 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning From Drift: Federated Learning on Non-IID Data via Drift Regularization
Sep 13, 2023Federated learning algorithms perform reasonably well on independent and identically distributed (IID) data. They, on the other hand, suffer greatly from heterogeneous environments, i.e., Non-IID data. Despite the fact that many research projects have been done to address this issue, recent findings indicate that they are still sub-optimal when compared to training on IID data. In this work, we carefully analyze the existing methods in heterogeneous environments. Interestingly, we find that regularizing the classifier's outputs is quite effective in preventing performance degradation on Non-IID data. Motivated by this, we propose Learning from Drift (LfD), a novel method for effectively training the model in heterogeneous settings. Our scheme encapsulates two key components: drift estimation and drift regularization. Specifically, LfD first estimates how different the local model is from the global model (i.e., drift). The local model is then regularized such that it does not fall in the direction of the estimated drift. In the experiment, we evaluate each method through the lens of the five aspects of federated learning, i.e., Generalization, Heterogeneity, Scalability, Forgetting, and Efficiency. Comprehensive evaluation results clearly support the superiority of LfD in federated learning with Non-IID data.
Phase-shifted Adversarial Training
Jan 12, 2023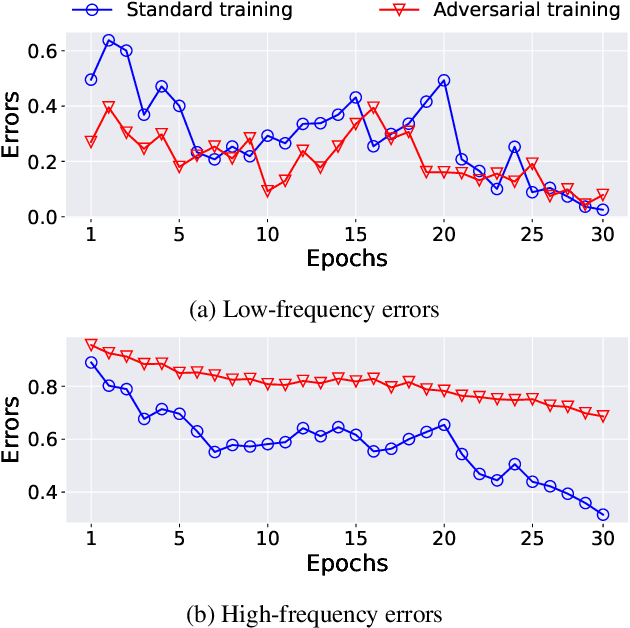



Adversarial training has been considered an imperative component for safely deploying neural network-based applications to the real world. To achieve stronger robustness, existing methods primarily focus on how to generate strong attacks by increasing the number of update steps, regularizing the models with the smoothed loss function, and injecting the randomness into the attack. Instead, we analyze the behavior of adversarial training through the lens of response frequency. We empirically discover that adversarial training causes neural networks to have low convergence to high-frequency information, resulting in highly oscillated predictions near each data. To learn high-frequency contents efficiently and effectively, we first prove that a universal phenomenon of frequency principle, i.e., \textit{lower frequencies are learned first}, still holds in adversarial training. Based on that, we propose phase-shifted adversarial training (PhaseAT) in which the model learns high-frequency components by shifting these frequencies to the low-frequency range where the fast convergence occurs. For evaluations, we conduct the experiments on CIFAR-10 and ImageNet with the adaptive attack carefully designed for reliable evaluation. Comprehensive results show that PhaseAT significantly improves the convergence for high-frequency information. This results in improved adversarial robustness by enabling the model to have smoothed predictions near each data.
