 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable long-term traffic modelling on national road networks using theory-informed deep learning
Mar 27, 2026Long-term traffic modelling is fundamental to transport planning, but existing approaches often trade off interpretability, transferability, and predictive accuracy. Classical travel demand models provide behavioural structure but rely on strong assumptions and extensive calibration, whereas generic deep learning models capture complex patterns but often lack theoretical grounding and spatial transferability, limiting their usefulness for long-term planning applications. We propose DeepDemand, a theory-informed deep learning framework that embeds key components of travel demand theory to predict long-term highway traffic volumes using external socioeconomic features and road-network structure. The framework integrates a competitive two-source Dijkstra procedure for local origin-destination (OD) region extraction and OD pair screening with a differentiable architecture modelling OD interactions and travel-time deterrence. The model is evaluated using eight years (2017-2024) of observations on the UK strategic road network, covering 5088 highway segments. Under random cross-validation, DeepDemand achieves an R2 of 0.718 and an MAE of 7406 vehicles, outperforming linear, ridge, random forest, and gravity-style baselines. Performance remains strong under spatial cross-validation (R2 = 0.665), indicating good geographic transferability. Interpretability analysis reveals a stable nonlinear travel-time deterrence pattern, key socioeconomic drivers of demand, and polycentric OD interaction structures aligned with major employment centres and transport hubs. These results highlight the value of integrating transport theory with deep learning for interpretable highway traffic modelling and practical planning applications.
Conformal Selective Prediction with General Risk Control
Mar 25, 2026In deploying artificial intelligence (AI) models, selective prediction offers the option to abstain from making a prediction when uncertain about model quality. To fulfill its promise, it is crucial to enforce strict and precise error control over cases where the model is trusted. We propose Selective Conformal Risk control with E-values (SCoRE), a new framework for deriving such decisions for any trained model and any user-defined, bounded and continuously-valued risk. SCoRE offers two types of guarantees on the risk among ``positive'' cases in which the system opts to trust the model. Built upon conformal inference and hypothesis testing ideas, SCoRE first constructs a class of (generalized) e-values, which are non-negative random variables whose product with the unknown risk has expectation no greater than one. Such a property is ensured by data exchangeability without requiring any modeling assumptions. Passing these e-values on to hypothesis testing procedures, we yield the binary trust decisions with finite-sample error control. SCoRE avoids the need of uniform concentration, and can be readily extended to settings with distribution shifts. We evaluate the proposed methods with simulations and demonstrate their efficacy through applications to error management in drug discovery, health risk prediction, and large language models.
Online Selective Conformal Prediction with Asymmetric Rules: A Permutation Test Approach
Feb 10, 2026Selective conformal prediction aims to construct prediction sets with valid coverage for a test unit conditional on it being selected by a data-driven mechanism. While existing methods in the offline setting handle any selection mechanism that is permutation invariant to the labeled data, their extension to the online setting -- where data arrives sequentially and later decisions depend on earlier ones -- is challenged by the fact that the selection mechanism is naturally asymmetric. As such, existing methods only address a limited collection of selection mechanisms. In this paper, we propose PErmutation-based Mondrian Conformal Inference (PEMI), a general permutation-based framework for selective conformal prediction with arbitrary asymmetric selection rules. Motivated by full and Mondrian conformal prediction, PEMI identifies all permutations of the observed data (or a Monte-Carlo subset thereof) that lead to the same selection event, and calibrates a prediction set using conformity scores over this selection-preserving reference set. Under standard exchangeability conditions, our prediction sets achieve finite-sample exact selection-conditional coverage for any asymmetric selection mechanism and any prediction model. PEMI naturally incorporates additional offline labeled data, extends to selection mechanisms with multiple test samples, and achieves FCR control with fine-grained selection taxonomies. We further work out several efficient instantiations for commonly-used online selection rules, including covariate-based rules, conformal p/e-values-based procedures, and selection based on earlier outcomes. Finally, we demonstrate the efficacy of our methods across various selection rules on a real drug discovery dataset and investigate their performance via simulations.
Scaling medical imaging report generation with multimodal reinforcement learning
Jan 23, 2026Frontier models have demonstrated remarkable capabilities in understanding and reasoning with natural-language text, but they still exhibit major competency gaps in multimodal understanding and reasoning especially in high-value verticals such as biomedicine. Medical imaging report generation is a prominent example. Supervised fine-tuning can substantially improve performance, but they are prone to overfitting to superficial boilerplate patterns. In this paper, we introduce Universal Report Generation (UniRG) as a general framework for medical imaging report generation. By leveraging reinforcement learning as a unifying mechanism to directly optimize for evaluation metrics designed for end applications, UniRG can significantly improve upon supervised fine-tuning and attain durable generalization across diverse institutions and clinical practices. We trained UniRG-CXR on publicly available chest X-ray (CXR) data and conducted a thorough evaluation in CXR report generation with rigorous evaluation scenarios. On the authoritative ReXrank benchmark, UniRG-CXR sets new overall SOTA, outperforming prior state of the art by a wide margin.
