 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Zero-shot Commonsense Reasoning by Integrating Visual Knowledge via Machine Imagination
Mar 05, 2026Recent advancements in zero-shot commonsense reasoning have empowered Pre-trained Language Models (PLMs) to acquire extensive commonsense knowledge without requiring task-specific fine-tuning. Despite this progress, these models frequently suffer from limitations caused by human reporting biases inherent in textual knowledge, leading to understanding discrepancies between machines and humans. To bridge this gap, we introduce an additional modality to enrich the reasoning capabilities of PLMs. We propose Imagine (Machine Imagination-based Reasoning), a novel zero-shot commonsense reasoning framework that supplements textual inputs with visual signals from machine-generated images. Specifically, we enhance PLMs with the ability to imagine by embedding an image generator directly into the reasoning pipeline. To facilitate effective utilization of this imagined visual context, we construct synthetic datasets designed to emulate visual question-answering scenarios. Through comprehensive evaluations on multiple commonsense reasoning benchmarks, we demonstrate that Imagine substantially outperforms existing zero-shot approaches and even surpasses advanced large language models. These results underscore the capability of machine imagination to mitigate reporting bias and significantly enhance the generalization ability of commonsense reasoning models
Bridging the Gap Between Molecule and Textual Descriptions via Substructure-aware Alignment
Oct 30, 2025Molecule and text representation learning has gained increasing interest due to its potential for enhancing the understanding of chemical information. However, existing models often struggle to capture subtle differences between molecules and their descriptions, as they lack the ability to learn fine-grained alignments between molecular substructures and chemical phrases. To address this limitation, we introduce MolBridge, a novel molecule-text learning framework based on substructure-aware alignments. Specifically, we augment the original molecule-description pairs with additional alignment signals derived from molecular substructures and chemical phrases. To effectively learn from these enriched alignments, MolBridge employs substructure-aware contrastive learning, coupled with a self-refinement mechanism that filters out noisy alignment signals. Experimental results show that MolBridge effectively captures fine-grained correspondences and outperforms state-of-the-art baselines on a wide range of molecular benchmarks, highlighting the significance of substructure-aware alignment in molecule-text learning.
C2A: Client-Customized Adaptation for Parameter-Efficient Federated Learning
Nov 01, 2024Despite the versatility of pre-trained language models (PLMs) across domains, their large memory footprints pose significant challenges in federated learning (FL), where the training model has to be distributed between a server and clients. One potential solution to bypass such constraints might be the use of parameter-efficient fine-tuning (PEFT) in the context of FL. However, we have observed that typical PEFT tends to severely suffer from heterogeneity among clients in FL scenarios, resulting in unstable and slow convergence. In this paper, we propose Client-Customized Adaptation (C2A), a novel hypernetwork-based FL framework that generates client-specific adapters by conditioning the client information. With the effectiveness of the hypernetworks in generating customized weights through learning to adopt the different characteristics of inputs, C2A can maximize the utility of shared model parameters while minimizing the divergence caused by client heterogeneity. To verify the efficacy of C2A, we perform extensive evaluations on FL scenarios involving heterogeneity in label and language distributions. Comprehensive evaluation results clearly support the superiority of C2A in terms of both efficiency and effectiveness in FL scenarios.
CleaR: Towards Robust and Generalized Parameter-Efficient Fine-Tuning for Noisy Label Learning
Oct 31, 2024Parameter-efficient fine-tuning (PEFT) has enabled the efficient optimization of cumbersome language models in real-world settings. However, as datasets in such environments often contain noisy labels that adversely affect performance, PEFT methods are inevitably exposed to noisy labels. Despite this challenge, the adaptability of PEFT to noisy environments remains underexplored. To bridge this gap, we investigate various PEFT methods under noisy labels. Interestingly, our findings reveal that PEFT has difficulty in memorizing noisy labels due to its inherently limited capacity, resulting in robustness. However, we also find that such limited capacity simultaneously makes PEFT more vulnerable to interference of noisy labels, impeding the learning of clean samples. To address this issue, we propose Clean Routing (CleaR), a novel routing-based PEFT approach that adaptively activates PEFT modules. In CleaR, PEFT modules are preferentially exposed to clean data while bypassing the noisy ones, thereby minimizing the noisy influence. To verify the efficacy of CleaR, we perform extensive experiments on diverse configurations of noisy labels. The results convincingly demonstrate that CleaR leads to substantially improved performance in noisy environments.