Improving group robustness under noisy labels using predictive uncertainty
Dec 14, 2022



The standard empirical risk minimization (ERM) can underperform on certain minority groups (i.e., waterbirds in lands or landbirds in water) due to the spurious correlation between the input and its label. Several studies have improved the worst-group accuracy by focusing on the high-loss samples. The hypothesis behind this is that such high-loss samples are \textit{spurious-cue-free} (SCF) samples. However, these approaches can be problematic since the high-loss samples may also be samples with noisy labels in the real-world scenarios. To resolve this issue, we utilize the predictive uncertainty of a model to improve the worst-group accuracy under noisy labels. To motivate this, we theoretically show that the high-uncertainty samples are the SCF samples in the binary classification problem. This theoretical result implies that the predictive uncertainty is an adequate indicator to identify SCF samples in a noisy label setting. Motivated from this, we propose a novel ENtropy based Debiasing (END) framework that prevents models from learning the spurious cues while being robust to the noisy labels. In the END framework, we first train the \textit{identification model} to obtain the SCF samples from a training set using its predictive uncertainty. Then, another model is trained on the dataset augmented with an oversampled SCF set. The experimental results show that our END framework outperforms other strong baselines on several real-world benchmarks that consider both the noisy labels and the spurious-cues.
In Defense of Core-set: A Density-aware Core-set Selection for Active Learning
Jun 13, 2022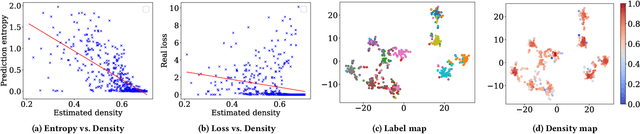
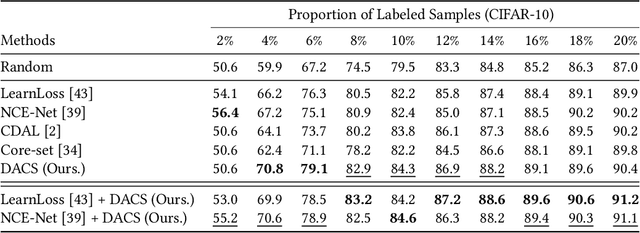
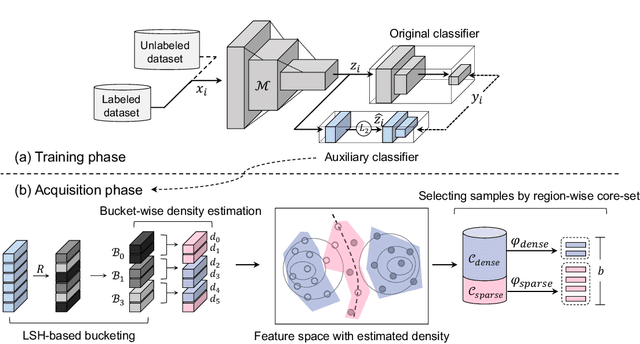
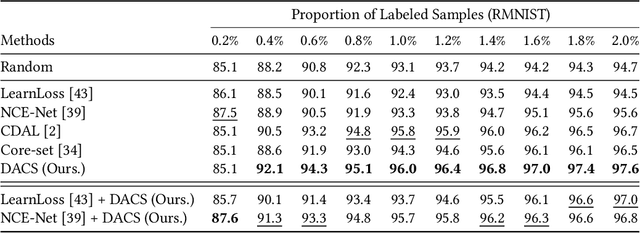
Active learning enables the efficient construction of a labeled dataset by labeling informative samples from an unlabeled dataset. In a real-world active learning scenario, considering the diversity of the selected samples is crucial because many redundant or highly similar samples exist. Core-set approach is the promising diversity-based method selecting diverse samples based on the distance between samples. However, the approach poorly performs compared to the uncertainty-based approaches that select the most difficult samples where neural models reveal low confidence. In this work, we analyze the feature space through the lens of the density and, interestingly, observe that locally sparse regions tend to have more informative samples than dense regions. Motivated by our analysis, we empower the core-set approach with the density-awareness and propose a density-aware core-set (DACS). The strategy is to estimate the density of the unlabeled samples and select diverse samples mainly from sparse regions. To reduce the computational bottlenecks in estimating the density, we also introduce a new density approximation based on locality-sensitive hashing. Experimental results clearly demonstrate the efficacy of DACS in both classification and regression tasks and specifically show that DACS can produce state-of-the-art performance in a practical scenario. Since DACS is weakly dependent on neural architectures, we present a simple yet effective combination method to show that the existing methods can be beneficially combined with DACS.
