 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiview Scene Graph
Oct 15, 2024



A proper scene representation is central to the pursuit of spatial intelligence where agents can robustly reconstruct and efficiently understand 3D scenes. A scene representation is either metric, such as landmark maps in 3D reconstruction, 3D bounding boxes in object detection, or voxel grids in occupancy prediction, or topological, such as pose graphs with loop closures in SLAM or visibility graphs in SfM. In this work, we propose to build Multiview Scene Graphs (MSG) from unposed images, representing a scene topologically with interconnected place and object nodes. The task of building MSG is challenging for existing representation learning methods since it needs to jointly address both visual place recognition, object detection, and object association from images with limited fields of view and potentially large viewpoint changes. To evaluate any method tackling this task, we developed an MSG dataset and annotation based on a public 3D dataset. We also propose an evaluation metric based on the intersection-over-union score of MSG edges. Moreover, we develop a novel baseline method built on mainstream pretrained vision models, combining visual place recognition and object association into one Transformer decoder architecture. Experiments demonstrate our method has superior performance compared to existing relevant baselines.
THC: Accelerating Distributed Deep Learning Using Tensor Homomorphic Compression
Feb 16, 2023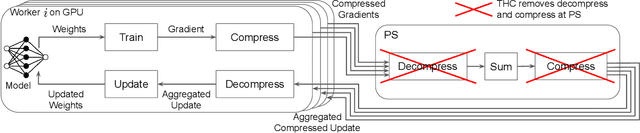

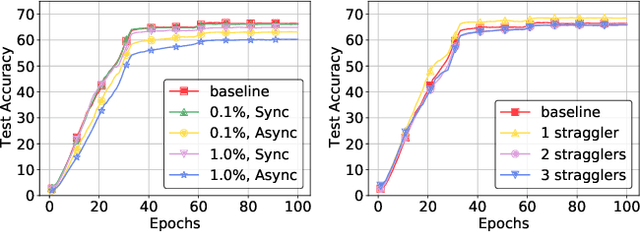
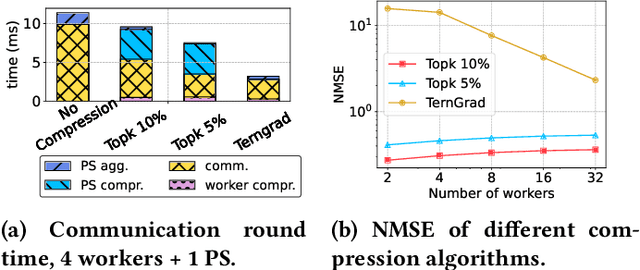
Deep neural networks (DNNs) are the de-facto standard for essential use cases, such as image classification, computer vision, and natural language processing. As DNNs and datasets get larger, they require distributed training on increasingly larger clusters. A main bottleneck is then the resulting communication overhead where workers exchange model updates (i.e., gradients) on a per-round basis. To address this bottleneck and accelerate training, a widely-deployed approach is compression. However, previous deployments often apply bi-directional compression schemes by simply using a uni-directional gradient compression scheme in each direction. This results in significant computational overheads at the parameter server and increased compression error, leading to longer training and lower accuracy. We introduce Tensor Homomorphic Compression (THC), a novel bi-directional compression framework that enables the direct aggregation of compressed values while optimizing the bandwidth to accuracy tradeoff, thus eliminating the aforementioned overheads. Moreover, THC is compatible with in-network aggregation (INA), which allows for further acceleration. Evaluation over a testbed shows that THC improves time-to-accuracy in comparison to alternatives by up to 1.32x with a software PS and up to 1.51x using INA. Finally, we demonstrate that THC is scalable and tolerant for acceptable packet-loss rates.
Mask Conditional Synthetic Satellite Imagery
Feb 08, 2023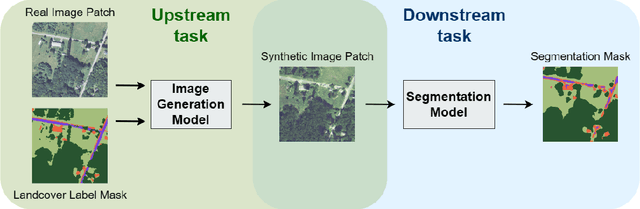
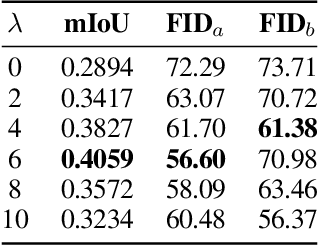


In this paper we propose a mask-conditional synthetic image generation model for creating synthetic satellite imagery datasets. Given a dataset of real high-resolution images and accompanying land cover masks, we show that it is possible to train an upstream conditional synthetic imagery generator, use that generator to create synthetic imagery with the land cover masks, then train a downstream model on the synthetic imagery and land cover masks that achieves similar test performance to a model that was trained with the real imagery. Further, we find that incorporating a mixture of real and synthetic imagery acts as a data augmentation method, producing better models than using only real imagery (0.5834 vs. 0.5235 mIoU). Finally, we find that encouraging diversity of outputs in the upstream model is a necessary component for improved downstream task performance. We have released code for reproducing our work on GitHub, see https://github.com/ms-synthetic-satellite-image/synthetic-satellite-imagery .