 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrla: A Library for Serving LLM-Based Multi-Agent Systems
Mar 13, 2026We introduce Orla, a library for constructing and running LLM-based agentic systems. Modern agentic applications consist of workflows that combine multiple LLM inference steps, tool calls, and heterogeneous infrastructure. Today, developers typically build these systems by manually composing orchestration code with LLM serving engines and tool execution logic. Orla provides a general abstraction that separates request execution from workflow-level policy. It acts as a serving layer above existing LLM inference engines: developers define workflows composed of stages, while Orla manages how those stages are mapped, executed, and coordinated across models and backends. It provides agent-level control through three mechanisms: a stage mapper, which assigns each stage to an appropriate model and backend; a workflow orchestrator, which schedules stages and manages their resources and context; and a memory manager, which manages inference state such as the KV cache across workflow boundaries. We demonstrate Orla with a customer support workflow that exercises many of its capabilities. We evaluate Orla on two datasets, showing that stage mapping improves latency and cost compared to a single-model vLLM baseline, while workflow-level cache management reduces time-to-first-token.
Confucius Code Agent: Scalable Agent Scaffolding for Real-World Codebases
Dec 20, 2025Real-world software engineering tasks require coding agents that can operate over massive repositories, sustain long-horizon sessions, and reliably coordinate complex toolchains at test time. Existing research-grade coding agents offer transparency but struggle when scaled to heavier, production-level workloads, while production-grade systems achieve strong practical performance but provide limited extensibility, interpretability, and controllability. We introduce the Confucius Code Agent (CCA), a software engineering agent that can operate at large-scale codebases. CCA is built on top of the Confucius SDK, an agent development platform structured around three complementary perspectives: Agent Experience (AX), User Experience (UX), and Developer Experience (DX). The SDK integrates a unified orchestrator with hierarchical working memory for long-context reasoning, a persistent note-taking system for cross-session continual learning, and a modular extension system for reliable tool use. In addition, we introduce a meta-agent that automates the synthesis, evaluation, and refinement of agent configurations through a build-test-improve loop, enabling rapid adaptation to new tasks, environments, and tool stacks. Instantiated with these mechanisms, CCA demonstrates strong performance on real-world software engineering tasks. On SWE-Bench-Pro, CCA reaches a Resolve@1 of 54.3%, exceeding prior research baselines and comparing favorably to commercial results, under identical repositories, model backends, and tool access.
Towards Easy and Realistic Network Infrastructure Testing for Large-scale Machine Learning
Apr 29, 2025


This paper lays the foundation for Genie, a testing framework that captures the impact of real hardware network behavior on ML workload performance, without requiring expensive GPUs. Genie uses CPU-initiated traffic over a hardware testbed to emulate GPU to GPU communication, and adapts the ASTRA-sim simulator to model interaction between the network and the ML workload.
HACK: Homomorphic Acceleration via Compression of the Key-Value Cache for Disaggregated LLM Inference
Feb 05, 2025

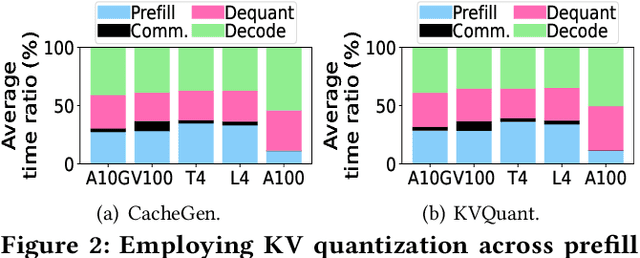

Disaggregated Large Language Model (LLM) inference has gained popularity as it separates the computation-intensive prefill stage from the memory-intensive decode stage, avoiding the prefill-decode interference and improving resource utilization. However, transmitting Key-Value (KV) data between the two stages can be a bottleneck, especially for long prompts. Additionally, the computation time overhead for prefill and decode is key for optimizing Job Completion Time (JCT), and KV data size can become prohibitive for long prompts and sequences. Existing KV quantization methods can alleviate the transmission bottleneck and reduce memory requirements, but they introduce significant dequantization overhead, exacerbating the computation time. We propose Homomorphic Acceleration via Compression of the KV cache (HACK) for disaggregated LLM inference. HACK eliminates the heavy KV dequantization step, and directly performs computations on quantized KV data to approximate and reduce the cost of the expensive matrix-multiplication step. Extensive trace-driven experiments show that HACK reduces JCT by up to 70.9% compared to disaggregated LLM inference baseline and by up to 52.3% compared to state-of-the-art KV quantization methods.
NetFlowGen: Leveraging Generative Pre-training for Network Traffic Dynamics
Dec 30, 2024Understanding the traffic dynamics in networks is a core capability for automated systems to monitor and analyze networking behaviors, reducing expensive human efforts and economic risks through tasks such as traffic classification, congestion prediction, and attack detection. However, it is still challenging to accurately model network traffic with machine learning approaches in an efficient and broadly applicable manner. Task-specific models trained from scratch are used for different networking applications, which limits the efficiency of model development and generalization of model deployment. Furthermore, while networking data is abundant, high-quality task-specific labels are often insufficient for training individual models. Large-scale self-supervised learning on unlabeled data provides a natural pathway for tackling these challenges. We propose to pre-train a general-purpose machine learning model to capture traffic dynamics with only traffic data from NetFlow records, with the goal of fine-tuning for different downstream tasks with small amount of labels. Our presented NetFlowGen framework goes beyond a proof-of-concept for network traffic pre-training and addresses specific challenges such as unifying network feature representations, learning from large unlabeled traffic data volume, and testing on real downstream tasks in DDoS attack detection. Experiments demonstrate promising results of our pre-training framework on capturing traffic dynamics and adapting to different networking tasks.
TrainMover: Efficient ML Training Live Migration with No Memory Overhead
Dec 17, 2024



