 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREASON: Accelerating Probabilistic Logical Reasoning for Scalable Neuro-Symbolic Intelligence
Jan 28, 2026Neuro-symbolic AI systems integrate neural perception with symbolic reasoning to enable data-efficient, interpretable, and robust intelligence beyond purely neural models. Although this compositional paradigm has shown superior performance in domains such as reasoning, planning, and verification, its deployment remains challenging due to severe inefficiencies in symbolic and probabilistic inference. Through systematic analysis of representative neuro-symbolic workloads, we identify probabilistic logical reasoning as the inefficiency bottleneck, characterized by irregular control flow, low arithmetic intensity, uncoalesced memory accesses, and poor hardware utilization on CPUs and GPUs. This paper presents REASON, an integrated acceleration framework for probabilistic logical reasoning in neuro-symbolic AI. REASON introduces a unified directed acyclic graph representation that captures common structure across symbolic and probabilistic models, coupled with adaptive pruning and regularization. At the architecture level, REASON features a reconfigurable, tree-based processing fabric optimized for irregular traversal, symbolic deduction, and probabilistic aggregation. At the system level, REASON is tightly integrated with GPU streaming multiprocessors through a programmable interface and multi-level pipeline that efficiently orchestrates compositional execution. Evaluated across six neuro-symbolic workloads, REASON achieves 12-50x speedup and 310-681x energy efficiency over desktop and edge GPUs under TSMC 28 nm node. REASON enables real-time probabilistic logical reasoning, completing end-to-end tasks in 0.8 s with 6 mm2 area and 2.12 W power, demonstrating that targeted acceleration of probabilistic logical reasoning is critical for practical and scalable neuro-symbolic AI and positioning REASON as a foundational system architecture for next-generation cognitive intelligence.
STAGE: A Symbolic Tensor grAph GEnerator for distributed AI system co-design
Nov 14, 2025Optimizing the performance of large language models (LLMs) on large-scale AI training and inference systems requires a scalable and expressive mechanism to model distributed workload execution. Such modeling is essential for pre-deployment system-level optimizations (e.g., parallelization strategies) and design-space explorations. While recent efforts have proposed collecting execution traces from real systems, access to large-scale infrastructure remains limited to major cloud providers. Moreover, traces obtained from existing platforms cannot be easily adapted to study future larger-scale system configurations. We introduce Symbolic Tensor grAph GEnerator(STAGE), a framework that synthesizes high-fidelity execution traces to accurately model LLM workloads. STAGE supports a comprehensive set of parallelization strategies, allowing users to systematically explore a wide spectrum of LLM architectures and system configurations. STAGE demonstrates its scalability by synthesizing high-fidelity LLM traces spanning over 32K GPUs, while preserving tensor-level accuracy in compute, memory, and communication. STAGE is publicly available to facilitate further research in distributed machine learning systems: https://github.com/astra-sim/symbolic tensor graph
OckBench: Measuring the Efficiency of LLM Reasoning
Nov 07, 2025Large language models such as GPT-4, Claude 3, and the Gemini series have improved automated reasoning and code generation. However, existing benchmarks mainly focus on accuracy and output quality, and they ignore an important factor: decoding token efficiency. In real systems, generating 10,000 tokens versus 100,000 tokens leads to large differences in latency, cost, and energy. In this work, we introduce OckBench, a model-agnostic and hardware-agnostic benchmark that evaluates both accuracy and token count for reasoning and coding tasks. Through experiments comparing multiple open- and closed-source models, we uncover that many models with comparable accuracy differ wildly in token consumption, revealing that efficiency variance is a neglected but significant axis of differentiation. We further demonstrate Pareto frontiers over the accuracy-efficiency plane and argue for an evaluation paradigm shift: we should no longer treat tokens as "free" to multiply. OckBench provides a unified platform for measuring, comparing, and guiding research in token-efficient reasoning. Our benchmarks are available at https://ockbench.github.io/ .
Slm-mux: Orchestrating small language models for reasoning
Oct 06, 2025With the rapid development of language models, the number of small language models (SLMs) has grown significantly. Although they do not achieve state-of-the-art accuracy, they are more efficient and often excel at specific tasks. This raises a natural question: can multiple SLMs be orchestrated into a system where each contributes effectively, achieving higher accuracy than any individual model? Existing orchestration methods have primarily targeted frontier models (e.g., GPT-4) and perform suboptimally when applied to SLMs. To address this gap, we propose a three-stage approach for orchestrating SLMs. First, we introduce SLM-MUX, a multi-model architecture that effectively coordinates multiple SLMs. Building on this, we develop two optimization strategies: (i) a model selection search that identifies the most complementary SLMs from a given pool, and (ii) test-time scaling tailored to SLM-MUX. Our approach delivers strong results: Compared to existing orchestration methods, our approach achieves up to 13.4% improvement on MATH, 8.8% on GPQA, and 7.0% on GSM8K. With just two SLMS, SLM-MUX outperforms Qwen 2.5 72B on GPQA and GSM8K, and matches its performance on MATH. We further provide theoretical analyses to substantiate the advantages of our method. In summary, we demonstrate that SLMs can be effectively orchestrated into more accurate and efficient systems through the proposed approach.