MELT: Materials-aware Continued Pre-training for Language Model Adaptation to Materials Science
Oct 19, 2024We introduce a novel continued pre-training method, MELT (MatEriaLs-aware continued pre-Training), specifically designed to efficiently adapt the pre-trained language models (PLMs) for materials science. Unlike previous adaptation strategies that solely focus on constructing domain-specific corpus, MELT comprehensively considers both the corpus and the training strategy, given that materials science corpus has distinct characteristics from other domains. To this end, we first construct a comprehensive materials knowledge base from the scientific corpus by building semantic graphs. Leveraging this extracted knowledge, we integrate a curriculum into the adaptation process that begins with familiar and generalized concepts and progressively moves toward more specialized terms. We conduct extensive experiments across diverse benchmarks to verify the effectiveness and generality of MELT. A comprehensive evaluation convincingly supports the strength of MELT, demonstrating superior performance compared to existing continued pre-training methods. The in-depth analysis also shows that MELT enables PLMs to effectively represent materials entities compared to the existing adaptation methods, thereby highlighting its broad applicability across a wide spectrum of materials science.
Zero-shot Commonsense Reasoning over Machine Imagination
Oct 12, 2024Recent approaches to zero-shot commonsense reasoning have enabled Pre-trained Language Models (PLMs) to learn a broad range of commonsense knowledge without being tailored to specific situations. However, they often suffer from human reporting bias inherent in textual commonsense knowledge, leading to discrepancies in understanding between PLMs and humans. In this work, we aim to bridge this gap by introducing an additional information channel to PLMs. We propose Imagine (Machine Imagination-based Reasoning), a novel zero-shot commonsense reasoning framework designed to complement textual inputs with visual signals derived from machine-generated images. To achieve this, we enhance PLMs with imagination capabilities by incorporating an image generator into the reasoning process. To guide PLMs in effectively leveraging machine imagination, we create a synthetic pre-training dataset that simulates visual question-answering. Our extensive experiments on diverse reasoning benchmarks and analysis show that Imagine outperforms existing methods by a large margin, highlighting the strength of machine imagination in mitigating reporting bias and enhancing generalization capabilities.
Improving Bias Mitigation through Bias Experts in Natural Language Understanding
Dec 06, 2023Biases in the dataset often enable the model to achieve high performance on in-distribution data, while poorly performing on out-of-distribution data. To mitigate the detrimental effect of the bias on the networks, previous works have proposed debiasing methods that down-weight the biased examples identified by an auxiliary model, which is trained with explicit bias labels. However, finding a type of bias in datasets is a costly process. Therefore, recent studies have attempted to make the auxiliary model biased without the guidance (or annotation) of bias labels, by constraining the model's training environment or the capability of the model itself. Despite the promising debiasing results of recent works, the multi-class learning objective, which has been naively used to train the auxiliary model, may harm the bias mitigation effect due to its regularization effect and competitive nature across classes. As an alternative, we propose a new debiasing framework that introduces binary classifiers between the auxiliary model and the main model, coined bias experts. Specifically, each bias expert is trained on a binary classification task derived from the multi-class classification task via the One-vs-Rest approach. Experimental results demonstrate that our proposed strategy improves the bias identification ability of the auxiliary model. Consequently, our debiased model consistently outperforms the state-of-the-art on various challenge datasets.
Learning From Drift: Federated Learning on Non-IID Data via Drift Regularization
Sep 13, 2023Federated learning algorithms perform reasonably well on independent and identically distributed (IID) data. They, on the other hand, suffer greatly from heterogeneous environments, i.e., Non-IID data. Despite the fact that many research projects have been done to address this issue, recent findings indicate that they are still sub-optimal when compared to training on IID data. In this work, we carefully analyze the existing methods in heterogeneous environments. Interestingly, we find that regularizing the classifier's outputs is quite effective in preventing performance degradation on Non-IID data. Motivated by this, we propose Learning from Drift (LfD), a novel method for effectively training the model in heterogeneous settings. Our scheme encapsulates two key components: drift estimation and drift regularization. Specifically, LfD first estimates how different the local model is from the global model (i.e., drift). The local model is then regularized such that it does not fall in the direction of the estimated drift. In the experiment, we evaluate each method through the lens of the five aspects of federated learning, i.e., Generalization, Heterogeneity, Scalability, Forgetting, and Efficiency. Comprehensive evaluation results clearly support the superiority of LfD in federated learning with Non-IID data.
