 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTo CoT or To Loop? A Formal Comparison Between Chain-of-Thought and Looped Transformers
May 25, 2025


Chain-of-Thought (CoT) and Looped Transformers have been shown to empirically improve performance on reasoning tasks and to theoretically enhance expressivity by recursively increasing the number of computational steps. However, their comparative capabilities are still not well understood. In this paper, we provide a formal analysis of their respective strengths and limitations. We show that Looped Transformers can efficiently simulate parallel computations for deterministic tasks, which we formalize as evaluation over directed acyclic graphs. In contrast, CoT with stochastic decoding excels at approximate inference for compositional structures, namely self-reducible problems. These separations suggest the tasks for which depth-driven recursion is more suitable, thereby offering practical cues for choosing between reasoning paradigms.
Measuring AI agent autonomy: Towards a scalable approach with code inspection
Feb 21, 2025AI agents are AI systems that can achieve complex goals autonomously. Assessing the level of agent autonomy is crucial for understanding both their potential benefits and risks. Current assessments of autonomy often focus on specific risks and rely on run-time evaluations -- observations of agent actions during operation. We introduce a code-based assessment of autonomy that eliminates the need to run an AI agent to perform specific tasks, thereby reducing the costs and risks associated with run-time evaluations. Using this code-based framework, the orchestration code used to run an AI agent can be scored according to a taxonomy that assesses attributes of autonomy: impact and oversight. We demonstrate this approach with the AutoGen framework and select applications.
Revisiting Absence withSymptoms that *T* Show up Decades Later to Recover Empty Categories
Dec 02, 2024
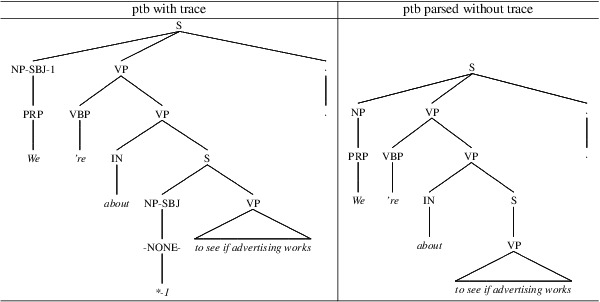
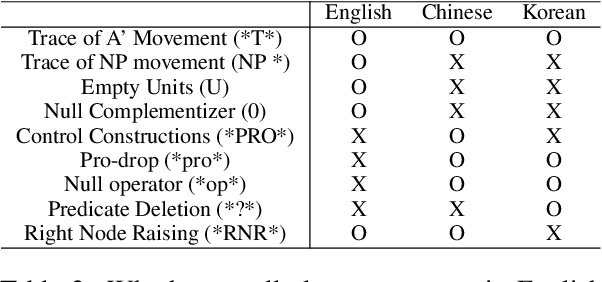
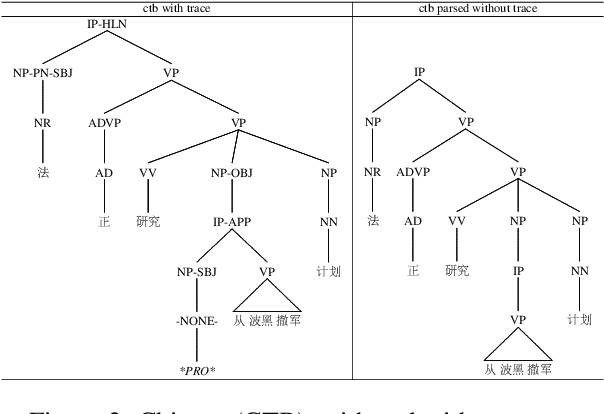
This paper explores null elements in English, Chinese, and Korean Penn treebanks. Null elements contain important syntactic and semantic information, yet they have typically been treated as entities to be removed during language processing tasks, particularly in constituency parsing. Thus, we work towards the removal and, in particular, the restoration of null elements in parse trees. We focus on expanding a rule-based approach utilizing linguistic context information to Chinese, as rule based approaches have historically only been applied to English. We also worked to conduct neural experiments with a language agnostic sequence-to-sequence model to recover null elements for English (PTB), Chinese (CTB) and Korean (KTB). To the best of the authors' knowledge, null elements in three different languages have been explored and compared for the first time. In expanding a rule based approach to Chinese, we achieved an overall F1 score of 80.00, which is comparable to past results in the CTB. In our neural experiments we achieved F1 scores up to 90.94, 85.38 and 88.79 for English, Chinese, and Korean respectively with functional labels.
