 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMotif-2-12.7B-Reasoning: A Practitioner's Guide to RL Training Recipes
Dec 11, 2025We introduce Motif-2-12.7B-Reasoning, a 12.7B parameter language model designed to bridge the gap between open-weight systems and proprietary frontier models in complex reasoning and long-context understanding. Addressing the common challenges of model collapse and training instability in reasoning adaptation, we propose a comprehensive, reproducible training recipe spanning system, data, and algorithmic optimizations. Our approach combines memory-efficient infrastructure for 64K-token contexts using hybrid parallelism and kernel-level optimizations with a two-stage Supervised Fine-Tuning (SFT) curriculum that mitigates distribution mismatch through verified, aligned synthetic data. Furthermore, we detail a robust Reinforcement Learning Fine-Tuning (RLFT) pipeline that stabilizes training via difficulty-aware data filtering and mixed-policy trajectory reuse. Empirical results demonstrate that Motif-2-12.7B-Reasoning achieves performance comparable to models with significantly larger parameter counts across mathematics, coding, and agentic benchmarks, offering the community a competitive open model and a practical blueprint for scaling reasoning capabilities under realistic compute constraints.
Motif 2 12.7B technical report
Nov 07, 2025We introduce Motif-2-12.7B, a new open-weight foundation model that pushes the efficiency frontier of large language models by combining architectural innovation with system-level optimization. Designed for scalable language understanding and robust instruction generalization under constrained compute budgets, Motif-2-12.7B builds upon Motif-2.6B with the integration of Grouped Differential Attention (GDA), which improves representational efficiency by disentangling signal and noise-control attention pathways. The model is pre-trained on 5.5 trillion tokens spanning diverse linguistic, mathematical, scientific, and programming domains using a curriculum-driven data scheduler that gradually changes the data composition ratio. The training system leverages the MuonClip optimizer alongside custom high-performance kernels, including fused PolyNorm activations and the Parallel Muon algorithm, yielding significant throughput and memory efficiency gains in large-scale distributed environments. Post-training employs a three-stage supervised fine-tuning pipeline that successively enhances general instruction adherence, compositional understanding, and linguistic precision. Motif-2-12.7B demonstrates competitive performance across diverse benchmarks, showing that thoughtful architectural scaling and optimized training design can rival the capabilities of much larger models.
Grouped Differential Attention
Oct 08, 2025The self-attention mechanism, while foundational to modern Transformer architectures, suffers from a critical inefficiency: it frequently allocates substantial attention to redundant or noisy context. Differential Attention addressed this by using subtractive attention maps for signal and noise, but its required balanced head allocation imposes rigid constraints on representational flexibility and scalability. To overcome this, we propose Grouped Differential Attention (GDA), a novel approach that introduces unbalanced head allocation between signal-preserving and noise-control groups. GDA significantly enhances signal focus by strategically assigning more heads to signal extraction and fewer to noise-control, stabilizing the latter through controlled repetition (akin to GQA). This design achieves stronger signal fidelity with minimal computational overhead. We further extend this principle to group-differentiated growth, a scalable strategy that selectively replicates only the signal-focused heads, thereby ensuring efficient capacity expansion. Through large-scale pretraining and continual training experiments, we demonstrate that moderate imbalance ratios in GDA yield substantial improvements in generalization and stability compared to symmetric baselines. Our results collectively establish that ratio-aware head allocation and selective expansion offer an effective and practical path toward designing scalable, computation-efficient Transformer architectures.
Expanding Foundational Language Capabilities in Open-Source LLMs through a Korean Case Study
Sep 04, 2025We introduce Llama-3-Motif, a language model consisting of 102 billion parameters, specifically designed to enhance Korean capabilities while retaining strong performance in English. Developed on the Llama 3 architecture, Llama-3-Motif employs advanced training techniques, including LlamaPro and Masked Structure Growth, to effectively scale the model without altering its core Transformer architecture. Using the MoAI platform for efficient training across hyperscale GPU clusters, we optimized Llama-3-Motif using a carefully curated dataset that maintains a balanced ratio of Korean and English data. Llama-3-Motif shows decent performance on Korean-specific benchmarks, outperforming existing models and achieving results comparable to GPT-4.
Improving group robustness under noisy labels using predictive uncertainty
Dec 14, 2022The standard empirical risk minimization (ERM) can underperform on certain minority groups (i.e., waterbirds in lands or landbirds in water) due to the spurious correlation between the input and its label. Several studies have improved the worst-group accuracy by focusing on the high-loss samples. The hypothesis behind this is that such high-loss samples are \textit{spurious-cue-free} (SCF) samples. However, these approaches can be problematic since the high-loss samples may also be samples with noisy labels in the real-world scenarios. To resolve this issue, we utilize the predictive uncertainty of a model to improve the worst-group accuracy under noisy labels. To motivate this, we theoretically show that the high-uncertainty samples are the SCF samples in the binary classification problem. This theoretical result implies that the predictive uncertainty is an adequate indicator to identify SCF samples in a noisy label setting. Motivated from this, we propose a novel ENtropy based Debiasing (END) framework that prevents models from learning the spurious cues while being robust to the noisy labels. In the END framework, we first train the \textit{identification model} to obtain the SCF samples from a training set using its predictive uncertainty. Then, another model is trained on the dataset augmented with an oversampled SCF set. The experimental results show that our END framework outperforms other strong baselines on several real-world benchmarks that consider both the noisy labels and the spurious-cues.