Machine learning training has emerged as one of the most prominent workloads in modern data centers. These training jobs are large-scale, long-lasting, and tightly coupled, and are often disrupted by various events in the cluster such as failures, maintenance, and job scheduling. To handle these events, we rely on cold migration, where we first checkpoint the entire cluster, replace the related machines, and then restart the training. This approach leads to disruptions to the training jobs, resulting in significant downtime. In this paper, we present TrainMover, a live migration system that enables machine replacement during machine learning training. TrainMover minimizes downtime by leveraging member replacement of collective communication groups and sandbox lazy initialization. Our evaluation demonstrates that TrainMover achieves 16x less downtime compared to all baselines, effectively handling data center events like straggler rebalancing, maintenance, and unexpected failures.
Minder: Faulty Machine Detection for Large-scale Distributed Model Training
Nov 04, 2024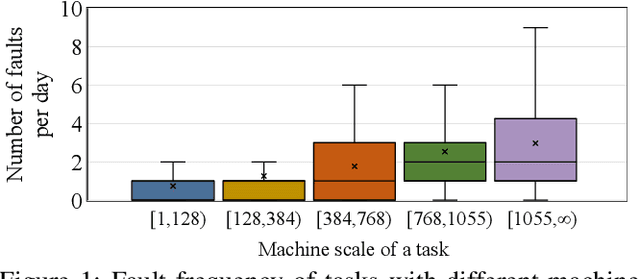
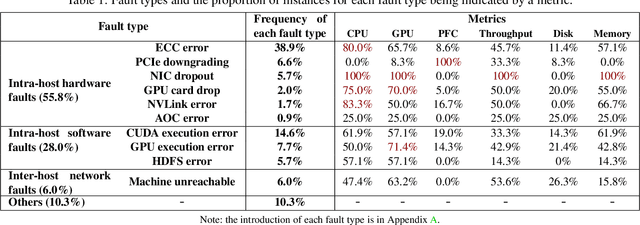
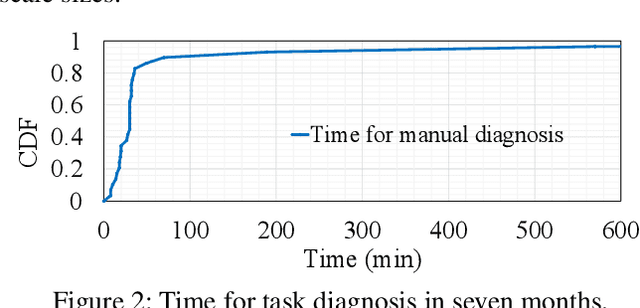
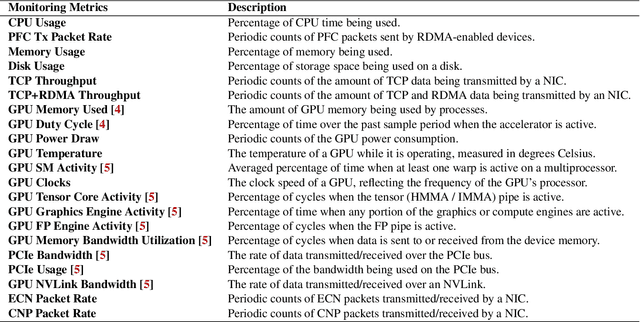
Large-scale distributed model training requires simultaneous training on up to thousands of machines. Faulty machine detection is critical when an unexpected fault occurs in a machine. From our experience, a training task can encounter two faults per day on average, possibly leading to a halt for hours. To address the drawbacks of the time-consuming and labor-intensive manual scrutiny, we propose Minder, an automatic faulty machine detector for distributed training tasks. The key idea of Minder is to automatically and efficiently detect faulty distinctive monitoring metric patterns, which could last for a period before the entire training task comes to a halt. Minder has been deployed in our production environment for over one year, monitoring daily distributed training tasks where each involves up to thousands of machines. In our real-world fault detection scenarios, Minder can accurately and efficiently react to faults within 3.6 seconds on average, with a precision of 0.904 and F1-score of 0.893.
Federated Learning Clients Clustering with Adaptation to Data Drifts
Nov 03, 2024



