 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLess Finetuning, Better Retrieval: Rethinking LLM Adaptation for Biomedical Retrievers via Synthetic Data and Model Merging
Feb 04, 2026Retrieval-augmented generation (RAG) has become the backbone of grounding Large Language Models (LLMs), improving knowledge updates and reducing hallucinations. Recently, LLM-based retriever models have shown state-of-the-art performance for RAG applications. However, several technical aspects remain underexplored on how to adapt general-purpose LLMs into effective domain-specific retrievers, especially in specialized domains such as biomedicine. We present Synthesize-Train-Merge (STM), a modular framework that enhances decoder-only LLMs with synthetic hard negatives, retrieval prompt optimization, and model merging. Experiments on a subset of 12 medical and general tasks from the MTEB benchmark show STM boosts task-specific experts by up to 23.5\% (average 7.5\%) and produces merged models that outperform both single experts and strong baselines without extensive pretraining. Our results demonstrate a scalable, efficient path for turning general LLMs into high-performing, domain-specialized retrievers, preserving general-domain capabilities while excelling on specialized tasks.
AURAD: Anatomy-Pathology Unified Radiology Synthesis with Progressive Representations
Sep 05, 2025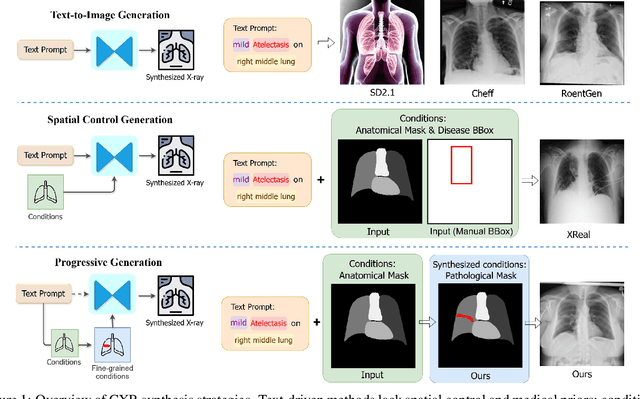

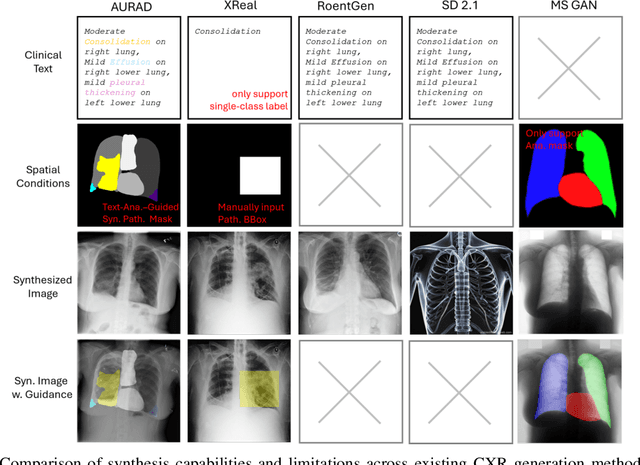
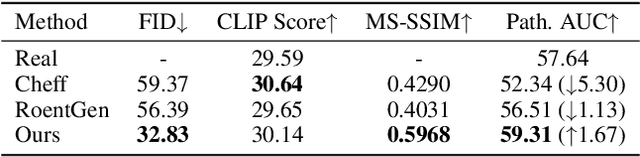
Medical image synthesis has become an essential strategy for augmenting datasets and improving model generalization in data-scarce clinical settings. However, fine-grained and controllable synthesis remains difficult due to limited high-quality annotations and domain shifts across datasets. Existing methods, often designed for natural images or well-defined tumors, struggle to generalize to chest radiographs, where disease patterns are morphologically diverse and tightly intertwined with anatomical structures. To address these challenges, we propose AURAD, a controllable radiology synthesis framework that jointly generates high-fidelity chest X-rays and pseudo semantic masks. Unlike prior approaches that rely on randomly sampled masks-limiting diversity, controllability, and clinical relevance-our method learns to generate masks that capture multi-pathology coexistence and anatomical-pathological consistency. It follows a progressive pipeline: pseudo masks are first generated from clinical prompts conditioned on anatomical structures, and then used to guide image synthesis. We also leverage pretrained expert medical models to filter outputs and ensure clinical plausibility. Beyond visual realism, the synthesized masks also serve as labels for downstream tasks such as detection and segmentation, bridging the gap between generative modeling and real-world clinical applications. Extensive experiments and blinded radiologist evaluations demonstrate the effectiveness and generalizability of our method across tasks and datasets. In particular, 78% of our synthesized images are classified as authentic by board-certified radiologists, and over 40% of predicted segmentation overlays are rated as clinically useful. All code, pre-trained models, and the synthesized dataset will be released upon publication.
