 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMagentic-UI: Towards Human-in-the-loop Agentic Systems
Jul 30, 2025AI agents powered by large language models are increasingly capable of autonomously completing complex, multi-step tasks using external tools. Yet, they still fall short of human-level performance in most domains including computer use, software development, and research. Their growing autonomy and ability to interact with the outside world, also introduces safety and security risks including potentially misaligned actions and adversarial manipulation. We argue that human-in-the-loop agentic systems offer a promising path forward, combining human oversight and control with AI efficiency to unlock productivity from imperfect systems. We introduce Magentic-UI, an open-source web interface for developing and studying human-agent interaction. Built on a flexible multi-agent architecture, Magentic-UI supports web browsing, code execution, and file manipulation, and can be extended with diverse tools via Model Context Protocol (MCP). Moreover, Magentic-UI presents six interaction mechanisms for enabling effective, low-cost human involvement: co-planning, co-tasking, multi-tasking, action guards, and long-term memory. We evaluate Magentic-UI across four dimensions: autonomous task completion on agentic benchmarks, simulated user testing of its interaction capabilities, qualitative studies with real users, and targeted safety assessments. Our findings highlight Magentic-UI's potential to advance safe and efficient human-agent collaboration.
Navigating Rifts in Human-LLM Grounding: Study and Benchmark
Mar 18, 2025Language models excel at following instructions but often struggle with the collaborative aspects of conversation that humans naturally employ. This limitation in grounding -- the process by which conversation participants establish mutual understanding -- can lead to outcomes ranging from frustrated users to serious consequences in high-stakes scenarios. To systematically study grounding challenges in human-LLM interactions, we analyze logs from three human-assistant datasets: WildChat, MultiWOZ, and Bing Chat. We develop a taxonomy of grounding acts and build models to annotate and forecast grounding behavior. Our findings reveal significant differences in human-human and human-LLM grounding: LLMs were three times less likely to initiate clarification and sixteen times less likely to provide follow-up requests than humans. Additionally, early grounding failures predicted later interaction breakdowns. Building on these insights, we introduce RIFTS: a benchmark derived from publicly available LLM interaction data containing situations where LLMs fail to initiate grounding. We note that current frontier models perform poorly on RIFTS, highlighting the need to reconsider how we train and prompt LLMs for human interaction. To this end, we develop a preliminary intervention that mitigates grounding failures.
Interactive Debugging and Steering of Multi-Agent AI Systems
Mar 03, 2025Fully autonomous teams of LLM-powered AI agents are emerging that collaborate to perform complex tasks for users. What challenges do developers face when trying to build and debug these AI agent teams? In formative interviews with five AI agent developers, we identify core challenges: difficulty reviewing long agent conversations to localize errors, lack of support in current tools for interactive debugging, and the need for tool support to iterate on agent configuration. Based on these needs, we developed an interactive multi-agent debugging tool, AGDebugger, with a UI for browsing and sending messages, the ability to edit and reset prior agent messages, and an overview visualization for navigating complex message histories. In a two-part user study with 14 participants, we identify common user strategies for steering agents and highlight the importance of interactive message resets for debugging. Our studies deepen understanding of interfaces for debugging increasingly important agentic workflows.
Measuring AI agent autonomy: Towards a scalable approach with code inspection
Feb 21, 2025AI agents are AI systems that can achieve complex goals autonomously. Assessing the level of agent autonomy is crucial for understanding both their potential benefits and risks. Current assessments of autonomy often focus on specific risks and rely on run-time evaluations -- observations of agent actions during operation. We introduce a code-based assessment of autonomy that eliminates the need to run an AI agent to perform specific tasks, thereby reducing the costs and risks associated with run-time evaluations. Using this code-based framework, the orchestration code used to run an AI agent can be scored according to a taxonomy that assesses attributes of autonomy: impact and oversight. We demonstrate this approach with the AutoGen framework and select applications.