Multi-Distribution Robust Conformal Prediction
Jan 06, 2026In many fairness and distribution robustness problems, one has access to labeled data from multiple source distributions yet the test data may come from an arbitrary member or a mixture of them. We study the problem of constructing a conformal prediction set that is uniformly valid across multiple, heterogeneous distributions, in the sense that no matter which distribution the test point is from, the coverage of the prediction set is guaranteed to exceed a pre-specified level. We first propose a max-p aggregation scheme that delivers finite-sample, multi-distribution coverage given any conformity scores associated with each distribution. Upon studying several efficiency optimization programs subject to uniform coverage, we prove the optimality and tightness of our aggregation scheme, and propose a general algorithm to learn conformity scores that lead to efficient prediction sets after the aggregation under standard conditions. We discuss how our framework relates to group-wise distributionally robust optimization, sub-population shift, fairness, and multi-source learning. In synthetic and real-data experiments, our method delivers valid worst-case coverage across multiple distributions while greatly reducing the set size compared with naively applying max-p aggregation to single-source conformity scores, and can be comparable in size to single-source prediction sets with popular, standard conformity scores.
X-Reasoner: Towards Generalizable Reasoning Across Modalities and Domains
May 06, 2025Recent proprietary models (e.g., o3) have begun to demonstrate strong multimodal reasoning capabilities. Yet, most existing open-source research concentrates on training text-only reasoning models, with evaluations limited to mainly mathematical and general-domain tasks. Therefore, it remains unclear how to effectively extend reasoning capabilities beyond text input and general domains. This paper explores a fundamental research question: Is reasoning generalizable across modalities and domains? Our findings support an affirmative answer: General-domain text-based post-training can enable such strong generalizable reasoning. Leveraging this finding, we introduce X-Reasoner, a vision-language model post-trained solely on general-domain text for generalizable reasoning, using a two-stage approach: an initial supervised fine-tuning phase with distilled long chain-of-thoughts, followed by reinforcement learning with verifiable rewards. Experiments show that X-Reasoner successfully transfers reasoning capabilities to both multimodal and out-of-domain settings, outperforming existing state-of-the-art models trained with in-domain and multimodal data across various general and medical benchmarks (Figure 1). Additionally, we find that X-Reasoner's performance in specialized domains can be further enhanced through continued training on domain-specific text-only data. Building upon this, we introduce X-Reasoner-Med, a medical-specialized variant that achieves new state of the art on numerous text-only and multimodal medical benchmarks.
UniCombine: Unified Multi-Conditional Combination with Diffusion Transformer
Mar 12, 2025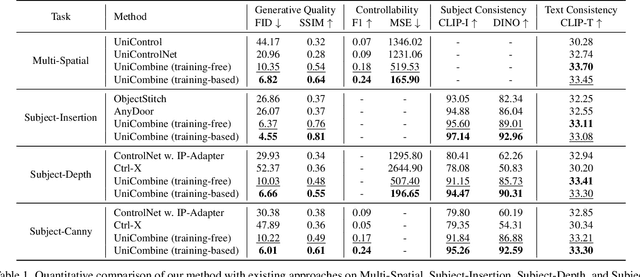
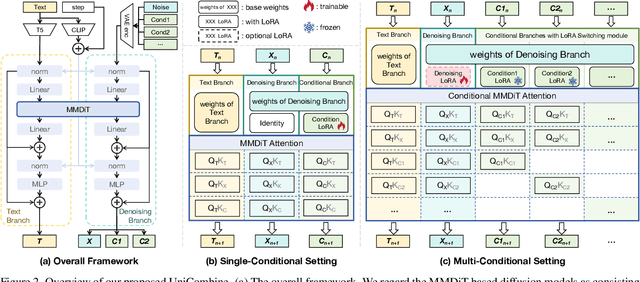
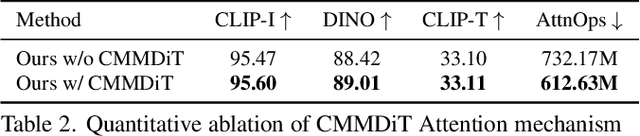
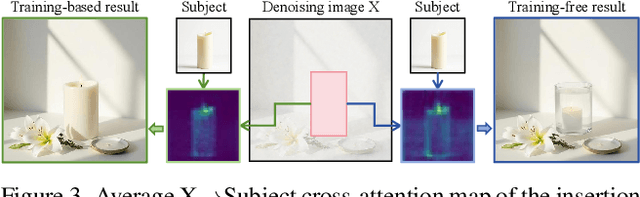
With the rapid development of diffusion models in image generation, the demand for more powerful and flexible controllable frameworks is increasing. Although existing methods can guide generation beyond text prompts, the challenge of effectively combining multiple conditional inputs while maintaining consistency with all of them remains unsolved. To address this, we introduce UniCombine, a DiT-based multi-conditional controllable generative framework capable of handling any combination of conditions, including but not limited to text prompts, spatial maps, and subject images. Specifically, we introduce a novel Conditional MMDiT Attention mechanism and incorporate a trainable LoRA module to build both the training-free and training-based versions. Additionally, we propose a new pipeline to construct SubjectSpatial200K, the first dataset designed for multi-conditional generative tasks covering both the subject-driven and spatially-aligned conditions. Extensive experimental results on multi-conditional generation demonstrate the outstanding universality and powerful capability of our approach with state-of-the-art performance.
