 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompactRAG: Reducing LLM Calls and Token Overhead in Multi-Hop Question Answering
Feb 05, 2026Retrieval-augmented generation (RAG) has become a key paradigm for knowledge-intensive question answering. However, existing multi-hop RAG systems remain inefficient, as they alternate between retrieval and reasoning at each step, resulting in repeated LLM calls, high token consumption, and unstable entity grounding across hops. We propose CompactRAG, a simple yet effective framework that decouples offline corpus restructuring from online reasoning. In the offline stage, an LLM reads the corpus once and converts it into an atomic QA knowledge base, which represents knowledge as minimal, fine-grained question-answer pairs. In the online stage, complex queries are decomposed and carefully rewritten to preserve entity consistency, and are resolved through dense retrieval followed by RoBERTa-based answer extraction. Notably, during inference, the LLM is invoked only twice in total - once for sub-question decomposition and once for final answer synthesis - regardless of the number of reasoning hops. Experiments on HotpotQA, 2WikiMultiHopQA, and MuSiQue demonstrate that CompactRAG achieves competitive accuracy while substantially reducing token consumption compared to iterative RAG baselines, highlighting a cost-efficient and practical approach to multi-hop reasoning over large knowledge corpora. The implementation is available at GitHub.
Kimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
WorldVQA: Measuring Atomic World Knowledge in Multimodal Large Language Models
Jan 28, 2026We introduce WorldVQA, a benchmark designed to evaluate the atomic visual world knowledge of Multimodal Large Language Models (MLLMs). Unlike current evaluations, which often conflate visual knowledge retrieval with reasoning, WorldVQA decouples these capabilities to strictly measure "what the model memorizes." The benchmark assesses the atomic capability of grounding and naming visual entities across a stratified taxonomy, spanning from common head-class objects to long-tail rarities. We expect WorldVQA to serve as a rigorous test for visual factuality, thereby establishing a standard for assessing the encyclopedic breadth and hallucination rates of current and next-generation frontier models.
Towards Pixel-Level VLM Perception via Simple Points Prediction
Jan 27, 2026We present SimpleSeg, a strikingly simple yet highly effective approach to endow Multimodal Large Language Models (MLLMs) with native pixel-level perception. Our method reframes segmentation as a simple sequence generation problem: the model directly predicts sequences of points (textual coordinates) delineating object boundaries, entirely within its language space. To achieve high fidelity, we introduce a two-stage SF$\to$RL training pipeline, where Reinforcement Learning with an IoU-based reward refines the point sequences to accurately match ground-truth contours. We find that the standard MLLM architecture possesses a strong, inherent capacity for low-level perception that can be unlocked without any specialized architecture. On segmentation benchmarks, SimpleSeg achieves performance that is comparable to, and often surpasses, methods relying on complex, task-specific designs. This work lays out that precise spatial understanding can emerge from simple point prediction, challenging the prevailing need for auxiliary components and paving the way for more unified and capable VLMs. Homepage: https://simpleseg.github.io/
LongCat-Flash-Thinking-2601 Technical Report
Jan 23, 2026We introduce LongCat-Flash-Thinking-2601, a 560-billion-parameter open-source Mixture-of-Experts (MoE) reasoning model with superior agentic reasoning capability. LongCat-Flash-Thinking-2601 achieves state-of-the-art performance among open-source models on a wide range of agentic benchmarks, including agentic search, agentic tool use, and tool-integrated reasoning. Beyond benchmark performance, the model demonstrates strong generalization to complex tool interactions and robust behavior under noisy real-world environments. Its advanced capability stems from a unified training framework that combines domain-parallel expert training with subsequent fusion, together with an end-to-end co-design of data construction, environments, algorithms, and infrastructure spanning from pre-training to post-training. In particular, the model's strong generalization capability in complex tool-use are driven by our in-depth exploration of environment scaling and principled task construction. To optimize long-tailed, skewed generation and multi-turn agentic interactions, and to enable stable training across over 10,000 environments spanning more than 20 domains, we systematically extend our asynchronous reinforcement learning framework, DORA, for stable and efficient large-scale multi-environment training. Furthermore, recognizing that real-world tasks are inherently noisy, we conduct a systematic analysis and decomposition of real-world noise patterns, and design targeted training procedures to explicitly incorporate such imperfections into the training process, resulting in improved robustness for real-world applications. To further enhance performance on complex reasoning tasks, we introduce a Heavy Thinking mode that enables effective test-time scaling by jointly expanding reasoning depth and width through intensive parallel thinking.
Stephanie2: Thinking, Waiting, and Making Decisions Like Humans in Step-by-Step AI Social Chat
Jan 09, 2026Instant-messaging human social chat typically progresses through a sequence of short messages. Existing step-by-step AI chatting systems typically split a one-shot generation into multiple messages and send them sequentially, but they lack an active waiting mechanism and exhibit unnatural message pacing. In order to address these issues, we propose Stephanie2, a novel next-generation step-wise decision-making dialogue agent. With active waiting and message-pace adaptation, Stephanie2 explicitly decides at each step whether to send or wait, and models latency as the sum of thinking time and typing time to achieve more natural pacing. We further introduce a time-window-based dual-agent dialogue system to generate pseudo dialogue histories for human and automatic evaluations. Experiments show that Stephanie2 clearly outperforms Stephanie1 on metrics such as naturalness and engagement, and achieves a higher pass rate on human evaluation with the role identification Turing test.