Improving evidential deep learning via multi-task learning
Dec 17, 2021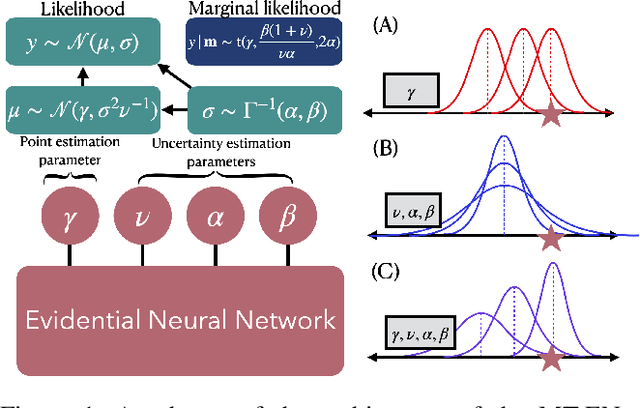
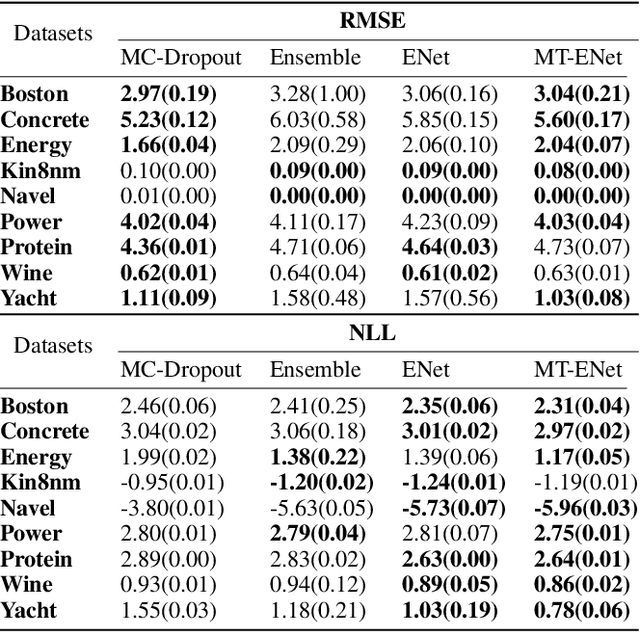

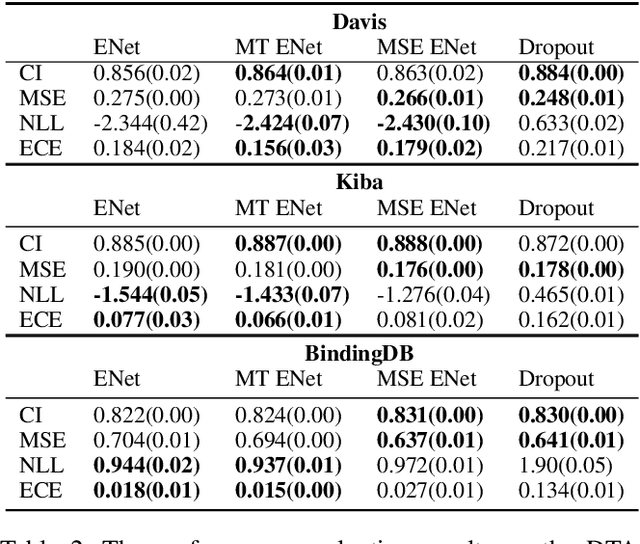
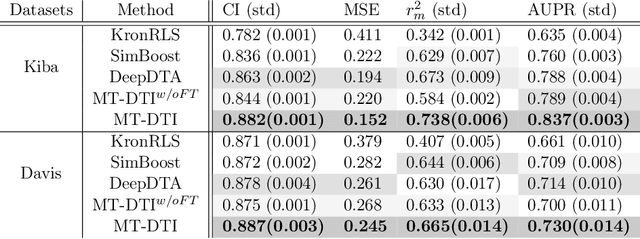
The Evidential regression network (ENet) estimates a continuous target and its predictive uncertainty without costly Bayesian model averaging. However, it is possible that the target is inaccurately predicted due to the gradient shrinkage problem of the original loss function of the ENet, the negative log marginal likelihood (NLL) loss. In this paper, the objective is to improve the prediction accuracy of the ENet while maintaining its efficient uncertainty estimation by resolving the gradient shrinkage problem. A multi-task learning (MTL) framework, referred to as MT-ENet, is proposed to accomplish this aim. In the MTL, we define the Lipschitz modified mean squared error (MSE) loss function as another loss and add it to the existing NLL loss. The Lipschitz modified MSE loss is designed to mitigate the gradient conflict with the NLL loss by dynamically adjusting its Lipschitz constant. By doing so, the Lipschitz MSE loss does not disturb the uncertainty estimation of the NLL loss. The MT-ENet enhances the predictive accuracy of the ENet without losing uncertainty estimation capability on the synthetic dataset and real-world benchmarks, including drug-target affinity (DTA) regression. Furthermore, the MT-ENet shows remarkable calibration and out-of-distribution detection capability on the DTA benchmarks.