Dynamic Structure Pruning for Compressing CNNs
Mar 17, 2023



Structure pruning is an effective method to compress and accelerate neural networks. While filter and channel pruning are preferable to other structure pruning methods in terms of realistic acceleration and hardware compatibility, pruning methods with a finer granularity, such as intra-channel pruning, are expected to be capable of yielding more compact and computationally efficient networks. Typical intra-channel pruning methods utilize a static and hand-crafted pruning granularity due to a large search space, which leaves room for improvement in their pruning performance. In this work, we introduce a novel structure pruning method, termed as dynamic structure pruning, to identify optimal pruning granularities for intra-channel pruning. In contrast to existing intra-channel pruning methods, the proposed method automatically optimizes dynamic pruning granularities in each layer while training deep neural networks. To achieve this, we propose a differentiable group learning method designed to efficiently learn a pruning granularity based on gradient-based learning of filter groups. The experimental results show that dynamic structure pruning achieves state-of-the-art pruning performance and better realistic acceleration on a GPU compared with channel pruning. In particular, it reduces the FLOPs of ResNet50 by 71.85% without accuracy degradation on the ImageNet dataset. Our code is available at https://github.com/irishev/DSP.
Phase-shifted Adversarial Training
Jan 12, 2023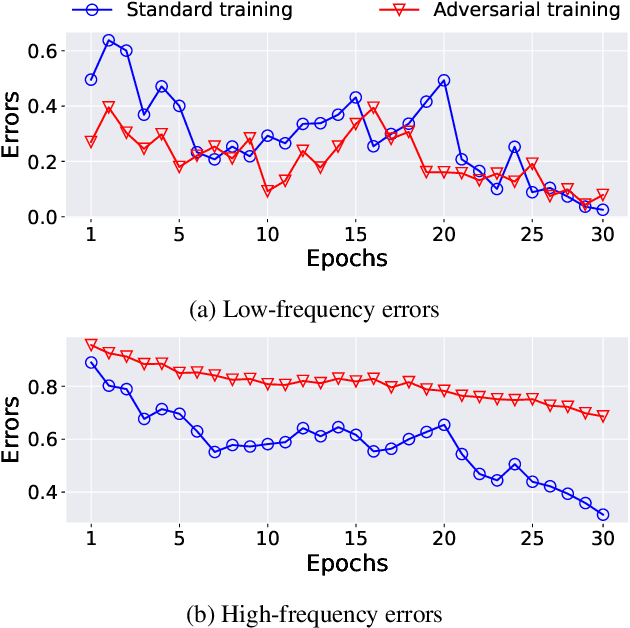



Adversarial training has been considered an imperative component for safely deploying neural network-based applications to the real world. To achieve stronger robustness, existing methods primarily focus on how to generate strong attacks by increasing the number of update steps, regularizing the models with the smoothed loss function, and injecting the randomness into the attack. Instead, we analyze the behavior of adversarial training through the lens of response frequency. We empirically discover that adversarial training causes neural networks to have low convergence to high-frequency information, resulting in highly oscillated predictions near each data. To learn high-frequency contents efficiently and effectively, we first prove that a universal phenomenon of frequency principle, i.e., \textit{lower frequencies are learned first}, still holds in adversarial training. Based on that, we propose phase-shifted adversarial training (PhaseAT) in which the model learns high-frequency components by shifting these frequencies to the low-frequency range where the fast convergence occurs. For evaluations, we conduct the experiments on CIFAR-10 and ImageNet with the adaptive attack carefully designed for reliable evaluation. Comprehensive results show that PhaseAT significantly improves the convergence for high-frequency information. This results in improved adversarial robustness by enabling the model to have smoothed predictions near each data.