TransactionGPT
Nov 12, 2025We present TransactionGPT (TGPT), a foundation model for consumer transaction data within one of world's largest payment networks. TGPT is designed to understand and generate transaction trajectories while simultaneously supporting a variety of downstream prediction and classification tasks. We introduce a novel 3D-Transformer architecture specifically tailored for capturing the complex dynamics in payment transaction data. This architecture incorporates design innovations that enhance modality fusion and computational efficiency, while seamlessly enabling joint optimization with downstream objectives. Trained on billion-scale real-world transactions, TGPT significantly improves downstream classification performance against a competitive production model and exhibits advantages over baselines in generating future transactions. We conduct extensive empirical evaluations utilizing a diverse collection of company transaction datasets spanning multiple downstream tasks, thereby enabling a thorough assessment of TGPT's effectiveness and efficiency in comparison to established methodologies. Furthermore, we examine the incorporation of LLM-derived embeddings within TGPT and benchmark its performance against fine-tuned LLMs, demonstrating that TGPT achieves superior predictive accuracy as well as faster training and inference. We anticipate that the architectural innovations and practical guidelines from this work will advance foundation models for transaction-like data and catalyze future research in this emerging field.
CARE-Bench: A Benchmark of Diverse Client Simulations Guided by Expert Principles for Evaluating LLMs in Psychological Counseling
Nov 12, 2025The mismatch between the growing demand for psychological counseling and the limited availability of services has motivated research into the application of Large Language Models (LLMs) in this domain. Consequently, there is a need for a robust and unified benchmark to assess the counseling competence of various LLMs. Existing works, however, are limited by unprofessional client simulation, static question-and-answer evaluation formats, and unidimensional metrics. These limitations hinder their effectiveness in assessing a model's comprehensive ability to handle diverse and complex clients. To address this gap, we introduce \textbf{CARE-Bench}, a dynamic and interactive automated benchmark. It is built upon diverse client profiles derived from real-world counseling cases and simulated according to expert guidelines. CARE-Bench provides a multidimensional performance evaluation grounded in established psychological scales. Using CARE-Bench, we evaluate several general-purpose LLMs and specialized counseling models, revealing their current limitations. In collaboration with psychologists, we conduct a detailed analysis of the reasons for LLMs' failures when interacting with clients of different types, which provides directions for developing more comprehensive, universal, and effective counseling models.
What Makes Reasoning Invalid: Echo Reflection Mitigation for Large Language Models
Nov 09, 2025
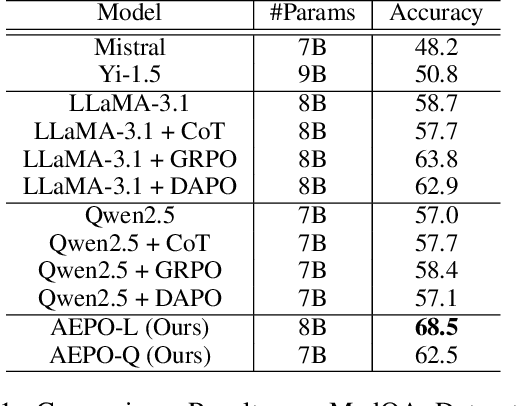
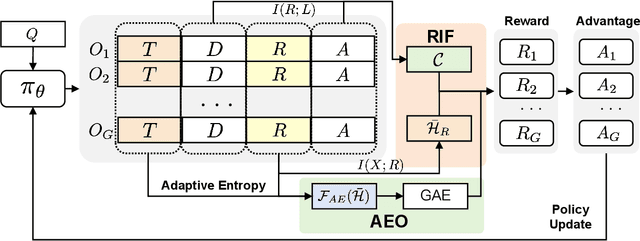
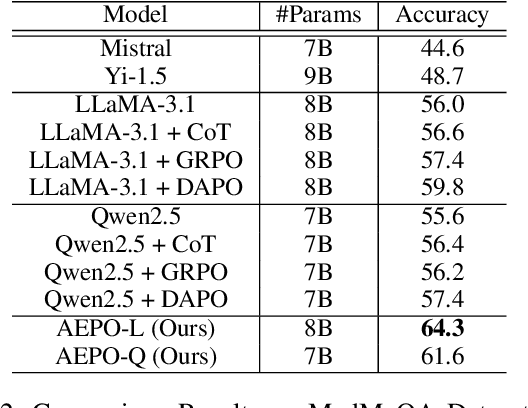
Large Language Models (LLMs) have demonstrated remarkable performance across a wide range of reasoning tasks. Recent methods have further improved LLM performance in complex mathematical reasoning. However, when extending these methods beyond the domain of mathematical reasoning to tasks involving complex domain-specific knowledge, we observe a consistent failure of LLMs to generate novel insights during the reflection stage. Instead of conducting genuine cognitive refinement, the model tends to mechanically reiterate earlier reasoning steps without introducing new information or perspectives, a phenomenon referred to as "Echo Reflection". We attribute this behavior to two key defects: (1) Uncontrollable information flow during response generation, which allows premature intermediate thoughts to propagate unchecked and distort final decisions; (2) Insufficient exploration of internal knowledge during reflection, leading to repeating earlier findings rather than generating new cognitive insights. Building on these findings, we proposed a novel reinforcement learning method termed Adaptive Entropy Policy Optimization (AEPO). Specifically, the AEPO framework consists of two major components: (1) Reflection-aware Information Filtration, which quantifies the cognitive information flow and prevents the final answer from being affected by earlier bad cognitive information; (2) Adaptive-Entropy Optimization, which dynamically balances exploration and exploitation across different reasoning stages, promoting both reflective diversity and answer correctness. Extensive experiments demonstrate that AEPO consistently achieves state-of-the-art performance over mainstream reinforcement learning baselines across diverse benchmarks.