An Interpretable Framework for Drug-Target Interaction with Gated Cross Attention
Sep 17, 2021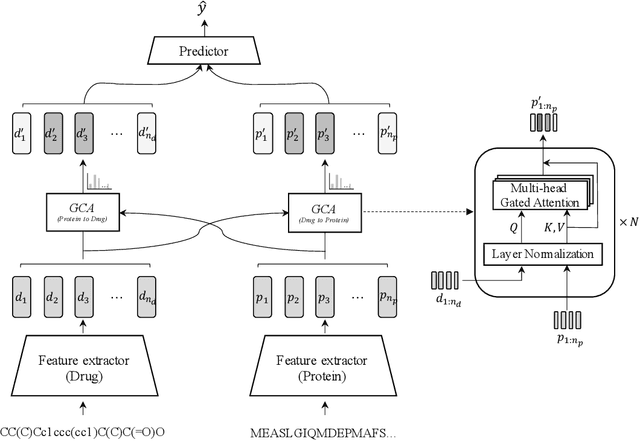

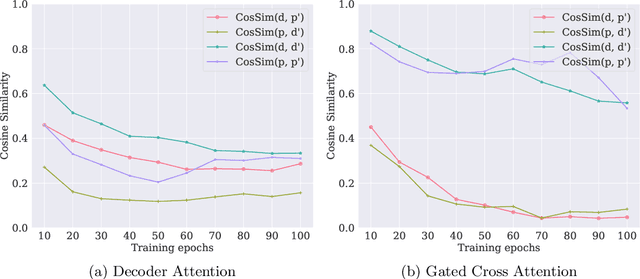
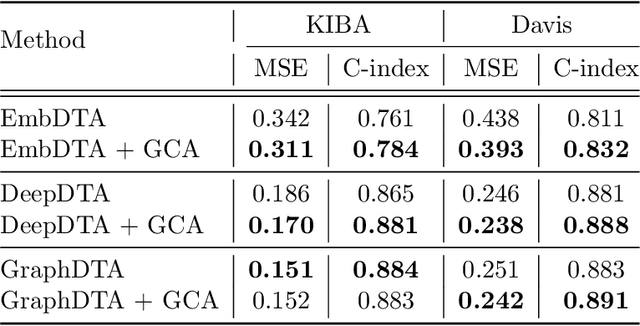
In silico prediction of drug-target interactions (DTI) is significant for drug discovery because it can largely reduce timelines and costs in the drug development process. Specifically, deep learning-based DTI approaches have been shown promising results in terms of accuracy and low cost for the prediction. However, they pay little attention to the interpretability of their prediction results and feature-level interactions between a drug and a target. In this study, we propose a novel interpretable framework that can provide reasonable cues for the interaction sites. To this end, we elaborately design a gated cross-attention mechanism that crossly attends drug and target features by constructing explicit interactions between these features. The gating function in the method enables neural models to focus on salient regions over entire sequences of drugs and proteins, and the byproduct from the function, which is the attention map, could serve as interpretable factors. The experimental results show the efficacy of the proposed method in two DTI datasets. Additionally, we show that gated cross-attention can sensitively react to the mutation, and this result could provide insights into the identification of novel drugs targeting mutant proteins.