Improving evidential deep learning via multi-task learning
Dec 17, 2021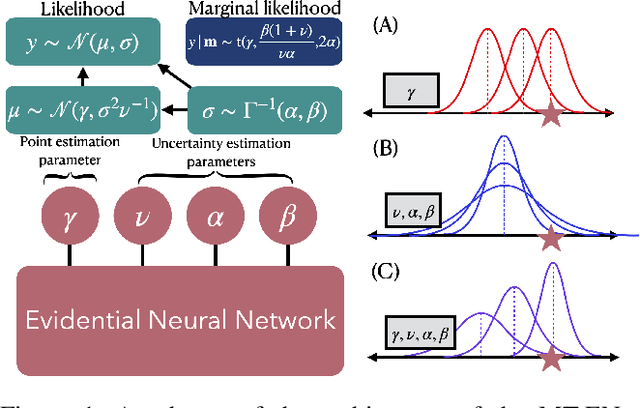
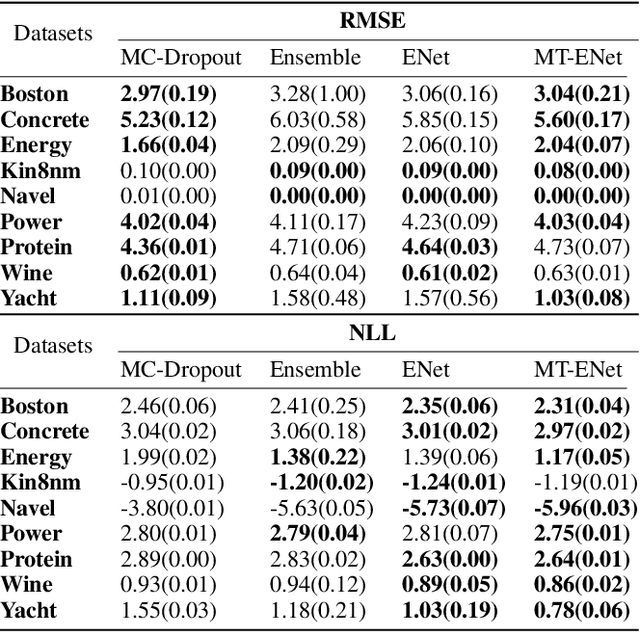

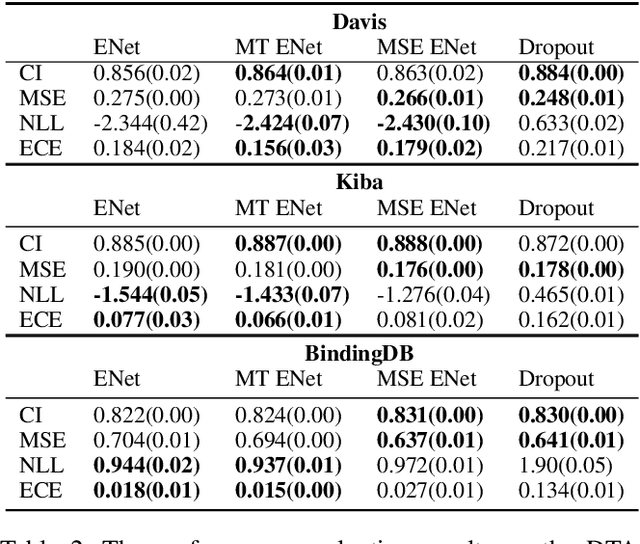
The Evidential regression network (ENet) estimates a continuous target and its predictive uncertainty without costly Bayesian model averaging. However, it is possible that the target is inaccurately predicted due to the gradient shrinkage problem of the original loss function of the ENet, the negative log marginal likelihood (NLL) loss. In this paper, the objective is to improve the prediction accuracy of the ENet while maintaining its efficient uncertainty estimation by resolving the gradient shrinkage problem. A multi-task learning (MTL) framework, referred to as MT-ENet, is proposed to accomplish this aim. In the MTL, we define the Lipschitz modified mean squared error (MSE) loss function as another loss and add it to the existing NLL loss. The Lipschitz modified MSE loss is designed to mitigate the gradient conflict with the NLL loss by dynamically adjusting its Lipschitz constant. By doing so, the Lipschitz MSE loss does not disturb the uncertainty estimation of the NLL loss. The MT-ENet enhances the predictive accuracy of the ENet without losing uncertainty estimation capability on the synthetic dataset and real-world benchmarks, including drug-target affinity (DTA) regression. Furthermore, the MT-ENet shows remarkable calibration and out-of-distribution detection capability on the DTA benchmarks.