Improving Performance of Commercially Available AI Products in a Multi-Agent Configuration
Oct 29, 2024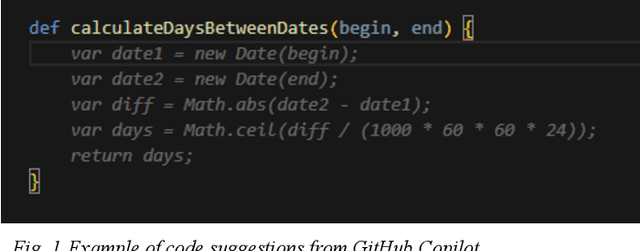
In recent years, with the rapid advancement of large language models (LLMs), multi-agent systems have become increasingly more capable of practical application. At the same time, the software development industry has had a number of new AI-powered tools developed that improve the software development lifecycle (SDLC). Academically, much attention has been paid to the role of multi-agent systems to the SDLC. And, while single-agent systems have frequently been examined in real-world applications, we have seen comparatively few real-world examples of publicly available commercial tools working together in a multi-agent system with measurable improvements. In this experiment we test context sharing between Crowdbotics PRD AI, a tool for generating software requirements using AI, and GitHub Copilot, an AI pair-programming tool. By sharing business requirements from PRD AI, we improve the code suggestion capabilities of GitHub Copilot by 13.8% and developer task success rate by 24.5% -- demonstrating a real-world example of commercially-available AI systems working together with improved outcomes.
On Expressive Power of Looped Transformers: Theoretical Analysis and Enhancement via Timestep Encoding
Oct 02, 2024



Looped Transformers offer advantages in parameter efficiency and Turing completeness. However, their expressive power for function approximation and approximation rate remains underexplored. In this paper, we establish approximation rates of Looped Transformers by defining the concept of the modulus of continuity for sequence-to-sequence functions. This reveals a limitation specific to the looped architecture. That is, the analysis prompts us to incorporate scaling parameters for each loop, conditioned on timestep encoding. Experimental results demonstrate that increasing the number of loops enhances performance, with further gains achieved through the timestep encoding architecture.
Tur[k]ingBench: A Challenge Benchmark for Web Agents
Mar 21, 2024Recent chatbots have demonstrated impressive ability to understand and communicate in raw-text form. However, there is more to the world than raw text. For example, humans spend long hours of their time on web pages, where text is intertwined with other modalities and tasks are accomplished in the form of various complex interactions. Can state-of-the-art multi-modal models generalize to such complex domains? To address this question, we introduce TurkingBench, a benchmark of tasks formulated as web pages containing textual instructions with multi-modal context. Unlike existing work which employs artificially synthesized web pages, here we use natural HTML pages that were originally designed for crowdsourcing workers for various annotation purposes. The HTML instructions of each task are also instantiated with various values (obtained from the crowdsourcing tasks) to form new instances of the task. This benchmark contains 32.2K instances distributed across 158 tasks. Additionally, to facilitate the evaluation on TurkingBench, we develop an evaluation framework that connects the responses of chatbots to modifications on web pages (modifying a text box, checking a radio, etc.). We evaluate the performance of state-of-the-art models, including language-only, vision-only, and layout-only models, and their combinations, on this benchmark. Our findings reveal that these models perform significantly better than random chance, yet considerable room exists for improvement. We hope this benchmark will help facilitate the evaluation and development of web-based agents.