Beyond Reweighting: On the Predictive Role of Covariate Shift in Effect Generalization
Dec 12, 2024Many existing approaches to generalizing statistical inference amidst distribution shift operate under the covariate shift assumption, which posits that the conditional distribution of unobserved variables given observable ones is invariant across populations. However, recent empirical investigations have demonstrated that adjusting for shift in observed variables (covariate shift) is often insufficient for generalization. In other words, covariate shift does not typically ``explain away'' the distribution shift between settings. As such, addressing the unknown yet non-negligible shift in the unobserved variables given observed ones (conditional shift) is crucial for generalizable inference. In this paper, we present a series of empirical evidence from two large-scale multi-site replication studies to support a new role of covariate shift in ``predicting'' the strength of the unknown conditional shift. Analyzing 680 studies across 65 sites, we find that even though the conditional shift is non-negligible, its strength can often be bounded by that of the observable covariate shift. However, this pattern only emerges when the two sources of shifts are quantified by our proposed standardized, ``pivotal'' measures. We then interpret this phenomenon by connecting it to similar patterns that can be theoretically derived from a random distribution shift model. Finally, we demonstrate that exploiting the predictive role of covariate shift leads to reliable and efficient uncertainty quantification for target estimates in generalization tasks with partially observed data. Overall, our empirical and theoretical analyses suggest a new way to approach the problem of distributional shift, generalizability, and external validity.
DAug: Diffusion-based Channel Augmentation for Radiology Image Retrieval and Classification
Dec 06, 2024



Medical image understanding requires meticulous examination of fine visual details, with particular regions requiring additional attention. While radiologists build such expertise over years of experience, it is challenging for AI models to learn where to look with limited amounts of training data. This limitation results in unsatisfying robustness in medical image understanding. To address this issue, we propose Diffusion-based Feature Augmentation (DAug), a portable method that improves a perception model's performance with a generative model's output. Specifically, we extend a radiology image to multiple channels, with the additional channels being the heatmaps of regions where diseases tend to develop. A diffusion-based image-to-image translation model was used to generate such heatmaps conditioned on selected disease classes. Our method is motivated by the fact that generative models learn the distribution of normal and abnormal images, and such knowledge is complementary to image understanding tasks. In addition, we propose the Image-Text-Class Hybrid Contrastive learning to utilize both text and class labels. With two novel approaches combined, our method surpasses baseline models without changing the model architecture, and achieves state-of-the-art performance on both medical image retrieval and classification tasks.
LDA-AQU: Adaptive Query-guided Upsampling via Local Deformable Attention
Nov 29, 2024



Feature upsampling is an essential operation in constructing deep convolutional neural networks. However, existing upsamplers either lack specific feature guidance or necessitate the utilization of high-resolution feature maps, resulting in a loss of performance and flexibility. In this paper, we find that the local self-attention naturally has the feature guidance capability, and its computational paradigm aligns closely with the essence of feature upsampling (\ie feature reassembly of neighboring points). Therefore, we introduce local self-attention into the upsampling task and demonstrate that the majority of existing upsamplers can be regarded as special cases of upsamplers based on local self-attention. Considering the potential semantic gap between upsampled points and their neighboring points, we further introduce the deformation mechanism into the upsampler based on local self-attention, thereby proposing LDA-AQU. As a novel dynamic kernel-based upsampler, LDA-AQU utilizes the feature of queries to guide the model in adaptively adjusting the position and aggregation weight of neighboring points, thereby meeting the upsampling requirements across various complex scenarios. In addition, LDA-AQU is lightweight and can be easily integrated into various model architectures. We evaluate the effectiveness of LDA-AQU across four dense prediction tasks: object detection, instance segmentation, panoptic segmentation, and semantic segmentation. LDA-AQU consistently outperforms previous state-of-the-art upsamplers, achieving performance enhancements of 1.7 AP, 1.5 AP, 2.0 PQ, and 2.5 mIoU compared to the baseline models in the aforementioned four tasks, respectively. Code is available at \url{https://github.com/duzw9311/LDA-AQU}.