Align-then-Slide: A complete evaluation framework for Ultra-Long Document-Level Machine Translation
Sep 04, 2025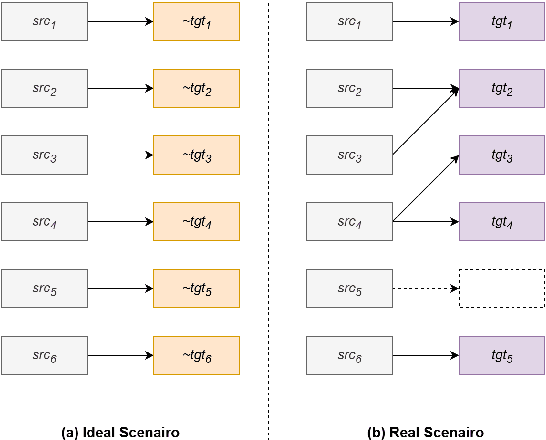
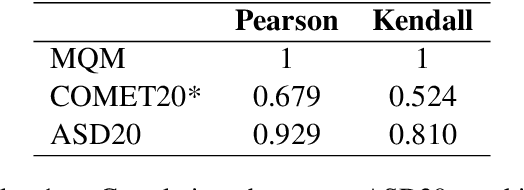
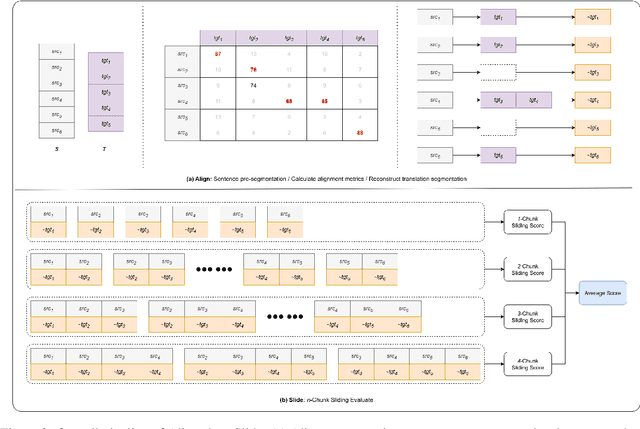
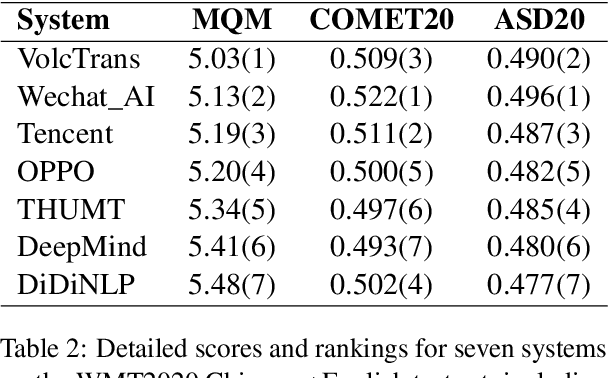
Large language models (LLMs) have ushered in a new era for document-level machine translation (\textit{doc}-mt), yet their whole-document outputs challenge existing evaluation methods that assume sentence-by-sentence alignment. We introduce \textit{\textbf{Align-then-Slide}}, a complete evaluation framework for ultra-long doc-mt. In the Align stage, we automatically infer sentence-level source-target correspondences and rebuild the target to match the source sentence number, resolving omissions and many-to-one/one-to-many mappings. In the n-Chunk Sliding Evaluate stage, we calculate averaged metric scores under 1-, 2-, 3- and 4-chunk for multi-granularity assessment. Experiments on the WMT benchmark show a Pearson correlation of 0.929 between our method with expert MQM rankings. On a newly curated real-world test set, our method again aligns closely with human judgments. Furthermore, preference data produced by Align-then-Slide enables effective CPO training and its direct use as a reward model for GRPO, both yielding translations preferred over a vanilla SFT baseline. The results validate our framework as an accurate, robust, and actionable evaluation tool for doc-mt systems.