Open Data on GitHub: Unlocking the Potential of AI
Jun 09, 2023



GitHub is the world's largest platform for collaborative software development, with over 100 million users. GitHub is also used extensively for open data collaboration, hosting more than 800 million open data files, totaling 142 terabytes of data. This study highlights the potential of open data on GitHub and demonstrates how it can accelerate AI research. We analyze the existing landscape of open data on GitHub and the patterns of how users share datasets. Our findings show that GitHub is one of the largest hosts of open data in the world and has experienced an accelerated growth of open data assets over the past four years. By examining the open data landscape on GitHub, we aim to empower users and organizations to leverage existing open datasets and improve their discoverability -- ultimately contributing to the ongoing AI revolution to help address complex societal issues. We release the three datasets that we have collected to support this analysis as open datasets at https://github.com/github/open-data-on-github.
THC: Accelerating Distributed Deep Learning Using Tensor Homomorphic Compression
Feb 16, 2023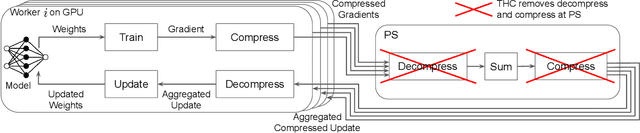

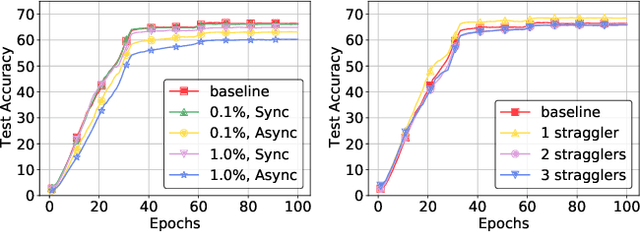
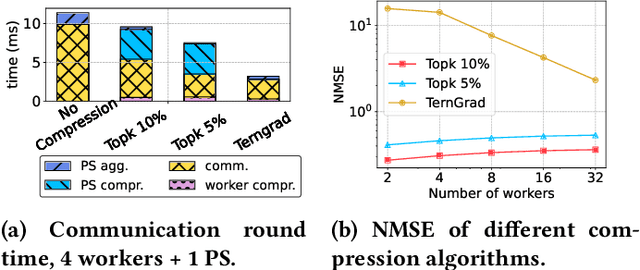
Deep neural networks (DNNs) are the de-facto standard for essential use cases, such as image classification, computer vision, and natural language processing. As DNNs and datasets get larger, they require distributed training on increasingly larger clusters. A main bottleneck is then the resulting communication overhead where workers exchange model updates (i.e., gradients) on a per-round basis. To address this bottleneck and accelerate training, a widely-deployed approach is compression. However, previous deployments often apply bi-directional compression schemes by simply using a uni-directional gradient compression scheme in each direction. This results in significant computational overheads at the parameter server and increased compression error, leading to longer training and lower accuracy. We introduce Tensor Homomorphic Compression (THC), a novel bi-directional compression framework that enables the direct aggregation of compressed values while optimizing the bandwidth to accuracy tradeoff, thus eliminating the aforementioned overheads. Moreover, THC is compatible with in-network aggregation (INA), which allows for further acceleration. Evaluation over a testbed shows that THC improves time-to-accuracy in comparison to alternatives by up to 1.32x with a software PS and up to 1.51x using INA. Finally, we demonstrate that THC is scalable and tolerant for acceptable packet-loss rates.