ThinKV: Thought-Adaptive KV Cache Compression for Efficient Reasoning Models
Oct 01, 2025The long-output context generation of large reasoning models enables extended chain of thought (CoT) but also drives rapid growth of the key-value (KV) cache, quickly overwhelming GPU memory. To address this challenge, we propose ThinKV, a thought-adaptive KV cache compression framework. ThinKV is based on the observation that attention sparsity reveals distinct thought types with varying importance within the CoT. It applies a hybrid quantization-eviction strategy, assigning token precision by thought importance and progressively evicting tokens from less critical thoughts as reasoning trajectories evolve. Furthermore, to implement ThinKV, we design a kernel that extends PagedAttention to enable efficient reuse of evicted tokens' memory slots, eliminating compaction overheads. Extensive experiments on DeepSeek-R1-Distill, GPT-OSS, and NVIDIA AceReason across mathematics and coding benchmarks show that ThinKV achieves near-lossless accuracy with less than 5% of the original KV cache, while improving performance with up to 5.8x higher inference throughput over state-of-the-art baselines.
Win Fast or Lose Slow: Balancing Speed and Accuracy in Latency-Sensitive Decisions of LLMs
May 26, 2025Large language models (LLMs) have shown remarkable performance across diverse reasoning and generation tasks, and are increasingly deployed as agents in dynamic environments such as code generation and recommendation systems. However, many real-world applications, such as high-frequency trading and real-time competitive gaming, require decisions under strict latency constraints, where faster responses directly translate into higher rewards. Despite the importance of this latency quality trade off, it remains underexplored in the context of LLM based agents. In this work, we present the first systematic study of this trade off in real time decision making tasks. To support our investigation, we introduce two new benchmarks: HFTBench, a high frequency trading simulation, and StreetFighter, a competitive gaming platform. Our analysis reveals that optimal latency quality balance varies by task, and that sacrificing quality for lower latency can significantly enhance downstream performance. To address this, we propose FPX, an adaptive framework that dynamically selects model size and quantization level based on real time demands. Our method achieves the best performance on both benchmarks, improving win rate by up to 80% in Street Fighter and boosting daily yield by up to 26.52% in trading, underscoring the need for latency aware evaluation and deployment strategies for LLM based agents. These results demonstrate the critical importance of latency aware evaluation and deployment strategies for real world LLM based agents. Our benchmarks are available at Latency Sensitive Benchmarks.
Towards Easy and Realistic Network Infrastructure Testing for Large-scale Machine Learning
Apr 29, 2025


This paper lays the foundation for Genie, a testing framework that captures the impact of real hardware network behavior on ML workload performance, without requiring expensive GPUs. Genie uses CPU-initiated traffic over a hardware testbed to emulate GPU to GPU communication, and adapts the ASTRA-sim simulator to model interaction between the network and the ML workload.
NSFlow: An End-to-End FPGA Framework with Scalable Dataflow Architecture for Neuro-Symbolic AI
Apr 29, 2025Neuro-Symbolic AI (NSAI) is an emerging paradigm that integrates neural networks with symbolic reasoning to enhance the transparency, reasoning capabilities, and data efficiency of AI systems. Recent NSAI systems have gained traction due to their exceptional performance in reasoning tasks and human-AI collaborative scenarios. Despite these algorithmic advancements, executing NSAI tasks on existing hardware (e.g., CPUs, GPUs, TPUs) remains challenging, due to their heterogeneous computing kernels, high memory intensity, and unique memory access patterns. Moreover, current NSAI algorithms exhibit significant variation in operation types and scales, making them incompatible with existing ML accelerators. These challenges highlight the need for a versatile and flexible acceleration framework tailored to NSAI workloads. In this paper, we propose NSFlow, an FPGA-based acceleration framework designed to achieve high efficiency, scalability, and versatility across NSAI systems. NSFlow features a design architecture generator that identifies workload data dependencies and creates optimized dataflow architectures, as well as a reconfigurable array with flexible compute units, re-organizable memory, and mixed-precision capabilities. Evaluating across NSAI workloads, NSFlow achieves 31x speedup over Jetson TX2, more than 2x over GPU, 8x speedup over TPU-like systolic array, and more than 3x over Xilinx DPU. NSFlow also demonstrates enhanced scalability, with only 4x runtime increase when symbolic workloads scale by 150x. To the best of our knowledge, NSFlow is the first framework to enable real-time generalizable NSAI algorithms acceleration, demonstrating a promising solution for next-generation cognitive systems.
