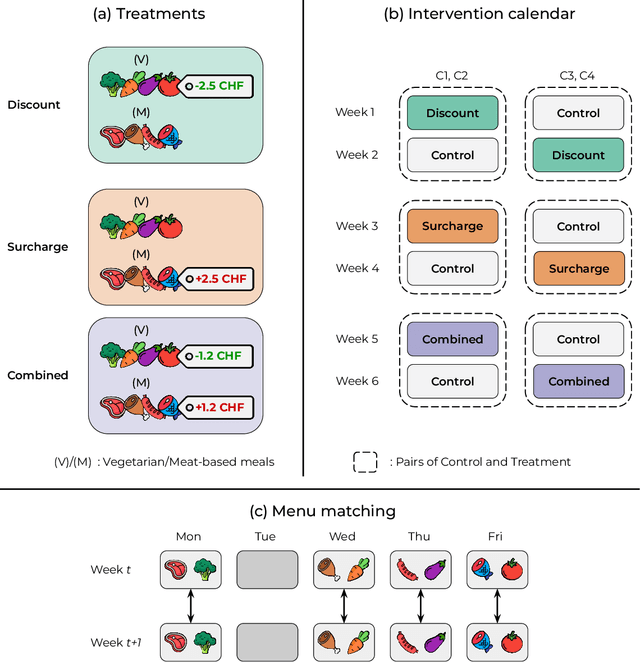
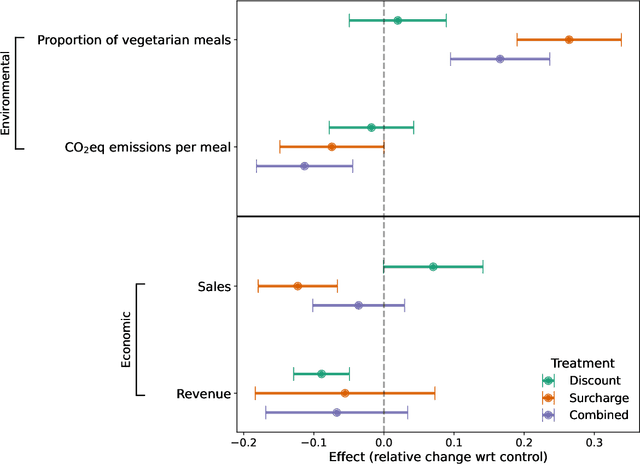
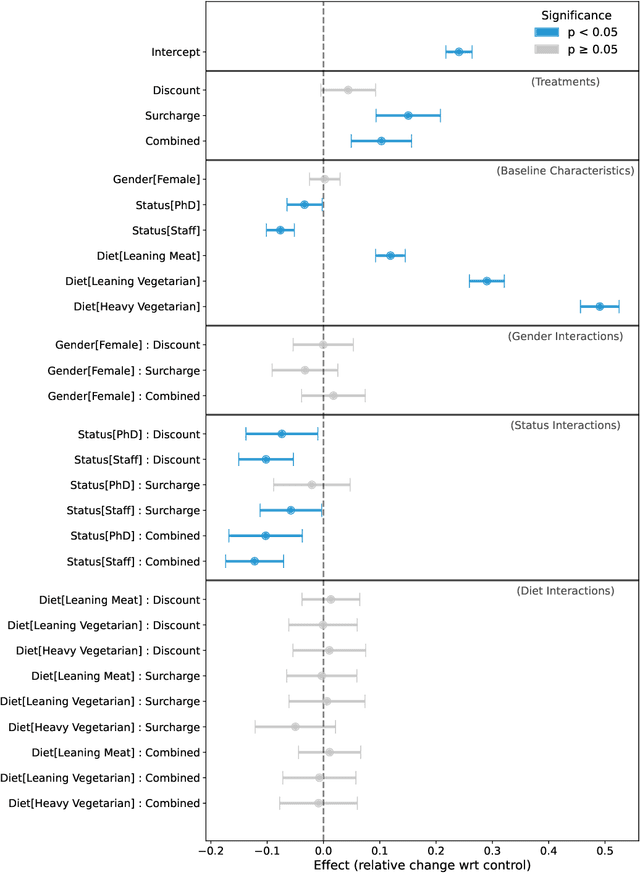
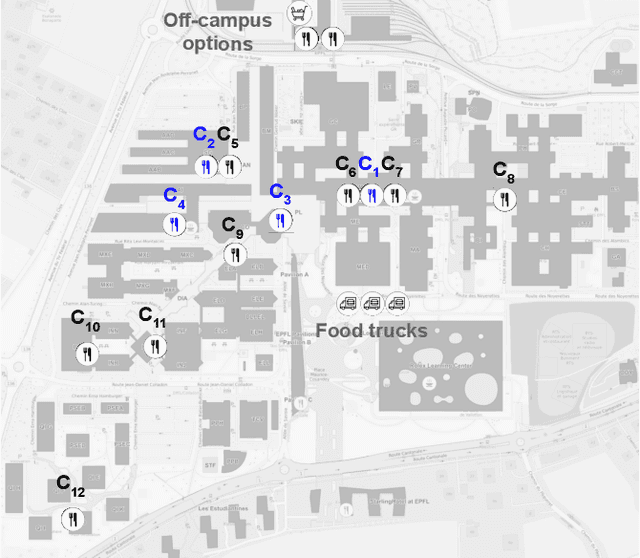
Meat consumption is a major driver of global greenhouse gas emissions. While pricing interventions have shown potential to reduce meat intake, previous studies have focused on highly constrained environments with limited consumer choice. Here, we present the first large-scale field experiment to evaluate multiple pricing interventions in a real-world, competitive setting. Using a sequential crossover design with matched menus in a Swiss university campus, we systematically compared vegetarian-meal discounts (-2.5 CHF), meat surcharges (+2.5 CHF), and a combined scheme (-1.2 CHF=+1.2 CHF) across four campus cafeterias. Only the surcharge and combined interventions led to significant increases in vegetarian meal uptake--by 26.4% and 16.6%, respectively--and reduced CO2 emissions per meal by 7.4% and 11.3%, respectively. The surcharge, while effective, triggered a 12.3% drop in sales at intervention sites and a corresponding 14.9% increase in non-treated locations, hence causing a spillover effect that completely offset environmental gains. In contrast, the combined approach achieved meaningful emission reductions without significant effects on overall sales or revenue, making it both effective and economically viable. Notably, pricing interventions were equally effective for both vegetarian-leaning customers and habitual meat-eaters, stimulating change even within entrenched dietary habits. Our results show that balanced pricing strategies can reduce the carbon footprint of realistic food environments, but require coordinated implementation to maximize climate benefits and avoid unintended spillover effects.
From Model Training to Model Raising
Nov 17, 2025
Current AI training methods align models with human values only after their core capabilities have been established, resulting in models that are easily misaligned and lack deep-rooted value systems. We propose a paradigm shift from "model training" to "model raising", in which alignment is woven into a model's development from the start. We identify several key components for this paradigm, all centered around redesigning the training corpus: reframing training data from a first-person perspective, recontextualizing information as lived experience, simulating social interactions, and scaffolding the ordering of training data. We expect that this redesign of the training corpus will lead to an early commitment to values from the first training token onward, such that knowledge, skills, and values are intrinsically much harder to separate. In an ecosystem in which large language model capabilities start overtaking human capabilities in many tasks, this seems to us like a critical need.
