 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOuroMamba: A Data-Free Quantization Framework for Vision Mamba Models
Mar 13, 2025We present OuroMamba, the first data-free post-training quantization (DFQ) method for vision Mamba-based models (VMMs). We identify two key challenges in enabling DFQ for VMMs, (1) VMM's recurrent state transitions restricts capturing of long-range interactions and leads to semantically weak synthetic data, (2) VMM activations exhibit dynamic outlier variations across time-steps, rendering existing static PTQ techniques ineffective. To address these challenges, OuroMamba presents a two-stage framework: (1) OuroMamba-Gen to generate semantically rich and meaningful synthetic data. It applies contrastive learning on patch level VMM features generated through neighborhood interactions in the latent state space, (2) OuroMamba-Quant to employ mixed-precision quantization with lightweight dynamic outlier detection during inference. In specific, we present a thresholding based outlier channel selection strategy for activations that gets updated every time-step. Extensive experiments across vision and generative tasks show that our data-free OuroMamba surpasses existing data-driven PTQ techniques, achieving state-of-the-art performance across diverse quantization settings. Additionally, we implement efficient GPU kernels to achieve practical latency speedup of up to 2.36x. Code will be released soon.
Text-Guided Variational Image Generation for Industrial Anomaly Detection and Segmentation
Mar 10, 2024



We propose a text-guided variational image generation method to address the challenge of getting clean data for anomaly detection in industrial manufacturing. Our method utilizes text information about the target object, learned from extensive text library documents, to generate non-defective data images resembling the input image. The proposed framework ensures that the generated non-defective images align with anticipated distributions derived from textual and image-based knowledge, ensuring stability and generality. Experimental results demonstrate the effectiveness of our approach, surpassing previous methods even with limited non-defective data. Our approach is validated through generalization tests across four baseline models and three distinct datasets. We present an additional analysis to enhance the effectiveness of anomaly detection models by utilizing the generated images.
Improving Bias Mitigation through Bias Experts in Natural Language Understanding
Dec 06, 2023Biases in the dataset often enable the model to achieve high performance on in-distribution data, while poorly performing on out-of-distribution data. To mitigate the detrimental effect of the bias on the networks, previous works have proposed debiasing methods that down-weight the biased examples identified by an auxiliary model, which is trained with explicit bias labels. However, finding a type of bias in datasets is a costly process. Therefore, recent studies have attempted to make the auxiliary model biased without the guidance (or annotation) of bias labels, by constraining the model's training environment or the capability of the model itself. Despite the promising debiasing results of recent works, the multi-class learning objective, which has been naively used to train the auxiliary model, may harm the bias mitigation effect due to its regularization effect and competitive nature across classes. As an alternative, we propose a new debiasing framework that introduces binary classifiers between the auxiliary model and the main model, coined bias experts. Specifically, each bias expert is trained on a binary classification task derived from the multi-class classification task via the One-vs-Rest approach. Experimental results demonstrate that our proposed strategy improves the bias identification ability of the auxiliary model. Consequently, our debiased model consistently outperforms the state-of-the-art on various challenge datasets.