Generative AI in Embodied Systems: System-Level Analysis of Performance, Efficiency and Scalability
Apr 26, 2025Embodied systems, where generative autonomous agents engage with the physical world through integrated perception, cognition, action, and advanced reasoning powered by large language models (LLMs), hold immense potential for addressing complex, long-horizon, multi-objective tasks in real-world environments. However, deploying these systems remains challenging due to prolonged runtime latency, limited scalability, and heightened sensitivity, leading to significant system inefficiencies. In this paper, we aim to understand the workload characteristics of embodied agent systems and explore optimization solutions. We systematically categorize these systems into four paradigms and conduct benchmarking studies to evaluate their task performance and system efficiency across various modules, agent scales, and embodied tasks. Our benchmarking studies uncover critical challenges, such as prolonged planning and communication latency, redundant agent interactions, complex low-level control mechanisms, memory inconsistencies, exploding prompt lengths, sensitivity to self-correction and execution, sharp declines in success rates, and reduced collaboration efficiency as agent numbers increase. Leveraging these profiling insights, we suggest system optimization strategies to improve the performance, efficiency, and scalability of embodied agents across different paradigms. This paper presents the first system-level analysis of embodied AI agents, and explores opportunities for advancing future embodied system design.
Accelerating LLM Inference with Flexible N:M Sparsity via A Fully Digital Compute-in-Memory Accelerator
Apr 19, 2025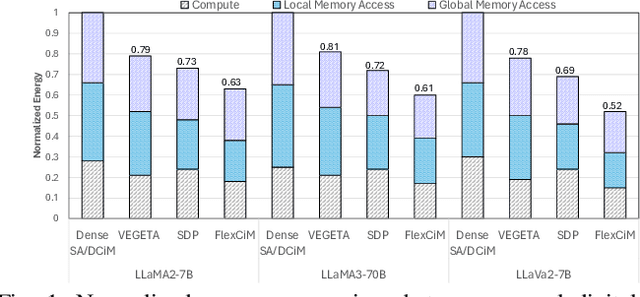
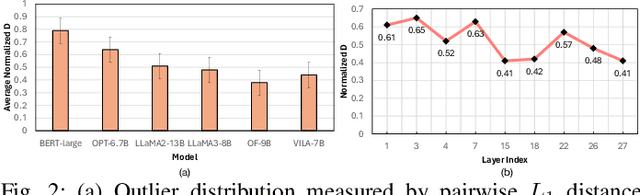
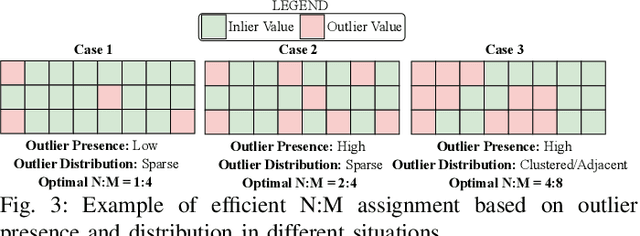
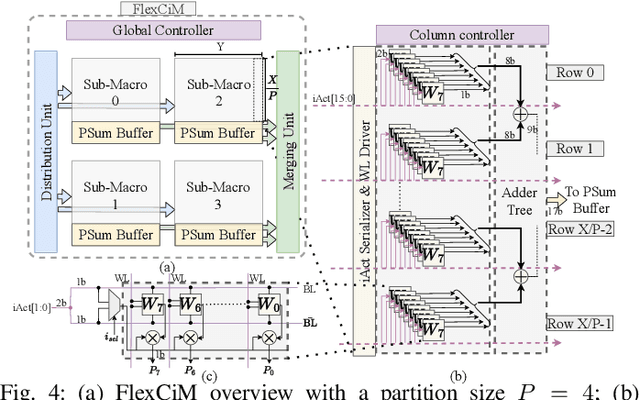
Large language model (LLM) pruning with fixed N:M structured sparsity significantly limits the expressivity of the sparse model, yielding sub-optimal performance. In contrast, supporting multiple N:M patterns to provide sparse representational freedom introduces costly overhead in hardware. To address these challenges for LLMs, we first present a flexible layer-wise outlier-density-aware N:M sparsity (FLOW) selection method. FLOW enables the identification of optimal layer-wise N and M values (from a given range) by simultaneously accounting for the presence and distribution of outliers, allowing a higher degree of representational freedom. To deploy sparse models with such N:M flexibility, we then introduce a flexible, low-overhead digital compute-in-memory architecture (FlexCiM). FlexCiM supports diverse sparsity patterns by partitioning a digital CiM (DCiM) macro into smaller sub-macros, which are adaptively aggregated and disaggregated through distribution and merging mechanisms for different N and M values. Extensive experiments on both transformer-based and recurrence-based state space foundation models (SSMs) demonstrate that FLOW outperforms existing alternatives with an accuracy improvement of up to 36%, while FlexCiM achieves up to 1.75x lower inference latency and 1.5x lower energy consumption compared to existing sparse accelerators. Code is available at: https://github.com/FLOW-open-project/FLOW