Cmprsr: Abstractive Token-Level Question-Agnostic Prompt Compressor
Nov 15, 2025Motivated by the high costs of using black-box Large Language Models (LLMs), we introduce a novel prompt compression paradigm, under which we use smaller LLMs to compress inputs for the larger ones. We present the first comprehensive LLM-as-a-compressor benchmark spanning 25 open- and closed-source models, which reveals significant disparity in models' compression ability in terms of (i) preserving semantically important information (ii) following the user-provided compression rate (CR). We further improve the performance of gpt-4.1-mini, the best overall vanilla compressor, with Textgrad-based compression meta-prompt optimization. We also identify the most promising open-source vanilla LLM - Qwen3-4B - and post-train it with a combination of supervised fine-tuning (SFT) and Group Relative Policy Optimization (GRPO), pursuing the dual objective of CR adherence and maximizing the downstream task performance. We call the resulting model Cmprsr and demonstrate its superiority over both extractive and vanilla abstractive compression across the entire range of compression rates on lengthy inputs from MeetingBank and LongBench as well as short prompts from GSM8k. The latter highlights Cmprsr's generalizability across varying input lengths and domains. Moreover, Cmprsr closely follows the requested compression rate, offering fine control over the cost-quality trade-off.
Interactive Evaluation of Large Language Models for Multi-Requirement Software Engineering Tasks
Aug 26, 2025Standard single-turn, static benchmarks fall short in evaluating the nuanced capabilities of Large Language Models (LLMs) on complex tasks such as software engineering. In this work, we propose a novel interactive evaluation framework that assesses LLMs on multi-requirement programming tasks through structured, feedback-driven dialogue. Each task is modeled as a requirement dependency graph, and an ``interviewer'' LLM, aware of the ground-truth solution, provides minimal, targeted hints to an ``interviewee'' model to help correct errors and fulfill target constraints. This dynamic protocol enables fine-grained diagnostic insights into model behavior, uncovering strengths and systematic weaknesses that static benchmarks fail to measure. We build on DevAI, a benchmark of 55 curated programming tasks, by adding ground-truth solutions and evaluating the relevance and utility of interviewer hints through expert annotation. Our results highlight the importance of dynamic evaluation in advancing the development of collaborative code-generating agents.