Predicting housing prices and analyzing real estate market in the Chicago suburbs using Machine Learning
Oct 12, 2022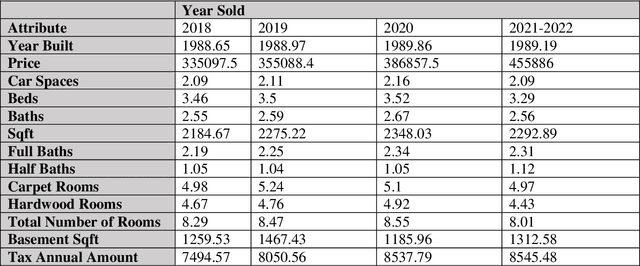
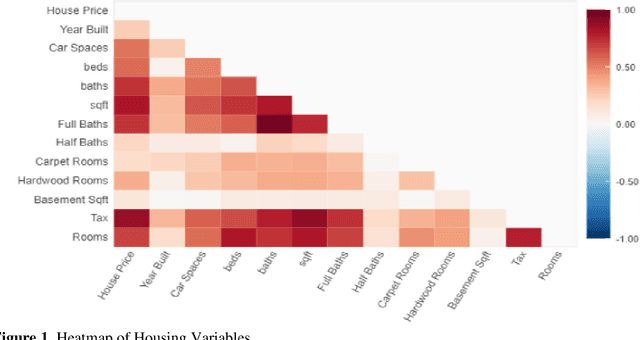
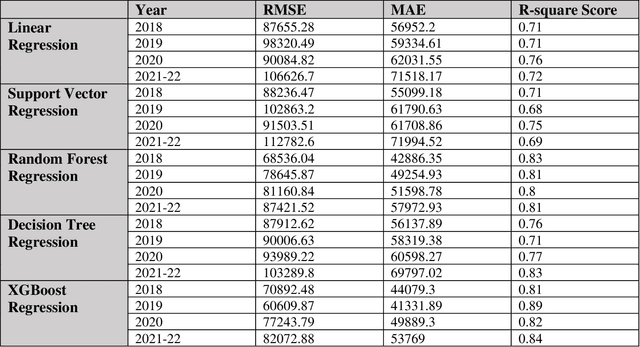
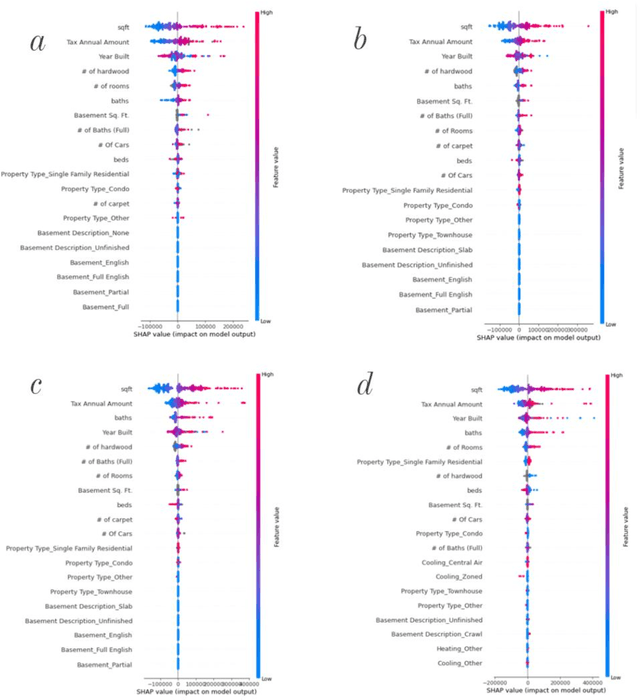
The pricing of housing properties is determined by a variety of factors. However, post-pandemic markets have experienced volatility in the Chicago suburb area, which have affected house prices greatly. In this study, analysis was done on the Naperville/Bolingbrook real estate market to predict property prices based on these housing attributes through machine learning models, and to evaluate the effectiveness of such models in a volatile market space. Gathering data from Redfin, a real estate website, sales data from 2018 up until the summer season of 2022 were collected for research. By analyzing these sales in this range of time, we can also look at the state of the housing market and identify trends in price. For modeling the data, the models used were linear regression, support vector regression, decision tree regression, random forest regression, and XGBoost regression. To analyze results, comparison was made on the MAE, RMSE, and R-squared values for each model. It was found that the XGBoost model performs the best in predicting house prices despite the additional volatility sponsored by post-pandemic conditions. After modeling, Shapley Values (SHAP) were used to evaluate the weights of the variables in constructing models.