Controlled Molecule Generator for Optimizing Multiple Chemical Properties
Oct 26, 2020
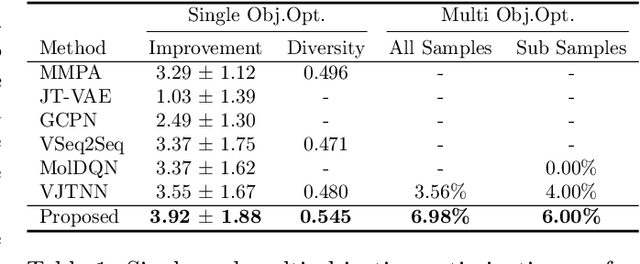
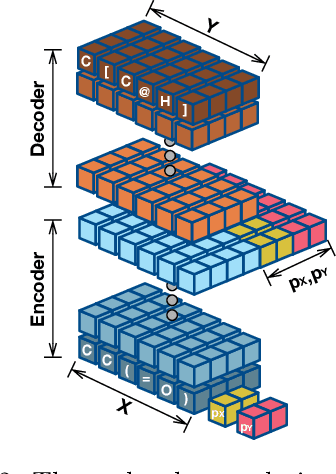
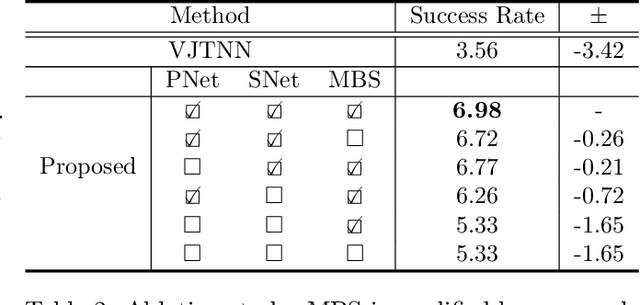
Generating a novel and optimized molecule with desired chemical properties is an essential part of the drug discovery process. Failure to meet one of the required properties can frequently lead to failure in a clinical test which is costly. In addition, optimizing these multiple properties is a challenging task because the optimization of one property is prone to changing other properties. In this paper, we pose this multi-property optimization problem as a sequence translation process and propose a new optimized molecule generator model based on the Transformer with two constraint networks: property prediction and similarity prediction. We further improve the model by incorporating score predictions from these constraint networks in a modified beam search algorithm. The experiments demonstrate that our proposed model outperforms state-of-the-art models by a significant margin for optimizing multiple properties simultaneously.