Mutual Information Maximizing Quantum Generative Adversarial Network and Its Applications in Finance
Sep 04, 2023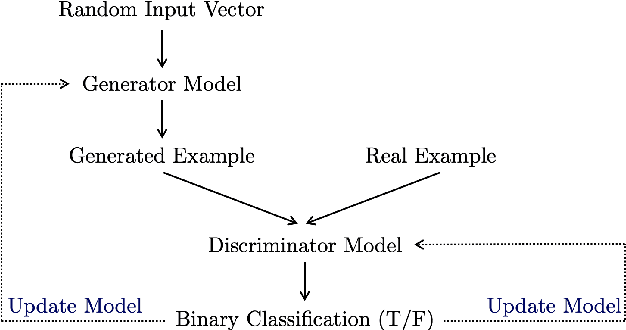
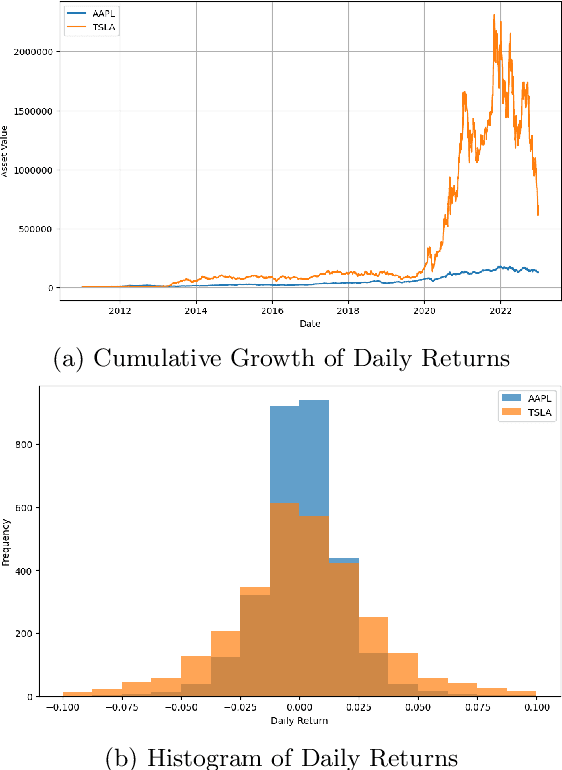
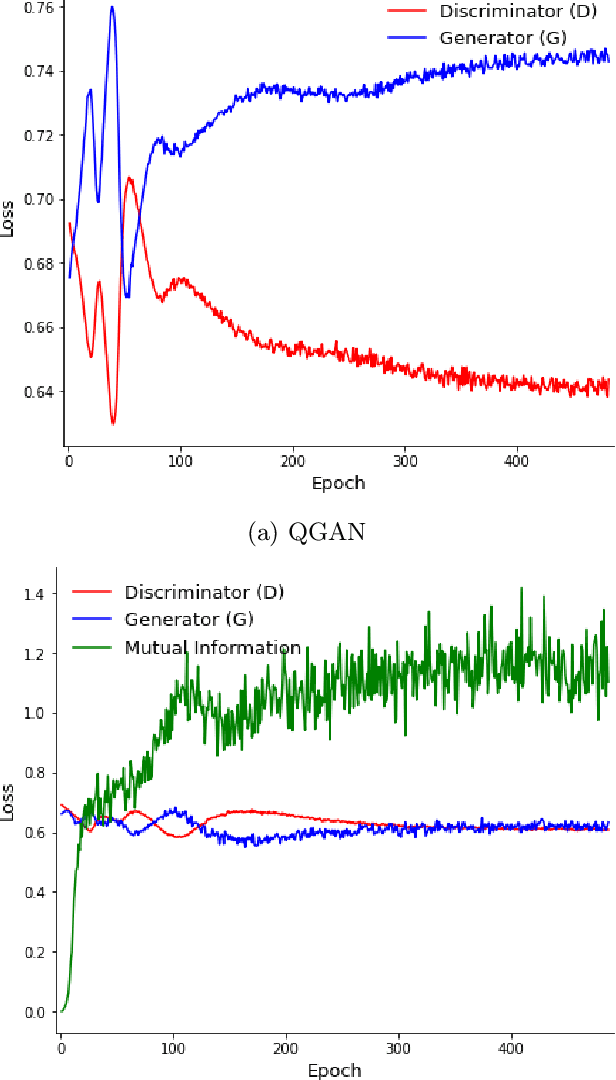
One of the most promising applications in the era of NISQ (Noisy Intermediate-Scale Quantum) computing is quantum machine learning. Quantum machine learning offers significant quantum advantages over classical machine learning across various domains. Specifically, generative adversarial networks have been recognized for their potential utility in diverse fields such as image generation, finance, and probability distribution modeling. However, these networks necessitate solutions for inherent challenges like mode collapse. In this study, we capitalize on the concept that the estimation of mutual information between high-dimensional continuous random variables can be achieved through gradient descent using neural networks. We introduce a novel approach named InfoQGAN, which employs the Mutual Information Neural Estimator (MINE) within the framework of quantum generative adversarial networks to tackle the mode collapse issue. Furthermore, we elaborate on how this approach can be applied to a financial scenario, specifically addressing the problem of generating portfolio return distributions through dynamic asset allocation. This illustrates the potential practical applicability of InfoQGAN in real-world contexts.