Magentic-One: A Generalist Multi-Agent System for Solving Complex Tasks
Nov 07, 2024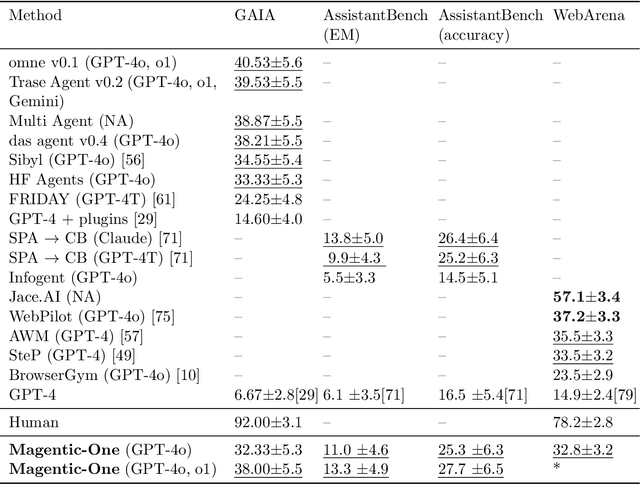
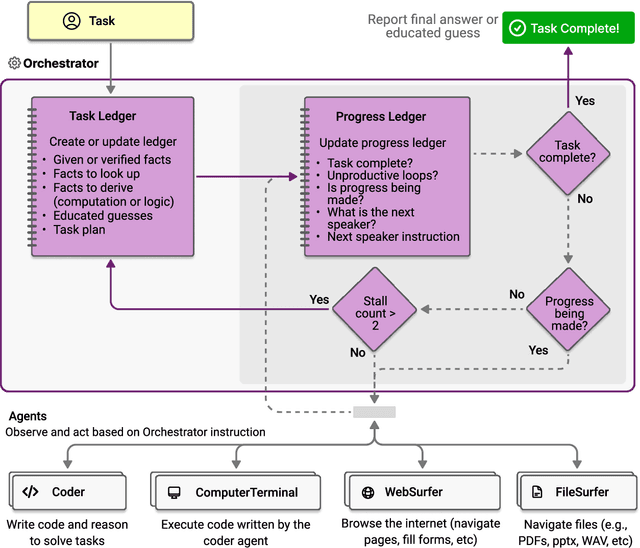
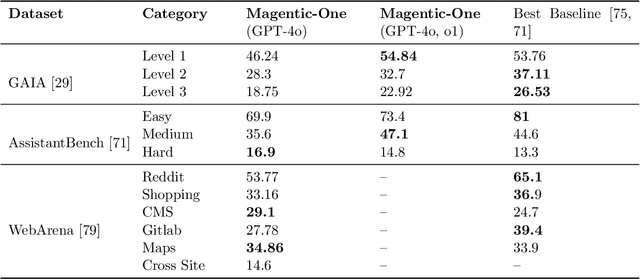
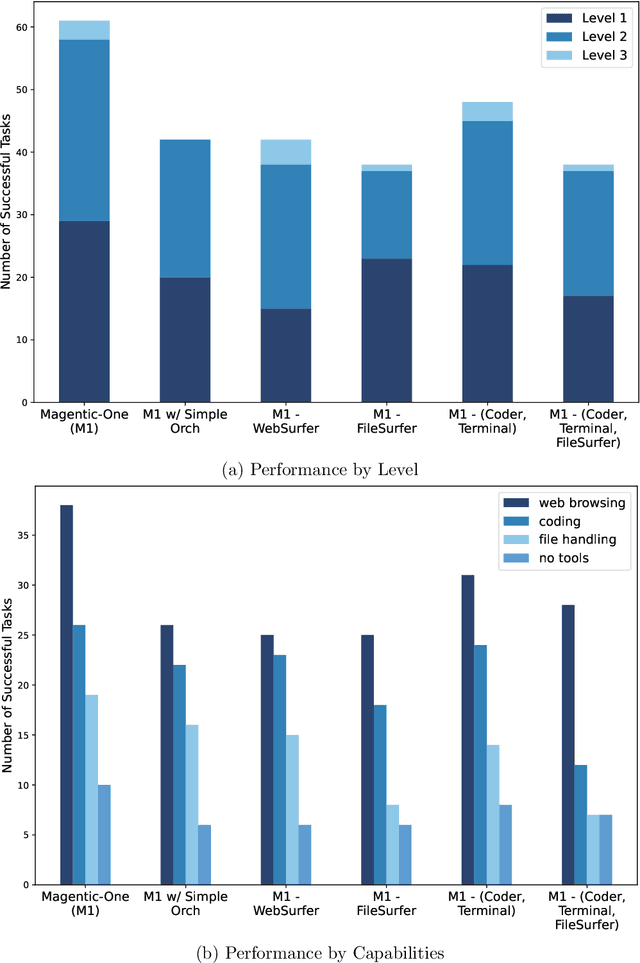
Modern AI agents, driven by advances in large foundation models, promise to enhance our productivity and transform our lives by augmenting our knowledge and capabilities. To achieve this vision, AI agents must effectively plan, perform multi-step reasoning and actions, respond to novel observations, and recover from errors, to successfully complete complex tasks across a wide range of scenarios. In this work, we introduce Magentic-One, a high-performing open-source agentic system for solving such tasks. Magentic-One uses a multi-agent architecture where a lead agent, the Orchestrator, plans, tracks progress, and re-plans to recover from errors. Throughout task execution, the Orchestrator directs other specialized agents to perform tasks as needed, such as operating a web browser, navigating local files, or writing and executing Python code. We show that Magentic-One achieves statistically competitive performance to the state-of-the-art on three diverse and challenging agentic benchmarks: GAIA, AssistantBench, and WebArena. Magentic-One achieves these results without modification to core agent capabilities or to how they collaborate, demonstrating progress towards generalist agentic systems. Moreover, Magentic-One's modular design allows agents to be added or removed from the team without additional prompt tuning or training, easing development and making it extensible to future scenarios. We provide an open-source implementation of Magentic-One, and we include AutoGenBench, a standalone tool for agentic evaluation. AutoGenBench provides built-in controls for repetition and isolation to run agentic benchmarks in a rigorous and contained manner -- which is important when agents' actions have side-effects. Magentic-One, AutoGenBench and detailed empirical performance evaluations of Magentic-One, including ablations and error analysis are available at https://aka.ms/magentic-one
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation Framework