Medical Red Teaming Protocol of Language Models: On the Importance of User Perspectives in Healthcare Settings
Jul 09, 2025As the performance of large language models (LLMs) continues to advance, their adoption is expanding across a wide range of domains, including the medical field. The integration of LLMs into medical applications raises critical safety concerns, particularly due to their use by users with diverse roles, e.g. patients and clinicians, and the potential for model's outputs to directly affect human health. Despite the domain-specific capabilities of medical LLMs, prior safety evaluations have largely focused only on general safety benchmarks. In this paper, we introduce a safety evaluation protocol tailored to the medical domain in both patient user and clinician user perspectives, alongside general safety assessments and quantitatively analyze the safety of medical LLMs. We bridge a gap in the literature by building the PatientSafetyBench containing 466 samples over 5 critical categories to measure safety from the perspective of the patient. We apply our red-teaming protocols on the MediPhi model collection as a case study. To our knowledge, this is the first work to define safety evaluation criteria for medical LLMs through targeted red-teaming taking three different points of view - patient, clinician, and general user - establishing a foundation for safer deployment in medical domains.
A Modular Approach for Clinical SLMs Driven by Synthetic Data with Pre-Instruction Tuning, Model Merging, and Clinical-Tasks Alignment
May 15, 2025High computation costs and latency of large language models such as GPT-4 have limited their deployment in clinical settings. Small language models (SLMs) offer a cost-effective alternative, but their limited capacity requires biomedical domain adaptation, which remains challenging. An additional bottleneck is the unavailability and high sensitivity of clinical data. To address these challenges, we propose a novel framework for adapting SLMs into high-performing clinical models. We introduce the MediPhi collection of 3.8B-parameter SLMs developed with our novel framework: pre-instruction tuning of experts on relevant medical and clinical corpora (PMC, Medical Guideline, MedWiki, etc.), model merging, and clinical-tasks alignment. To cover most clinical tasks, we extended the CLUE benchmark to CLUE+, doubling its size. Our expert models deliver relative improvements on this benchmark over the base model without any task-specific fine-tuning: 64.3% on medical entities, 49.5% on radiology reports, and 44% on ICD-10 coding (outperforming GPT-4-0125 by 14%). We unify the expert models into MediPhi via model merging, preserving gains across benchmarks. Furthermore, we built the MediFlow collection, a synthetic dataset of 2.5 million high-quality instructions on 14 medical NLP tasks, 98 fine-grained document types, and JSON format support. Alignment of MediPhi using supervised fine-tuning and direct preference optimization achieves further gains of 18.9% on average.
X-Reasoner: Towards Generalizable Reasoning Across Modalities and Domains
May 06, 2025Recent proprietary models (e.g., o3) have begun to demonstrate strong multimodal reasoning capabilities. Yet, most existing open-source research concentrates on training text-only reasoning models, with evaluations limited to mainly mathematical and general-domain tasks. Therefore, it remains unclear how to effectively extend reasoning capabilities beyond text input and general domains. This paper explores a fundamental research question: Is reasoning generalizable across modalities and domains? Our findings support an affirmative answer: General-domain text-based post-training can enable such strong generalizable reasoning. Leveraging this finding, we introduce X-Reasoner, a vision-language model post-trained solely on general-domain text for generalizable reasoning, using a two-stage approach: an initial supervised fine-tuning phase with distilled long chain-of-thoughts, followed by reinforcement learning with verifiable rewards. Experiments show that X-Reasoner successfully transfers reasoning capabilities to both multimodal and out-of-domain settings, outperforming existing state-of-the-art models trained with in-domain and multimodal data across various general and medical benchmarks (Figure 1). Additionally, we find that X-Reasoner's performance in specialized domains can be further enhanced through continued training on domain-specific text-only data. Building upon this, we introduce X-Reasoner-Med, a medical-specialized variant that achieves new state of the art on numerous text-only and multimodal medical benchmarks.
