 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Pupil Has Become the Master: Teacher-Student Model-Based Word Embedding Distillation with Ensemble Learning
Paper and Code

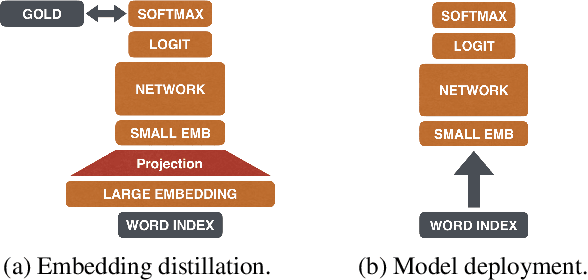
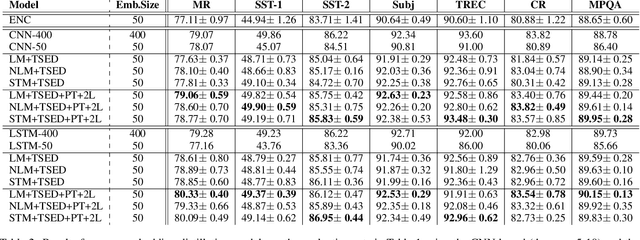
Recent advances in deep learning have facilitated the demand of neural models for real applications. In practice, these applications often need to be deployed with limited resources while keeping high accuracy. This paper touches the core of neural models in NLP, word embeddings, and presents a new embedding distillation framework that remarkably reduces the dimension of word embeddings without compromising accuracy. A novel distillation ensemble approach is also proposed that trains a high-efficient student model using multiple teacher models. In our approach, the teacher models play roles only during training such that the student model operates on its own without getting supports from the teacher models during decoding, which makes it eighty times faster and lighter than other typical ensemble methods. All models are evaluated on seven document classification datasets and show a significant advantage over the teacher models for most cases. Our analysis depicts insightful transformation of word embeddings from distillation and suggests a future direction to ensemble approaches using neural models.