Efficient Pre-training of Masked Language Model via Concept-based Curriculum Masking
Dec 15, 2022



Masked language modeling (MLM) has been widely used for pre-training effective bidirectional representations, but incurs substantial training costs. In this paper, we propose a novel concept-based curriculum masking (CCM) method to efficiently pre-train a language model. CCM has two key differences from existing curriculum learning approaches to effectively reflect the nature of MLM. First, we introduce a carefully-designed linguistic difficulty criterion that evaluates the MLM difficulty of each token. Second, we construct a curriculum that gradually masks words related to the previously masked words by retrieving a knowledge graph. Experimental results show that CCM significantly improves pre-training efficiency. Specifically, the model trained with CCM shows comparative performance with the original BERT on the General Language Understanding Evaluation benchmark at half of the training cost.
Deep Learning-Based Solvability of Underdetermined Inverse Problems in Medical Imaging
Jan 07, 2020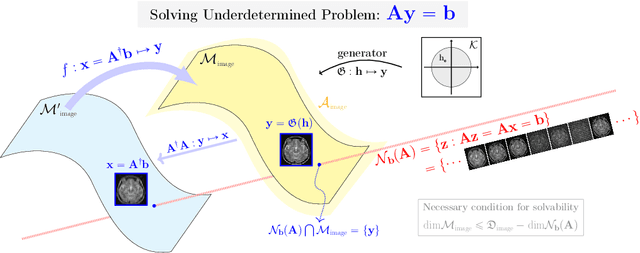
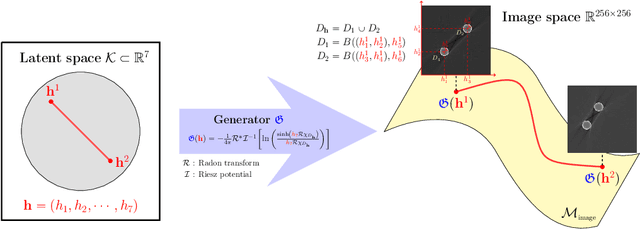
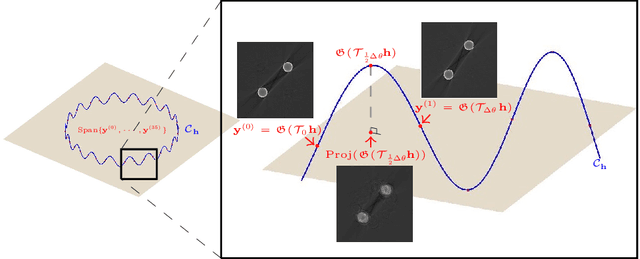
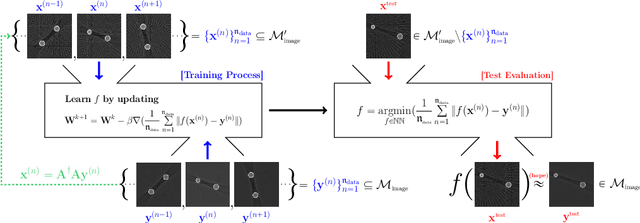
Recently, with the significant developments in deep learning techniques, solving underdetermined inverse problems has become one of the major concerns in the medical imaging domain. Typical examples include undersampled magnetic resonance imaging, interior tomography, and sparse-view computed tomography, where deep learning techniques have achieved excellent performances. Although deep learning methods appear to overcome the limitations of existing mathematical methods when handling various underdetermined problems, there is a lack of rigorous mathematical foundations that would allow us to elucidate the reasons for the remarkable performance of deep learning methods. This study focuses on learning the causal relationship regarding the structure of the training data suitable for deep learning, to solve highly underdetermined inverse problems. We observe that a majority of the problems of solving underdetermined linear systems in medical imaging are highly non-linear. Furthermore, we analyze if a desired reconstruction map can be learnable from the training data and underdetermined system.