Self-Attention Based Molecule Representation for Predicting Drug-Target Interaction
Aug 15, 2019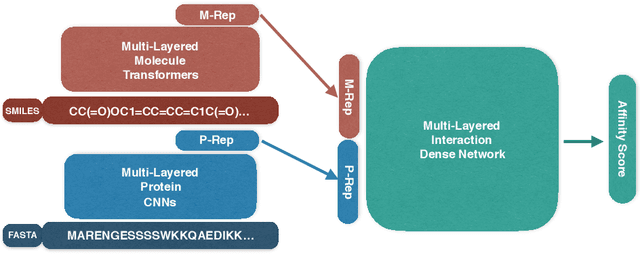

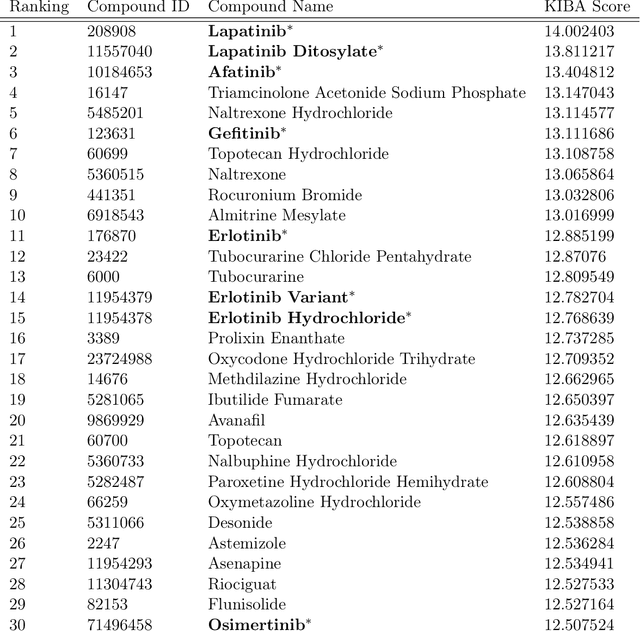
Predicting drug-target interactions (DTI) is an essential part of the drug discovery process, which is an expensive process in terms of time and cost. Therefore, reducing DTI cost could lead to reduced healthcare costs for a patient. In addition, a precisely learned molecule representation in a DTI model could contribute to developing personalized medicine, which will help many patient cohorts. In this paper, we propose a new molecule representation based on the self-attention mechanism, and a new DTI model using our molecule representation. The experiments show that our DTI model outperforms the state of the art by up to 4.9% points in terms of area under the precision-recall curve. Moreover, a study using the DrugBank database proves that our model effectively lists all known drugs targeting a specific cancer biomarker in the top-30 candidate list.
The Pupil Has Become the Master: Teacher-Student Model-Based Word Embedding Distillation with Ensemble Learning
May 31, 2019
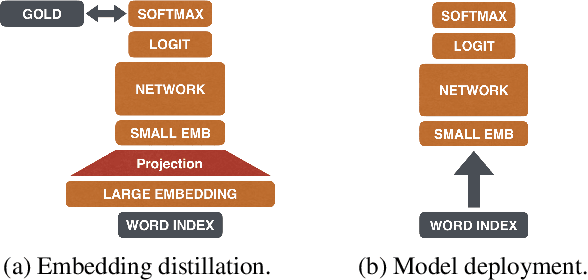
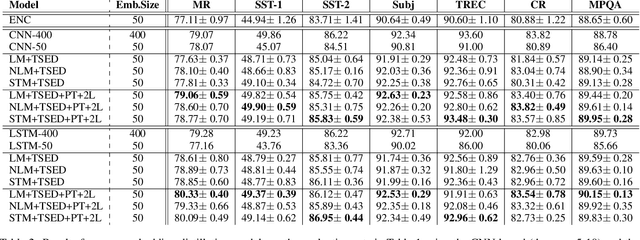
Recent advances in deep learning have facilitated the demand of neural models for real applications. In practice, these applications often need to be deployed with limited resources while keeping high accuracy. This paper touches the core of neural models in NLP, word embeddings, and presents a new embedding distillation framework that remarkably reduces the dimension of word embeddings without compromising accuracy. A novel distillation ensemble approach is also proposed that trains a high-efficient student model using multiple teacher models. In our approach, the teacher models play roles only during training such that the student model operates on its own without getting supports from the teacher models during decoding, which makes it eighty times faster and lighter than other typical ensemble methods. All models are evaluated on seven document classification datasets and show a significant advantage over the teacher models for most cases. Our analysis depicts insightful transformation of word embeddings from distillation and suggests a future direction to ensemble approaches using neural models.