Contextual Density Ratio for Language Model Biasing of Sequence to Sequence ASR Systems
Jun 29, 2022
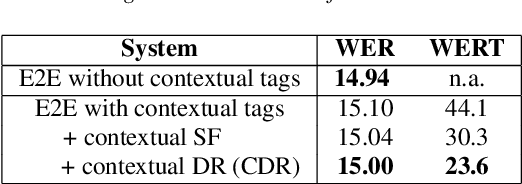

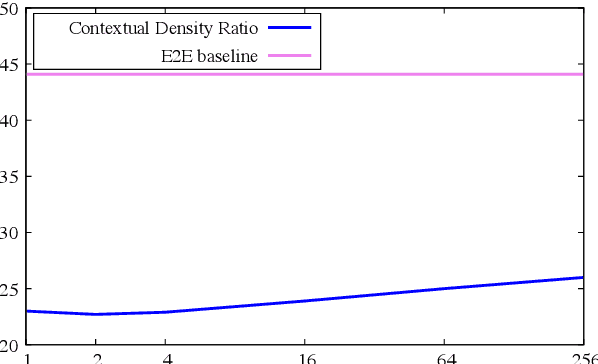
End-2-end (E2E) models have become increasingly popular in some ASR tasks because of their performance and advantages. These E2E models directly approximate the posterior distribution of tokens given the acoustic inputs. Consequently, the E2E systems implicitly define a language model (LM) over the output tokens, which makes the exploitation of independently trained language models less straightforward than in conventional ASR systems. This makes it difficult to dynamically adapt E2E ASR system to contextual profiles for better recognizing special words such as named entities. In this work, we propose a contextual density ratio approach for both training a contextual aware E2E model and adapting the language model to named entities. We apply the aforementioned technique to an E2E ASR system, which transcribes doctor and patient conversations, for better adapting the E2E system to the names in the conversations. Our proposed technique achieves a relative improvement of up to 46.5% on the names over an E2E baseline without degrading the overall recognition accuracy of the whole test set. Moreover, it also surpasses a contextual shallow fusion baseline by 22.1 % relative.
* Interspeech 2021 (draft)
Retrieval-Augmented Transformer-XL for Close-Domain Dialog Generation
May 19, 2021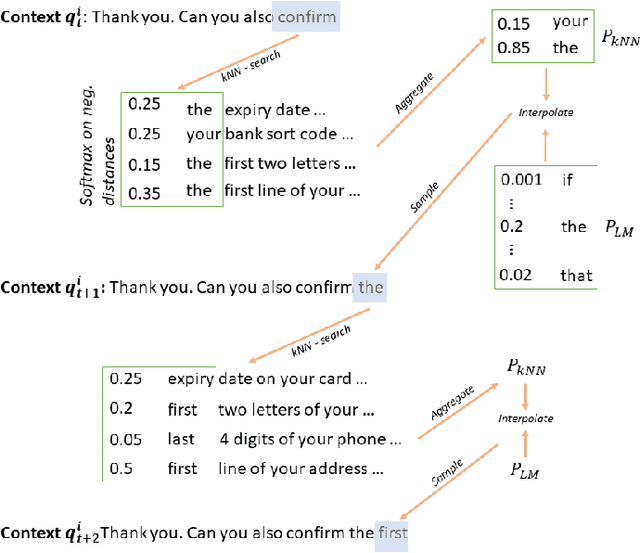

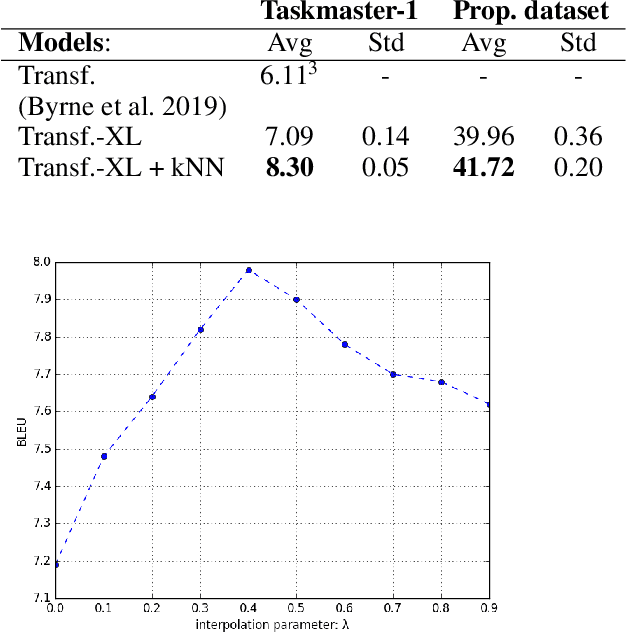
Transformer-based models have demonstrated excellent capabilities of capturing patterns and structures in natural language generation and achieved state-of-the-art results in many tasks. In this paper we present a transformer-based model for multi-turn dialog response generation. Our solution is based on a hybrid approach which augments a transformer-based generative model with a novel retrieval mechanism, which leverages the memorized information in the training data via k-Nearest Neighbor search. Our system is evaluated on two datasets made by customer/assistant dialogs: the Taskmaster-1, released by Google and holding high quality, goal-oriented conversational data and a proprietary dataset collected from a real customer service call center. Both achieve better BLEU scores over strong baselines.