Aug 16, 2023This technical report presents AutoGen, a new framework that enables development of LLM applications using multiple agents that can converse with each other to solve tasks. AutoGen agents are customizable, conversable, and seamlessly allow human participation. They can operate in various modes that employ combinations of LLMs, human inputs, and tools. AutoGen's design offers multiple advantages: a) it gracefully navigates the strong but imperfect generation and reasoning abilities of these LLMs; b) it leverages human understanding and intelligence, while providing valuable automation through conversations between agents; c) it simplifies and unifies the implementation of complex LLM workflows as automated agent chats. We provide many diverse examples of how developers can easily use AutoGen to effectively solve tasks or build applications, ranging from coding, mathematics, operations research, entertainment, online decision-making, question answering, etc.
When to Show a Suggestion? Integrating Human Feedback in AI-Assisted Programming
Jun 08, 2023AI powered code-recommendation systems, such as Copilot and CodeWhisperer, provide code suggestions inside a programmer's environment (e.g., an IDE) with the aim to improve their productivity. Since, in these scenarios, programmers accept and reject suggestions, ideally, such a system should use this feedback in furtherance of this goal. In this work we leverage prior data of programmers interacting with Copilot to develop interventions that can save programmer time. We propose a utility theory framework, which models this interaction with programmers and decides when and which suggestions to display. Our framework Conditional suggestion Display from Human Feedback (CDHF) is based on predictive models of programmer actions. Using data from 535 programmers we build models that predict the likelihood of suggestion acceptance. In a retrospective evaluation on real-world programming tasks solved with AI-assisted programming, we find that CDHF can achieve favorable tradeoffs. Our findings show the promise of integrating human feedback to improve interaction with large language models in scenarios such as programming and possibly writing tasks.