TRPrompt: Bootstrapping Query-Aware Prompt Optimization from Textual Rewards
Jul 24, 2025Prompt optimization improves the reasoning abilities of large language models (LLMs) without requiring parameter updates to the target model. Following heuristic-based "Think step by step" approaches, the field has evolved in two main directions: while one group of methods uses textual feedback to elicit improved prompts from general-purpose LLMs in a training-free way, a concurrent line of research relies on numerical rewards to train a special prompt model, tailored for providing optimal prompts to the target model. In this paper, we introduce the Textual Reward Prompt framework (TRPrompt), which unifies these approaches by directly incorporating textual feedback into training of the prompt model. Our framework does not require prior dataset collection and is being iteratively improved with the feedback on the generated prompts. When coupled with the capacity of an LLM to internalize the notion of what a "good" prompt is, the high-resolution signal provided by the textual rewards allows us to train a prompt model yielding state-of-the-art query-specific prompts for the problems from the challenging math datasets GSMHard and MATH.
Combining Constrained and Unconstrained Decoding via Boosting: BoostCD and Its Application to Information Extraction
Jun 17, 2025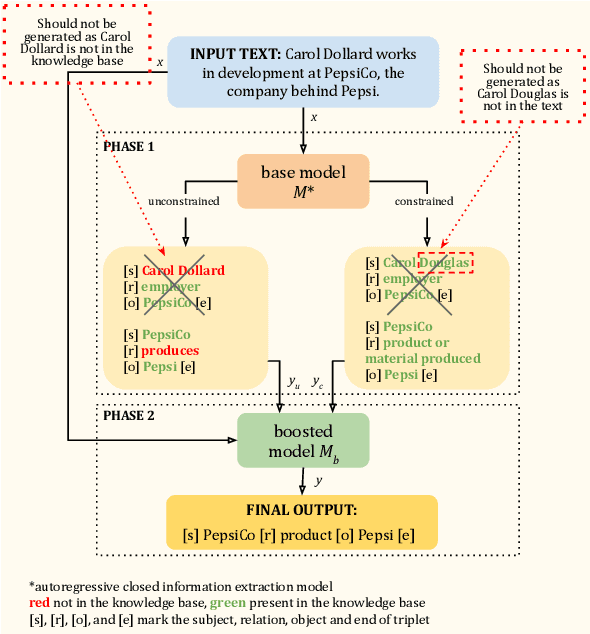
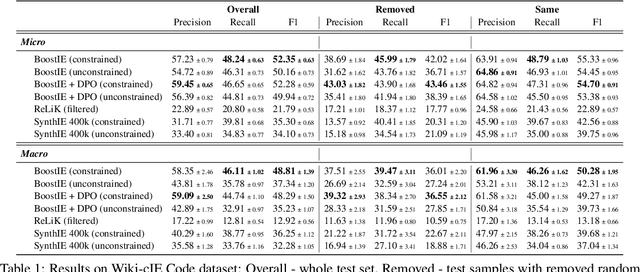
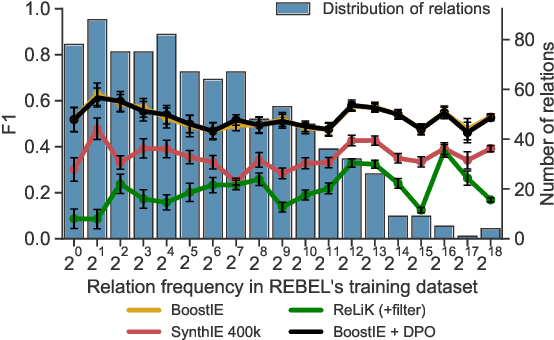
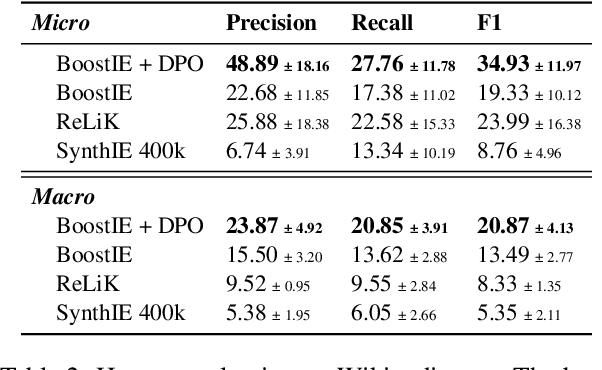
Many recent approaches to structured NLP tasks use an autoregressive language model $M$ to map unstructured input text $x$ to output text $y$ representing structured objects (such as tuples, lists, trees, code, etc.), where the desired output structure is enforced via constrained decoding. During training, these approaches do not require the model to be aware of the constraints, which are merely implicit in the training outputs $y$. This is advantageous as it allows for dynamic constraints without requiring retraining, but can lead to low-quality output during constrained decoding at test time. We overcome this problem with Boosted Constrained Decoding (BoostCD), which combines constrained and unconstrained decoding in two phases: Phase 1 decodes from the base model $M$ twice, in constrained and unconstrained mode, obtaining two weak predictions. In phase 2, a learned autoregressive boosted model combines the two weak predictions into one final prediction. The mistakes made by the base model with vs. without constraints tend to be complementary, which the boosted model learns to exploit for improved performance. We demonstrate the power of BoostCD by applying it to closed information extraction. Our model, BoostIE, outperforms prior approaches both in and out of distribution, addressing several common errors identified in those approaches.