DeepAAA: clinically applicable and generalizable detection of abdominal aortic aneurysm using deep learning
Jul 04, 2019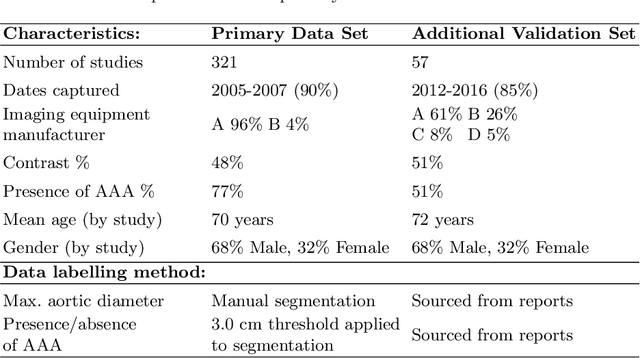
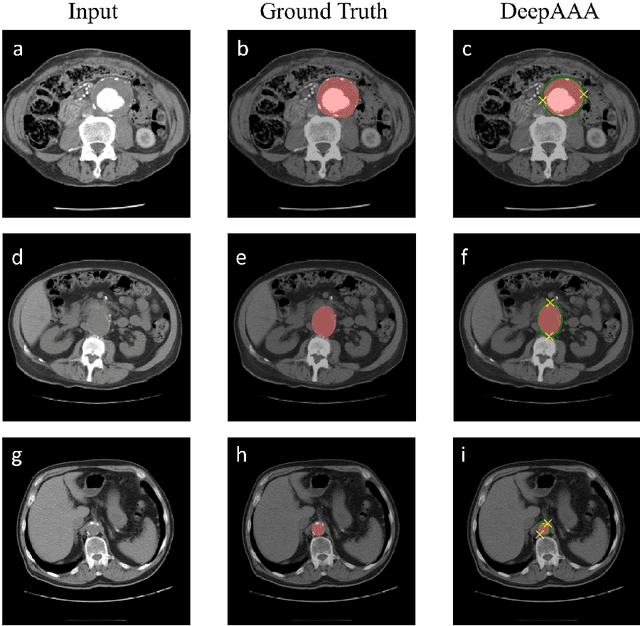
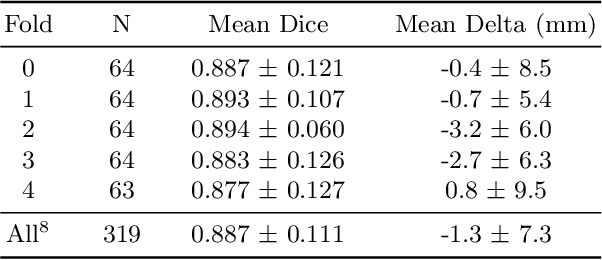
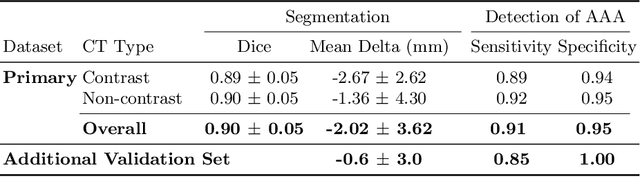
We propose a deep learning-based technique for detection and quantification of abdominal aortic aneurysms (AAAs). The condition, which leads to more than 10,000 deaths per year in the United States, is asymptomatic, often detected incidentally, and often missed by radiologists. Our model architecture is a modified 3D U-Net combined with ellipse fitting that performs aorta segmentation and AAA detection. The study uses 321 abdominal-pelvic CT examinations performed by Massachusetts General Hospital Department of Radiology for training and validation. The model is then further tested for generalizability on a separate set of 57 examinations with differing patient demographics and acquisition characteristics than the original dataset. DeepAAA achieves high performance on both sets of data (sensitivity/specificity 0.91/0.95 and 0.85 / 1.0 respectively), on contrast and non-contrast CT scans and works with image volumes with varying numbers of images. We find that DeepAAA exceeds literature-reported performance of radiologists on incidental AAA detection. It is expected that the model can serve as an effective background detector in routine CT examinations to prevent incidental AAAs from being missed.