Generation Probabilities Are Not Enough: Exploring the Effectiveness of Uncertainty Highlighting in AI-Powered Code Completions
Feb 14, 2023



Large-scale generative models enabled the development of AI-powered code completion tools to assist programmers in writing code. However, much like other AI-powered tools, AI-powered code completions are not always accurate, potentially introducing bugs or even security vulnerabilities into code if not properly detected and corrected by a human programmer. One technique that has been proposed and implemented to help programmers identify potential errors is to highlight uncertain tokens. However, there have been no empirical studies exploring the effectiveness of this technique-- nor investigating the different and not-yet-agreed-upon notions of uncertainty in the context of generative models. We explore the question of whether conveying information about uncertainty enables programmers to more quickly and accurately produce code when collaborating with an AI-powered code completion tool, and if so, what measure of uncertainty best fits programmers' needs. Through a mixed-methods study with 30 programmers, we compare three conditions: providing the AI system's code completion alone, highlighting tokens with the lowest likelihood of being generated by the underlying generative model, and highlighting tokens with the highest predicted likelihood of being edited by a programmer. We find that highlighting tokens with the highest predicted likelihood of being edited leads to faster task completion and more targeted edits, and is subjectively preferred by study participants. In contrast, highlighting tokens according to their probability of being generated does not provide any benefit over the baseline with no highlighting. We further explore the design space of how to convey uncertainty in AI-powered code completion tools, and find that programmers prefer highlights that are granular, informative, interpretable, and not overwhelming.
Understanding the Role of Human Intuition on Reliance in Human-AI Decision-Making with Explanations
Jan 18, 2023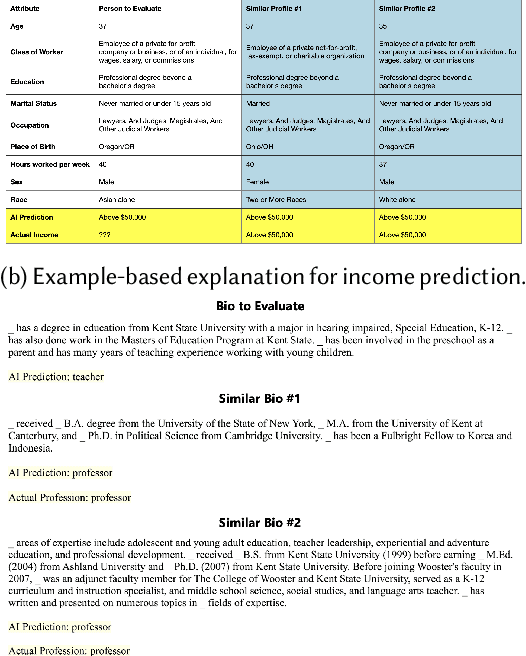
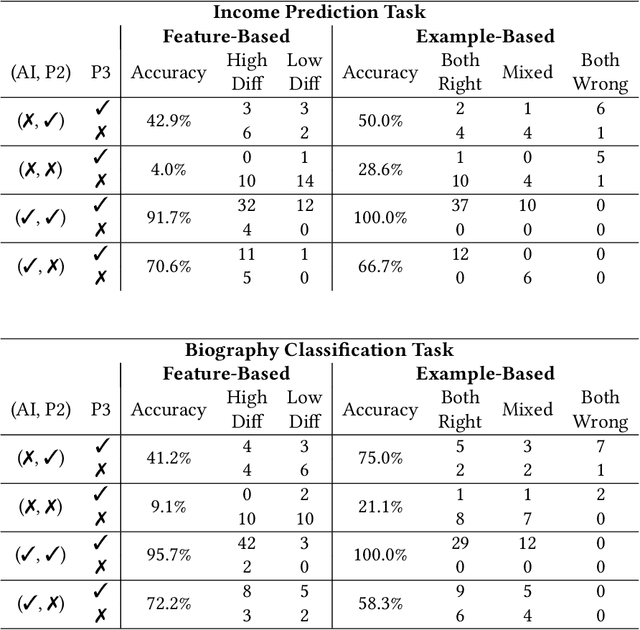
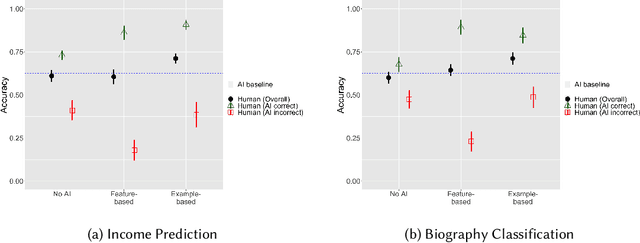
AI explanations are often mentioned as a way to improve human-AI decision-making. Yet, empirical studies have not found consistent evidence of explanations' effectiveness and, on the contrary, suggest that they can increase overreliance when the AI system is wrong. While many factors may affect reliance on AI support, one important factor is how decision-makers reconcile their own intuition -- which may be based on domain knowledge, prior task experience, or pattern recognition -- with the information provided by the AI system to determine when to override AI predictions. We conduct a think-aloud, mixed-methods study with two explanation types (feature- and example-based) for two prediction tasks