Multimodal Ensemble Approach to Incorporate Various Types of Clinical Notes for Predicting Readmission
May 31, 2019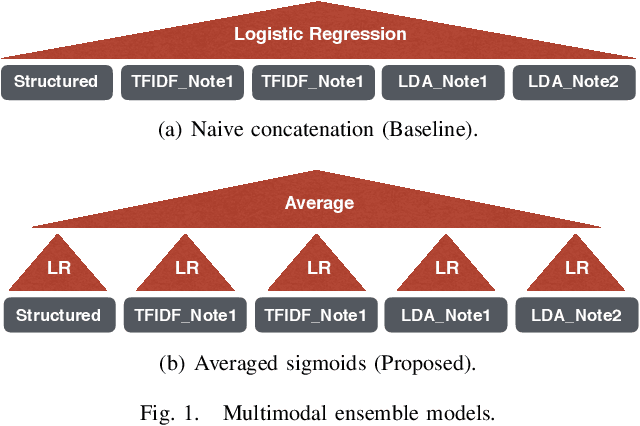
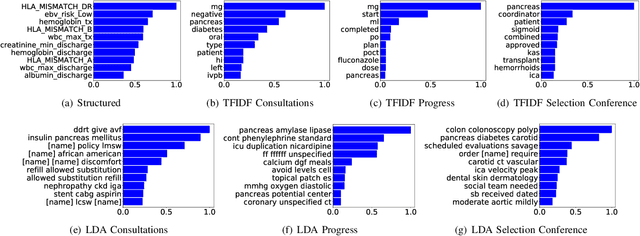
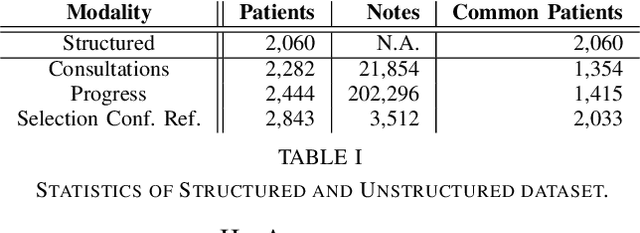
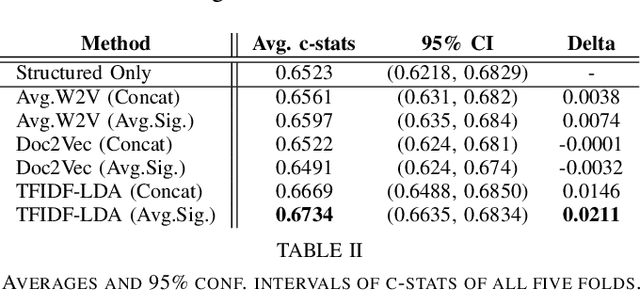
Electronic Health Records (EHRs) have been heavily used to predict various downstream clinical tasks such as readmission or mortality. One of the modalities in EHRs, clinical notes, has not been fully explored for these tasks due to its unstructured and inexplicable nature. Although recent advances in deep learning (DL) enables models to extract interpretable features from unstructured data, they often require a large amount of training data. However, many tasks in medical domains inherently consist of small sample data with lengthy documents; for a kidney transplant as an example, data from only a few thousand of patients are available and each patient's document consists of a couple of millions of words in major hospitals. Thus, complex DL methods cannot be applied to these kinds of domains. In this paper, we present a comprehensive ensemble model using vector space modeling and topic modeling. Our proposed model is evaluated on the readmission task of kidney transplant patients and improves 0.0211 in terms of c-statistics from the previous state-of-the-art approach using structured data, while typical DL methods fail to beat this approach. The proposed architecture provides the interpretable score for each feature from both modalities, structured and unstructured data, which is shown to be meaningful through a physician's evaluation.
* 4 pages, IEEE BHI 2019