Federated Learning (FL) enables deep learning model training across edge devices and protects user privacy by retaining raw data locally. Data heterogeneity in client distributions slows model convergence and leads to plateauing with reduced precision. Clustered FL solutions address this by grouping clients with statistically similar data and training models for each cluster. However, maintaining consistent client similarity within each group becomes challenging when data drifts occur, significantly impacting model accuracy. In this paper, we introduce Fielding, a clustered FL framework that handles data drifts promptly with low overheads. Fielding detects drifts on all clients and performs selective label distribution-based re-clustering to balance cluster optimality and model performance, remaining robust to malicious clients and varied heterogeneity degrees. Our evaluations show that Fielding improves model final accuracy by 1.9%-5.9% and reaches target accuracies 1.16x-2.61x faster.
NEO: Saving GPU Memory Crisis with CPU Offloading for Online LLM Inference
Nov 02, 2024


Online LLM inference powers many exciting applications such as intelligent chatbots and autonomous agents. Modern LLM inference engines widely rely on request batching to improve inference throughput, aiming to make it cost-efficient when running on expensive GPU accelerators. However, the limited GPU memory has largely limited the batch size achieved in practice, leaving significant GPU compute resources wasted. We present NEO, an online LLM inference system that offloads part of attention compute and KV cache states from the GPU to the local host CPU, effectively increasing the GPU batch size and thus inference throughput. To this end, NEO proposes asymmetric GPU-CPU pipelining and load-aware scheduling to balance GPU and CPU loads and fully utilize their compute and memory resources. We evaluate NEO on a wide range of workloads (i.e., code generation, text summarization), GPUs (i.e., T4, A10G, H100), and LLM models (i.e., 7B, 8B, 70B). NEO achieves up to 7.5$\times$, 26%, and 14% higher throughput compared to GPU-only approach on T4, A10G, and H100 GPUs, respectively, while maintaining the same latency; with more powerful CPUs, NEO achieves up to 79.3% throughput gain on A10G GPU.
Cora: Accelerating Stateful Network Applications with SmartNICs
Oct 29, 2024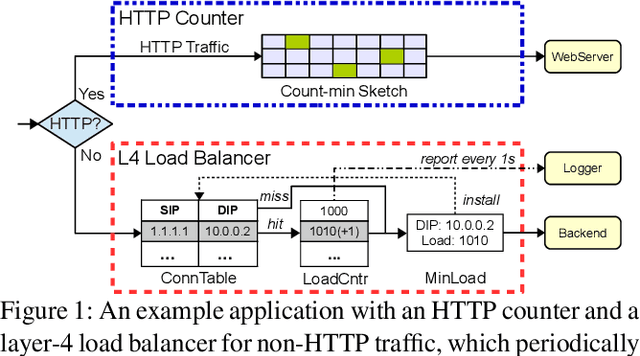
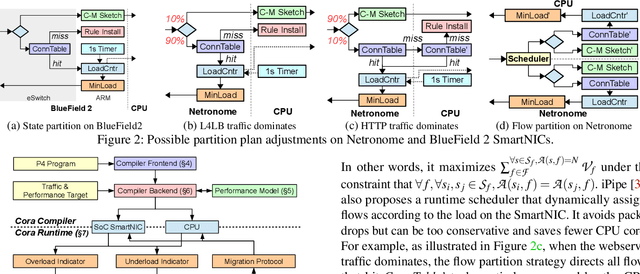
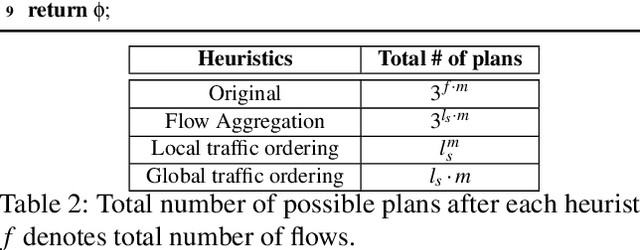
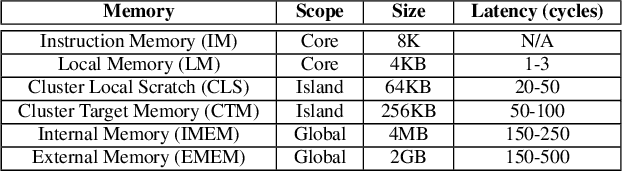
With the growing performance requirements on networked applications, there is a new trend of offloading stateful network applications to SmartNICs to improve performance and reduce the total cost of ownership. However, offloading stateful network applications is non-trivial due to state operation complexity, state resource consumption, and the complicated relationship between traffic and state. Naively partitioning the program by state or traffic can result in a suboptimal partition plan with higher CPU usage or even packet drops. In this paper, we propose Cora, a compiler and runtime that offloads stateful network applications to SmartNIC-accelerated hosts. Cora compiler introduces an accurate performance model for each SmartNIC and employs an efficient compiling algorithm to search the offloading plan. Cora runtime can monitor traffic dynamics and adapt to minimize CPU usage. Cora is built atop Netronome Agilio and BlueField 2 SmartNICs. Our evaluation shows that for the same throughput target, Cora can propose partition plans saving up to 94.0% CPU cores, 1.9 times more than baseline solutions. Under the same resource constraint, Cora can accelerate network functions by 44.9%-82.3%. Cora runtime can adapt to traffic changes and keep CPU usage low.