Localized Cultural Knowledge is Conserved and Controllable in Large Language Models
Apr 14, 2025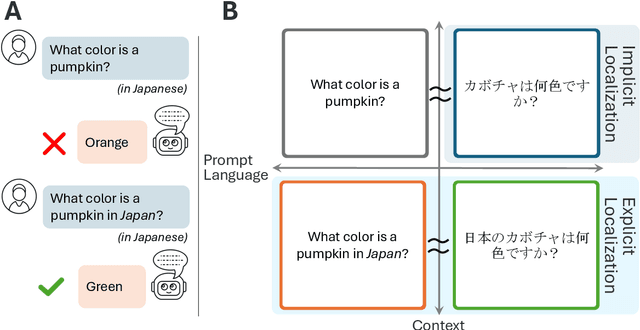

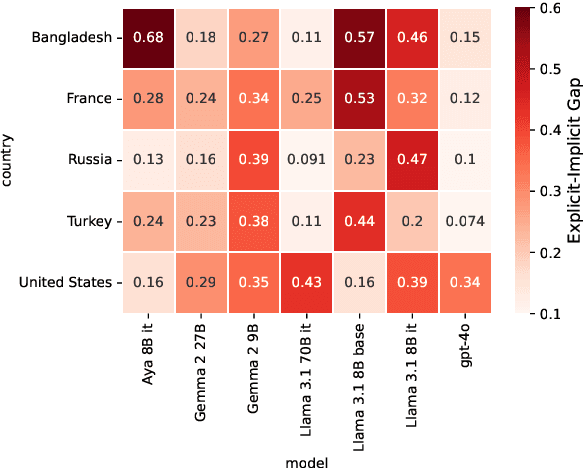
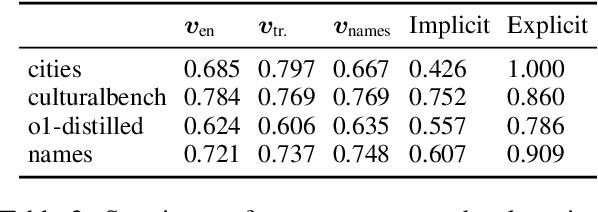
Just as humans display language patterns influenced by their native tongue when speaking new languages, LLMs often default to English-centric responses even when generating in other languages. Nevertheless, we observe that local cultural information persists within the models and can be readily activated for cultural customization. We first demonstrate that explicitly providing cultural context in prompts significantly improves the models' ability to generate culturally localized responses. We term the disparity in model performance with versus without explicit cultural context the explicit-implicit localization gap, indicating that while cultural knowledge exists within LLMs, it may not naturally surface in multilingual interactions if cultural context is not explicitly provided. Despite the explicit prompting benefit, however, the answers reduce in diversity and tend toward stereotypes. Second, we identify an explicit cultural customization vector, conserved across all non-English languages we explore, which enables LLMs to be steered from the synthetic English cultural world-model toward each non-English cultural world. Steered responses retain the diversity of implicit prompting and reduce stereotypes to dramatically improve the potential for customization. We discuss the implications of explicit cultural customization for understanding the conservation of alternative cultural world models within LLMs, and their controllable utility for translation, cultural customization, and the possibility of making the explicit implicit through soft control for expanded LLM function and appeal.