to explore how decision-makers' intuition affects their use of AI predictions and explanations, and ultimately their choice of when to rely on AI. Our results identify three types of intuition involved in reasoning about AI predictions and explanations: intuition about the task outcome, features, and AI limitations. Building on these, we summarize three observed pathways for decision-makers to apply their own intuition and override AI predictions. We use these pathways to explain why (1) the feature-based explanations we used did not improve participants' decision outcomes and increased their overreliance on AI, and (2) the example-based explanations we used improved decision-makers' performance over feature-based explanations and helped achieve complementary human-AI performance. Overall, our work identifies directions for further development of AI decision-support systems and explanation methods that help decision-makers effectively apply their intuition to achieve appropriate reliance on AI.
Aligning Offline Metrics and Human Judgments of Value of AI-Pair Programmers
Oct 29, 2022Large language models trained on massive amounts of natural language data and code have shown impressive capabilities in automatic code generation scenarios. Development and evaluation of these models has largely been driven by offline functional correctness metrics, which consider a task to be solved if the generated code passes corresponding unit tests. While functional correctness is clearly an important property of a code generation model, we argue that it may not fully capture what programmers value when collaborating with their AI pair programmers. For example, while a nearly correct suggestion that does not consider edge cases may fail a unit test, it may still provide a substantial starting point or hint to the programmer, thereby reducing total needed effort to complete a coding task. To investigate this, we conduct a user study with (N=49) experienced programmers, and find that while both correctness and effort correlate with value, the association is strongest for effort. We argue that effort should be considered as an important dimension of evaluation in code generation scenarios. We also find that functional correctness remains better at identifying the highest-value generations; but participants still saw considerable value in code that failed unit tests. Conversely, similarity-based metrics are very good at identifying the lowest-value generations among those that fail unit tests. Based on these findings, we propose a simple hybrid metric, which combines functional correctness and similarity-based metrics to capture different dimensions of what programmers might value and show that this hybrid metric more strongly correlates with both value and effort. Our findings emphasize the importance of designing human-centered metrics that capture what programmers need from and value in their AI pair programmers.